In the first part of this series, I introduced you to the monitoring of machine learning models, its types, and real-world examples of each one of those. You can read Part 1 here.
In this blog, let’s look at methods to identify these drifts. Concept drift is more related to the real-world scenarios and business changes. So we will focus on detecting the data drift which only requires a detailed analysis of data we receive at production and training data.
One way to identify data drift is to use statistical tests to compare the distribution of the training data with the distribution of the new data. If the two distributions are significantly different, it is likely that data drift has occurred.
Hypothesis testing needs to be performed on the data. Hypothesis testing is a statistical procedure used to determine whether a hypothesis about a population parameter is true or false, based on sample data.
It involves stating a null hypothesis, which is a statement of no statistical significance between two groups or variables, and an alternative hypothesis, which is a statement of statistical significance between the groups or variables. The null hypothesis is assumed to be true unless the evidence in the sample data is strong enough to reject it in favour of the alternative hypothesis.
We must perform hypothesis tests to check the p value and bring the conclusion of whether to reject the null hypothesis or not. For numerical features, the most practiced test is the Kolmogorov-Smirnov(K-S) Test. Let’s take a closer look at it!
Kolmogorov-Smirnov(K-S) Test
- KS Test compares the cumulative distribution function of the two data sets first is used while training the model and another is real time data collected over a time.
- The Null Hypothesis is that both distributions are identical, and the Alternate Hypothesis is they are not identical. If the P value is less than significance level, then we reject the null hypothesis and say that there is a data drift.
- Let us see with an example implemented using Python.
Let us take a use case where we want to predict whether a particular product will be delivered on time or not. We have past data about products and labels as reached on time or not which is a binary target. The data contains a lot of features like weight of product, product rating, warehouse block, prior purchases, and product importance. Let’s call it df and check.
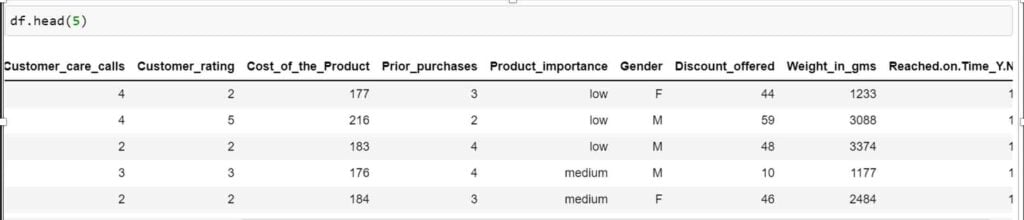
The datasets look as shown in the above image. Now for the sake of the experiment, I will divide the data in data_1 and data_2 in equal proportions. Both these datasets come from the same source and have not been manipulated, yet they will be identical. To run the test, we need to identify which columns are numeric in nature and make a list for future use.

Suppose we train a classification model using data_1. Now I will generate a copy of data_2 by increasing the cost of product by 30% to 80% and name the dataset as data_2_future, assume that this is future data. It means data_2_future is the production data. To run the test on all data, we can directly use Python or R which offers some built-in functionalities. I have run these tests using Python. After running the test, I stored the results in data frames, which looks like this:
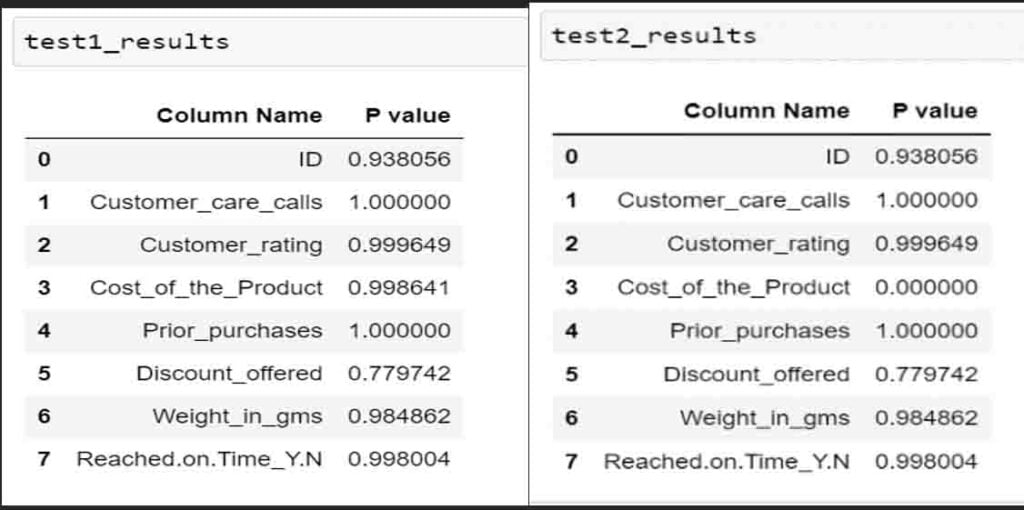
So, if the cost of the product is more in real-time data compare to data which was used to train the model, the data drift occurs. test1 results showcase the comparison of data_1 and data_2 and P values of all numerical columns whereas data_2_future is compared with data_1 in test2 results. The P value of Cost_of_the_product column is almost 0 in second test which is less than significance level that is 0.05. So, the column is rejected and the alternate hypothesis is true for the column.

As discussed, KS tests compare Cumulative Distribution Function (CDF). The first graph shows overlap of blue and green lines because they are identical and drawn from the same population whereas in the second graph there is clear distinction of distributions (blue line shows cdf of data_1 and green line is cdf of data_2_future). This is a sign of data drift. There can be many columns in a dataset for which drift can occur. We need to check for each one of them.
Now allow me to introduce you to the chi-square test.
Chi-Square Test
The chi-square test is a commonly used statistical test, and it is particularly useful for detecting changes in the distribution of a categorical dataset.
It is used to determine whether there is a significant difference between observed and expected frequencies in a dataset. It is often used to detect whether there has been a change in the distribution of a dataset. Or it is used to compare the distribution of a dataset to a hypothesized distribution.
Let us take the same use case and perform the test on categorical columns.

There are some warehouse block categories in data which includes ‘A’,’D’ etc just like in above example. I will tweak the data to make it different from training data this time by increasing the percentage of “D” block by 75% . This way the distribution of categories changes significantly.

After generating future data, I will now run the chi-square test using Python as follows and print the results.
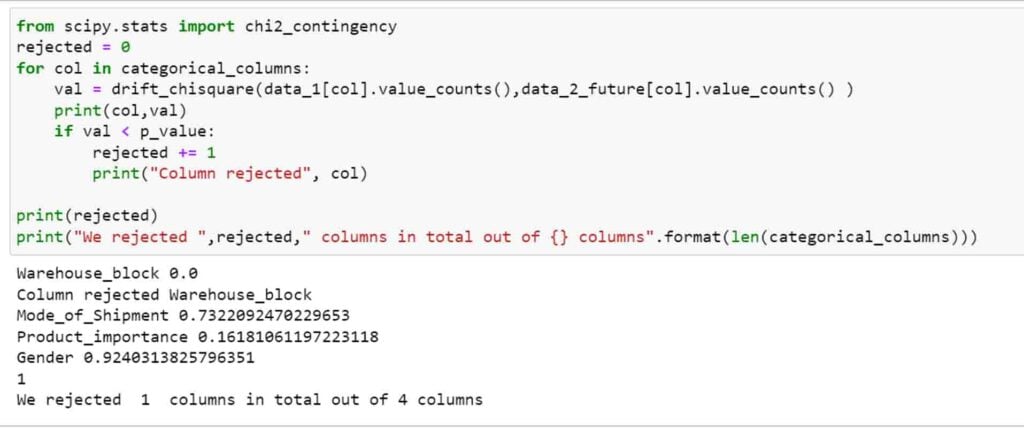
As we can see, p-value of warehouse_block column in 0 which is less than 0.005 the column is rejected. Likewise, after running this test, changes in data distribution of categorical columns can be detected easily and can do the further needed.
We have seen an example of hypothesis testing to detect data drift for numerical columns as well as categorical columns. Similarly, there are many other tests which can be performed like Cramér-von Mises test, Anderson-Darling test, and Friedman test. Once the drift is detected, it can be overcome by many techniques and we have seen those in my previous blog. One of the methods was incremental learning and retraining. We will see how to do that using some Python code.
Now that you are well acquainted with hypothesis tests, let me explain what incremental learning is about.
Incremental Learning
Incremental learning is a learning approach in which new information is continually added to a model, rather than starting from scratch each time. In incremental learning, the model can retain previously learned information while learning new information. This allows it to build upon and improve its existing knowledge over time.
There are several benefits to using incremental learning, including:
- It allows the model to learn and adapt to new data without forgetting previously learned information.
- It can be more efficient since it does not require the model to re-learn previously learned information each time.
- It can be more effective since the model is able to build upon and integrate its existing knowledge with new information.
Using Scikit Learn
To perform incremental learning in scikit learn, we have an option of using partial_fit API. It has ability to get trained on a batch of a dataset. This can also be utilised when the whole dataset cannot be loaded in RAM. This API is available for Stochastic Gradient Descent (SGD). Let me walk you through some code examples.

Here, first sgd is trained on a classification problem of credit card fraud in batches after processing data through a function preprocess_batch(). After training, the model is saved using joblib for future use. Once the new data comes into the picture, we take the earlier model and incrementally train it on a new dataset.
Using Pyspark
Pyspark is widely used for ML projects these days and it is very important to know how IL is performed in it. This is because Spark is generally used for streaming data or big volume data. Let us go through a code example.
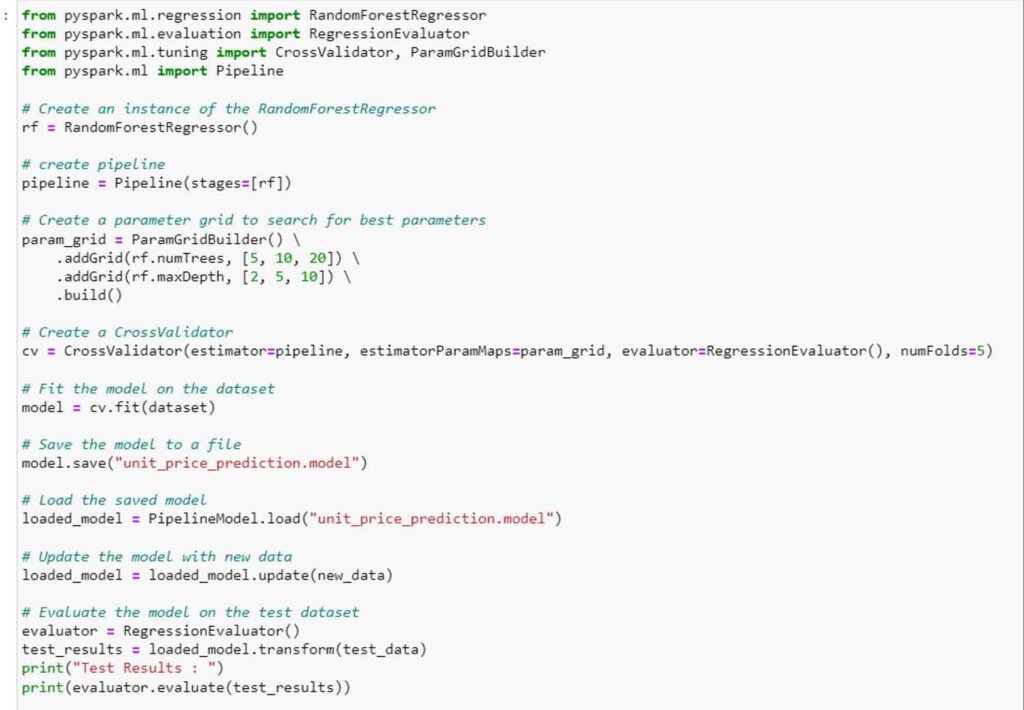
Here we have used a random forest regressor from PySpark API to train a regression model for unit price prediction by creating a pipeline and training saved a model. Using update function on top of loaded model and by-passing new data, we can get an updated version of the model. This can then can be tested on real data.
There are some libraries like River which offer great flexibility on different algorithms like ISVM and iPerceptron which can be utilised from the start of the project. LightGBM also provides an option for the same. The functions are similar in these libraries. One can choose based on the requirements.
PySpark is best suited for distributed and large-scale machine learning tasks. Scikit-learn is best for small and medium size data and common machine learning tasks. River is the best for incremental and online learning tasks. LightGBM is the best for large and high-dimensional data as well as fast and efficient incremental learning.
Well, it’s time for me to wrap up my ideas! In today’s blog, we have taken a close look at statistical methods for detecting data drift. We have also looked at some code examples of incremental learning using different options and summarized different usages for different purposes! I hope you enjoyed the read.

Secure the future of your business with the advantage of AI/ML.
Send us an email at Nitor Infotech with your thoughts about this blog or if you’d like to learn about our AI & ML offerings.



