
Data is everywhere in an organization, from large systems to departmental databases and spreadsheets. No one can control all of it since it spans across a wide range. If the data is not clean, current, and consistent, an organization may get into trouble. This makes data architecture important. But what really is data architecture?
What is data architecture?
Data architecture is essentially a framework that helps you understand how an IT infrastructure supports an organization’s data strategy. It is a process of standardizing how an organization collects, stores, transforms, distributes, manages, and uses data. The end-goal of data architecture is to deliver relevant data so that stakeholders can leverage it to make strategic decisions and enhance business processes.
Before we discuss any further let me first tell you about the various components of Data Architecture.

Learn more about our secure, on-demand data engineering services that help you manage data, design systems, and achieve business success.
Components of Data Architecture
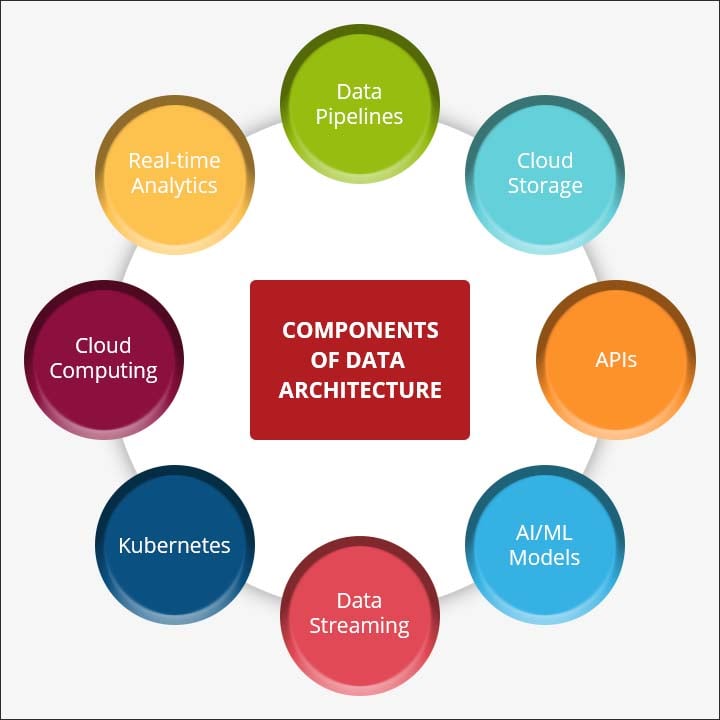
- Data Pipelines
As the name suggests, data pipeline is an end-to-end process where data can move from one source to another and get stored, used for analysis, and combine with other data types as well.
- Cloud Storage
Cloud offers a unique way to back up data, save it online securely so that it can be accessed anytime, anywhere, and anyplace. It can also be shared very easily once permission is granted.
- APIs
Application Programming Interface (API) is a connection built between computers or between different computer programs, essentially allowing applications to talk to each other.
- AI/ML Models
AI/ML models facilitate faster data-driven decision-making sans human intervention. Basically, they are mathematical algorithms that are trained by using data and human experts.
- Data Streaming
Just like data pipeline, data streaming is also used to transfer data. However, data streaming only transfers streams of data from one place to another.
It is a portable, open-source platform in the form of building blocks, which provides mechanisms that can maintain, deploy, and scale data.
- Cloud Computing
Cloud computing is a process which makes use of a system of remote servers to deliver different types of services by using the internet as its medium.
- Real-time Analytics
Once any data enters the database, it needs to be measured. This process of measuring and studying data to derive insights as and when it enters the database is known as real-time analytics.
Now that you know about the various components let’s discuss the processes involved in the standardization of data architecture.
Process behind Data Architecture standardization
There are various processes which ensure the standardization of datasets collected, organized, integrated, and maintained. Here are some of those:
- Manipulation and handling of data entities
Data entity is specifically designed by breaking down larger parts of data into smaller parts. These are useful in representing data relationships. Manipulation of data entities entails a process which defines how you create, where you store, transport, and then report data entities. Tables, models, and procedures are various examples of data entities.
- Data governance policy
Any data architecture policy must have a standard process for data collection, transformation, storage, and consumption and a policy to control information access. There are various other policies like data quality management, data standards, and processes policies that should be a part of this policy.
- Procedure for data infrastructure acquisition
Any data infrastructure that must be used for building an efficient data structure must be within budget and should meet the organization’s needs. They should also ensure the efficiency in the organization’s data architecture. Some examples of these data infrastructures are database servers and network systems.
- Data integration and support
Since data is collected from various sources it becomes important to combine it effectively. This is done by the process of data integration. And at the end it is important to handle these datasets properly with the technologies used for building the data architecture. This can be done by providing training support to your staff.
Now that we’re acquainted with what goes on behind the standardization of data architectures, let’s look at the technologies used in it.
Technologies used for implementing data architecture
Technology, just like in any other implementation, is a vital component in building an efficient data architecture. While implementing data architecture the technology required and the data infrastructure will vary according to the needs of the organization.
The various infrastructures consist of the following components:
- Data warehouse
This is the central repository that encompasses all the databases, business intelligence (BI), analytics, and reporting tools.
- Databases
A database, in simple terms, is a vast collection of data. It can be either relational or non-relational (SQL vs. NoSQL).
- Relational (SQL) databases: These are known for storing structures data in tables. This data is organized properly in rows and columns. Microsoft SQL Server, Oracle DB and MySQL Server are some examples of SQL Databases.
- Non-relational (NoSQL) databases: These also store data but in semi-structured or unstructured data. Datasets in these databases can be manipulated by using programming languages. MongoDB and Cassandra DB are a few examples of NoSQL databases.
- ETL tools
ETL stands for “Extract, Transform, Load.” These tools collect and refine data from various sources and then deliver them to the data warehouse in three stages.
- First, you must extract data from various sources.
- In the transform stage, the data undergoes various sub-processes that include data cleaning, standardization, verification, and quality management.
- The last step is to load the transformed datasets to the repository. Some of the examples of the best ETL tools are Microsoft SQL Server Integration Services (SSIS) and Panoply.
- Data modeling tools
Database structures are created from diagrams by using these software applications, known as Data Modeling tools. These tools are used to define data flow and relationships and they make it easy to form perfect data structures. They help the users create business specific diagrams, data flowcharts and infographics. Some examples of data modeling tools are Future Selection Toolbox, Database Workbench, Bizz design Architect etc.
- Data analytics, visualization, and reporting tools
These tools are suitable for gaining insights from datasets by using visuals such as charts, maps, and tables. These tools are mostly used by data analysts to create dashboards and reports to help management make informed decisions. Some good data visualization tools are Microsoft Power BI, Tableau, and QlikView.
Data Architecture best practices
It is important to build an efficient data architecture. Given below are some of the best practices you can make use of to build one:
- Ensure that data exists in central repository and not in silos: The goal of creating a data architecture is to make sure that there is a flow of information between the datasets, and they remain in the central repository.
- Standardize data entity creation: Always make use of the highest standards available while building any data architecture.
- Create a data architecture document: Always create a data architecture document and have a compliance team to review this document regularly to keep it up to date.
- Make data structures consistent: All the data in the repository should be consistent with data visualization and reporting requirements.
- Automate the ETL process: Automate the loading of data into the data warehouse when you automate the ETL process.
- Use entity-relationship diagrams (ERDs): ERDs help you create and understand the relationships between data entities and thus are an important part of the standard procedure for datasets in relational databases.
- Update data architecture and ERDs: It is important to be sure that whenever a data entity is created, the existing data architecture for the same should be updated.
A shift from ancient to modern: Things to keep in mind
The various technical points that need to be considered while modernizing data architecture vary from having different data lakes to having various customer analytics platforms, as well as from having different infrastructures for building data architectures to having different tools for data stream processing.
All of these increase the complexity of data architecture and are also responsible for hampering an organization’s ability to deliver new capabilities, ensure the integrity of Artificial Intelligence and maintain the existing infrastructures.
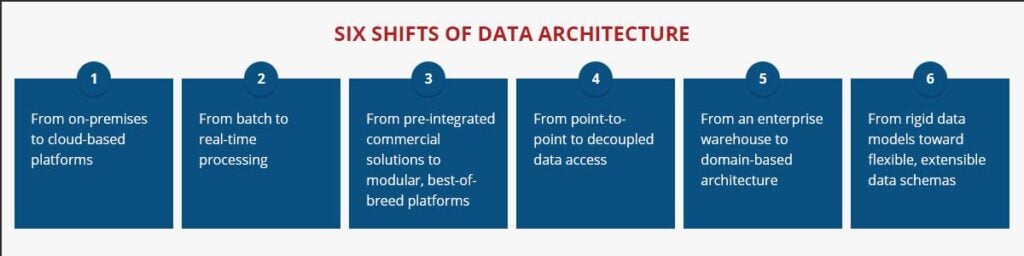
A recent article by McKinsey shed light on six significant shifts that should be considered while building a data architecture in today’s world and highlights how the older architectural components has been updated to the distributed, agile architecture for today’s companies. These six foundational shifts nearly touch all data activities, processing, storage, exposure and analysis. All these shifts make the rapid delivery of new capabilities vastly simplifying.
Six shifts to keep in mind while building Data Architecture
Benefits of Building a Modern Data Architecture
Various data architectures have dominated the IT infrastructure in the past. These are now no longer capable of the huge workloads of today’s enterprises. The various advantages of modern data architecture are as follows:
- Take a Centralized Approach to Integration
Integration of data fed into depositories from various sources has always been challenging. Thus, having a centralized view of the data makes it easy for the user to configure and manage the data.
- Remove the Latency from Hybrid Environments
Studies show that the value of operational data drops by 50% after about 8 hours. Replication of this data from one place to another increases the latency in the process. There are many functions like inventory stocking, improvement of customer service etc. that need to be handled in real time.
This ensures that the data is available throughout the enterprise and the users have easy access to it.
- Automate Data Delivery and Create of Data Warehouses and Marts
Automating the creation of function-specific warehouses and marts is an essential step after data ingestion and creation of analytics.
After the automation of data warehouse is in place, creation and updating of data marts becomes easier. All this eventually leads to reduction of risk in a project and increase in agility.
This journey from ancient architecture to the successful implementation of modern data architecture is complicated and long. However, with all the different principles and frameworks that we’ve seen, it surely can be achieved.
Data will undoubtedly be the future of computing and a way of life for businesses to function. It is crucial that we have an efficient data architecture for organizational success and knowing about all the above principles beforehand would be a plus point while building one.
If you are planning to build a data architecture for your enterprise, reach out to us at Nitor Infotech.



