The popularity of AI and ML is increasing. So, business owners are trying to build various use cases and getting machine learning models in production. Businesses tend to include the technology in their process rather than focusing the impact on the profit.
This approach is best when one wants to introduce the latest technologies in the products. After a lot of research and collaboration with different stakeholders data scientists develop a product and make the ML models go live.
Creating such products involves a great understanding of:
- underlying business,
- data gathering,
- data storage,
- what to predict or classify,
- data cleaning,
- data transform,
- applying different ML models,
- hyperparameter tuning,
- validating results,
- deploying
After deployment comes the very important part which is ML Ops. ML Ops is a set of practices that aims to deploy and maintain ML models in production reliably and efficiently.
In this blog, we are going to dive into the model monitoring part of ML Ops and model retraining or incremental learning. There are various tools which can be used in real time production to perform such tasks which uses different methods for the same. We are going to see some common statistical approaches for monitoring and understand the need for retraining.
Model monitoring is the process of regularly evaluating the performance of a machine learning model in production. This is important because machine learning models are often deployed in real-world environments where the data they encounter may differ from the data they were trained on. This leads to degradation of performance over time.
Model monitoring allows organizations to detect and address this degradation in performance before it becomes a major problem.
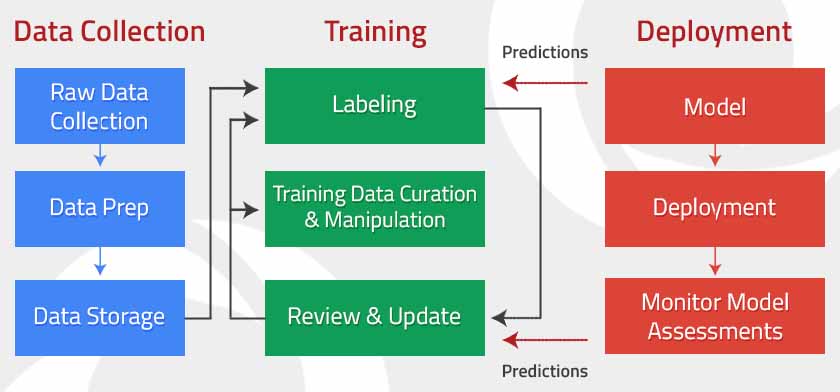
There are several key components to effective model monitoring:
Metrics: The first step in model monitoring is to define a set of metrics that will be used to check the performance of the model. These metrics should be chosen carefully, as they will be used to determine whether the model is performing as expected or if there are any issues that need to be addressed. Some common metrics for evaluating the performance of machine learning models include accuracy, precision, recall, and F1 score.
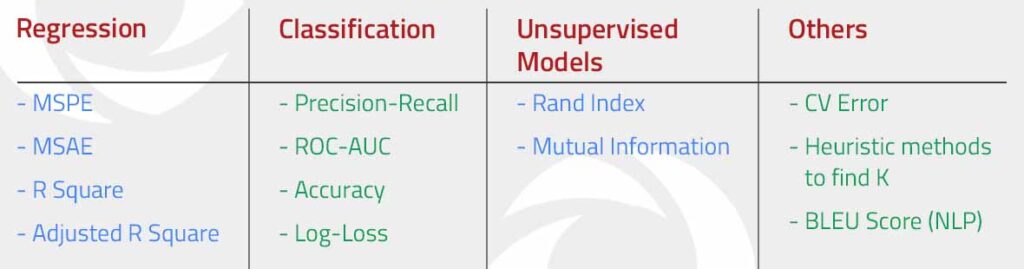
Data collection: To check the performance of a machine learning model, data must be collected on how the model is performing in production. This can be done through a variety of methods, such as logging predictions made by the model or using a monitoring tool to track the model’s performance over time.
Data analysis: Once data has been collected on the model’s performance, it must be analysed to determine if there are any issues that need to be addressed. This can be done manually, or with automated tools that can alert an organization if certain thresholds are exceeded.
There are mainly two ways by which a model performance drops and does not generate real value:
- Data Drift
- Concept Drift
What is Data Drift?
Data drift is a phenomenon where the data that was used to train an ML model does not mimic the test data, or the data received in production. When I say ‘mimic’, it simply means that the data received in production must have equivalent statistical properties of training data.
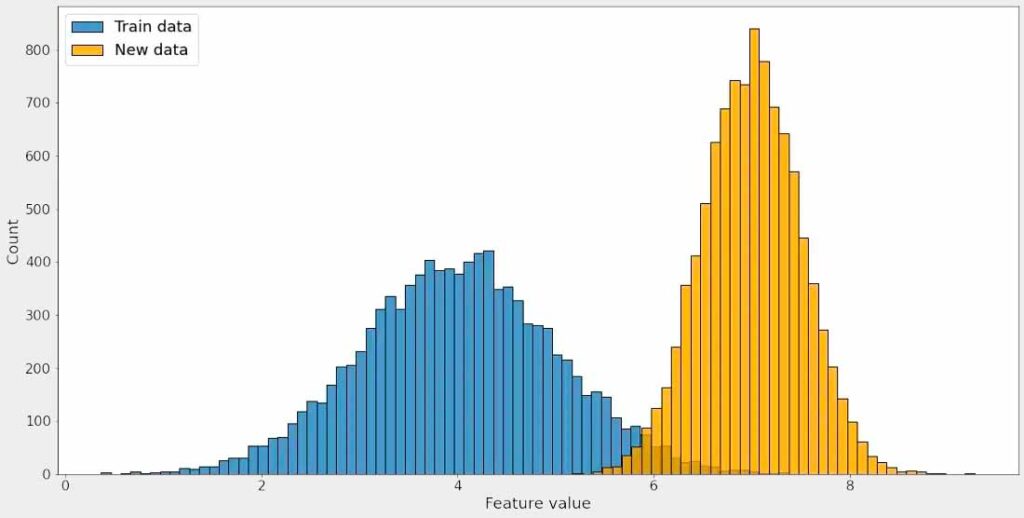
Why does it occur?
1. Changes in the underlying system being modelled: For example, a model is trained to predict traffic patterns on a highway. It may see change in the data if there are new construction projects that are affecting the flow and making people deviate from their routes.
2. Changes in data collection process: For example, if an ML model is trained on a set of data collected using a certain type of sensor, and then used to make predictions on data collected using a different type of sensor.
3. Changes in the environment in which the data is collected: For example, if an ML model is trained to predict weather, it may see a change in the data if there are changes in the climate or in the geographical location being modelled.
4. Change in the data distribution: Suppose we have trained a model on predicting health score of population aged above 60. This model is used to predict health score of people below the age of 25. There is a change in population which affects the model performance.
Types of Data Drift
There are mainly two types of data drifts which are as follows:
Covariate Shift: If the distribution of input feature changes, but the output variable remains the same. A simple example could be if a model is trained on predicting the price of a house based on its location, size and age, covariate shift may occur if the distribution of house sizes or ages changes over time, but overall demand of the houses remain the same.
Prior Probability Shift: Distribution of target variable changes. For example, during Covid times, some people’s incomes were not affected but they decided to not pay their EMI and take advantage of some government schemes. Maybe they did this to save money in case the condition worsened but (income = input variable not changed but output = EMI have changed)
What is Concept Drift?
As the name suggests, the very concept or underlying situation on which the model was trained changes significantly. In simple words, it can also be defined as the combination of covariate shift and prior probability shift.
Imagine you have a machine learning model that is trained to predict the sales of a particular product based on various features such as the product’s price, the store it is sold in, and the season. The model is trained on sales data from the past few years and performs well on the test set.
However, over time, both the input features and the output variable change. For example, the price of the product may increase, the store may start selling the product in a different location, the season may change, and the overall demand for the product may vary. These changes in both the input features and the output variable (sales of the product) would be considered concept drift.
How to overcome drifts:
There are several strategies that you can use to overcome data drift:

- Monitor your data: Regularly monitor the statistical properties of your data and look for signs of drift. This can help you identify when drift is occurring and take corrective action before it affects the performance of your model.
- Use adaptive models: Some machine learning models such as online learning algorithms, are designed to adapt to changes in the data distribution over time. These models can be trained on a continuous stream of data and automatically update their internal parameters as the data distribution changes.
- Use data augmentation: Data augmentation involves generating additional synthetic data that is like your existing data, but with slightly different characteristics. This can help your model learn to generalize better and be more robust to data drift.
- Retrain your model: If you detect significant data drift, you may need to retrain your model on a new, updated data set. This can help ensure that your model is able to accurately make predictions on the current data distribution.
- Use domain knowledge: If you have domain knowledge about the data you are working with, you can use this knowledge to anticipate and mitigate data drift. For example, if you know that certain factors are likely to change over time (e.g., demographics and economic indicators), you can incorporate this information into your model to make it more robust to drift.
Well, this blog has been an introduction to model monitoring and its types with many examples and how it is a serious concern. We’ve also looked at retraining. Read my next blog in this machine learning models series, wherein we will look at some statistical approaches for detecting the drifts in data as well as methods to overcome such situations.

Transform your business into a fortress of security with AI/ML.
Send us an email at Nitor Infotech with your comments or if you’d like to discover details about our AI & ML capabilities.



