
Highlights
This blog highlights context engineering as the operating system of agentic LLMs. It explains how managing instructions, memory, tools, and knowledge within limited context windows improves reasoning and reduces failures. With the four pillars – write, select, compress, isolate – you’ll learn how to build scalable and reliable AI agents. It also highlights observability, transparency, and real-world pitfalls to help teams design trustworthy, context-driven products for modern workflows, autonomous systems, and seamless deployments in today’s AI landscape and beyond.
The evolution of large language models (LLMs) has entered a new phase — the age of agents. These systems no longer just generate text; they reason, plan, call tools, retrieve data, and maintain context across steps. As this shift unfolds, one truth has become evident: in the world of agentic AI, context is everything.
Wondering what that is? Well, just as an operating system manages memory, modern LLM systems manage context.
In this blog, you’ll discover everything you need to know about context engineering, including its practical applications and architectural considerations. By exploring these concepts, you’ll be equipped to develop more effective agentic LLM systems. This will ultimately lead to improved workflows and products.
What is Context Engineering for Agentic LLM Systems?
As Andrej Karpathy, a Slovak-Canadian computer scientist and co-founder of OpenAI, puts it, LLMs are like a new kind of operating system. That is, LLM is like the CPU, and its context window is like the RAM, serving as the model’s working memory. The size, relevance, and organization of that context directly influence accuracy, efficiency, and reliability. A great AI model with poor context management can hallucinate, drift, or simply collapse under its own token weight.
Karpathy frames it as the “delicate art and science of filling the context window with just the right information for the next step.” This only means that the emerging discipline is about mastering how information enters, persists, and evolves inside and around the model.
Note: You must not confuse context with prompt engineering.
While “prompt engineering” is focused on crafting the right instructions for an LLM, “context engineering” goes further — it’s about filling the context window with the most relevant information from any source: retrieved documents, tool outputs, past interactions, or external systems.
However, the significance of context engineering is not an overnight story. AI systems are undergoing a significant transformation as organizations have started to leverage their insights to guide models in generating the desired outputs.
Let’s understand the shift!
How is AI shifting toward Context-Centric Systems?
When large language models first arrived, their power seemed limitless. However, developers quickly learned that model quality alone isn’t enough. A 70-billion-parameter model can still produce garbage if it’s given the wrong 2,000 tokens of context.
As models started acting like agents, reading documents, querying APIs, and maintaining conversation state, the context window became both a bottleneck and a frontier. Every agent interaction is a competition for context: prompts, retrieved data, user input, tool output, and previous steps all fight for space inside a limited token budget.
This creates a fresh system design challenge. It’s not only about what the model knows but how it accesses, organizes, and evolves that knowledge in context.
This is the essence of context engineering – designing how information flows into and out of the model’s short-term “RAM” while preserving what matters most for reasoning.
Head over to the next section to understand the structure and pillars of context engineering.
How Is Context Structured in Agentic LLM Systems?
To learn about context engineering better, you need to understand its structure. In an agentic workflow, context typically consists of:
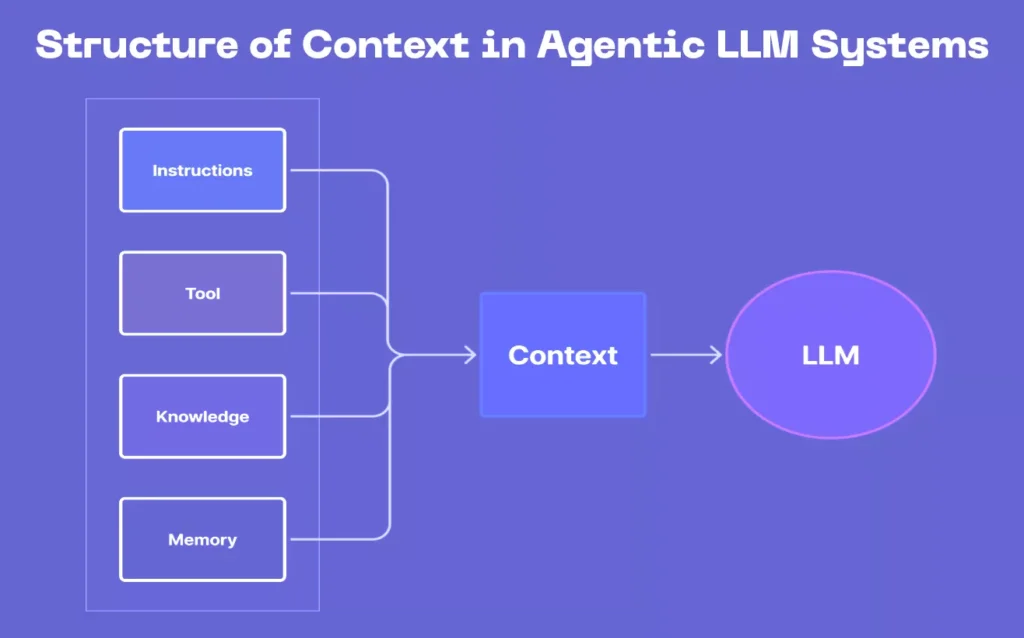
Fig: Structure of Context in Agentic LLM Systems
1. Instructions: The “rules of behavior” or goals for the model.
2. Knowledge: External information that the model must use. As in, those retrieved from documents, databases, or APIs.
3. Memory: A representation of past interactions, outcomes, or user preferences.
4. Tool: Observations or results from tool or function calls.
All these pieces merge into one prompt, but not all are equal. Some are persistent (long-term memory, like user history), while others are transient (like short-lived observations). The challenge is to dynamically balance them, ensuring that the model always understands what it needs.
That balance between these pieces of the puzzle defines an agent’s intelligence.
Before I highlight core pillars, it is necessary to comprehend two key concepts: the reasons for which long contexts fail most of the time and the cases when they are successful.
Why Do Long Contexts Sometimes Fail in Agentic LLM Systems?
Despite the promise of million-token context windows, longer contexts do not automatically generate better responses. In fact, overloading context can cause AI agents to fail in surprising ways.
Drew Breunig, a famous strategist who believes in harnessing data to make the world a better place, has identified four primary failure modes:
1. Context Poisoning: When a hallucination or error makes it into the context and is repeatedly referenced.
For example, Google DeepMind’s Gemini 2.5 technical report documented an issue in their Pokémon-playing agent, where the model would hallucinate game states and develop “impossible or irrelevant goals” based on this misinformation. Once such errors occur, they can compound over time.
2. Context Distraction: When accumulated context grows so large that the model over-focuses on it rather than applying what it learned during training.
The same Gemini agent displayed a tendency to repeat past actions from its extensive history rather than synthesizing novel plans when context exceeded 100k tokens.
Another Databricks study found that even Llama 3.1 405b began showing degraded correctness around 32k tokens.
3. Context Confusion: When superfluous content in the context produces low-quality responses.
For example, the Berkeley Function-Calling Leaderboard demonstrates that every model performs worse when provided with too many tools, even when context limits aren’t reached.
So, if you provide information, the model must pay attention to it, whether relevant or not.
4. Context Clash: When information from different sources contradicts itself within the same context.
For example, a Microsoft and Salesforce study found that when prompts were “sharded” across multiple turns, simulating how AI agents gather information incrementally, model performance dropped by an average of 39%. Even OpenAI’s o3 dropped from 98.1% to 64.1% accuracy.
The reason: early incorrect attempts remain in context and poison later reasoning.
These failures hit agents the hardest because agents operate precisely in scenarios where contexts balloon: gathering information from multiple sources, making sequential tool calls, and accumulating extensive histories.

Turn AI buzzwords into real product impact with intelligence. Build smarter, ship faster, and scale better.
Note: Context failures aren’t the only outcome; long contexts can also produce remarkable results. Keep reading to explore this further.
When Do Long Contexts Improve Agentic LLM Performance?
It’s important to note that long context windows aren’t inherently problematic — they simply require careful management.
Here are the scenarios where large contexts excel:
1. Summarization: When the task is to distill large volumes of information into concise insights, long contexts allow models to see the full picture without pre-filtering.
2. Fact Retrieval: When searching for specific information across documents, having everything in context can be more reliable than pre-selecting fragments.
3. The key distinction: Long context works well for retrieval and summarization tasks. It struggles with multi-step generative reasoning, where accumulated context can distract or confuse rather than inform. If AI models start to misbehave long before their context windows are filled, as the Databricks study showed around 32k tokens, the issue isn’t capacity but context quality.
This is why context engineering matters. So, the goal isn’t to avoid long contexts but to ensure every token in that context serves the task at hand.
To help you crack the context engineering code, next, I’ve highlighted four important pillars that you need to know about. Keep going!
What Are the Four Pillars of Context Engineering?
The practice of context engineering can be divided into four interlocking operations:
- Write
- Select
- Compress
- Isolate
Each one shapes how information survives, travels, or gets replaced during an agent’s reasoning cycle.

Fig: Four Pillars of Context Engineering
Here’s a visual representation of the four pillars of context engineering:
1. Write: Capturing and Persisting Information
Without persistence, valuable intermediate data vanishes when the token window resets.
Writing takes two forms:
1.1. Scratchpads:
When we solve tasks, we often take notes and try to remember key details for future related tasks. Similarly, note-taking via a “scratchpad” is a way for an agent to persist information while performing a task. The idea is to store information outside the context window so that it remains available to the agent. This can be implemented through a tool call that writes to a file or to a field in a runtime state object that persists during the session.
1.2. Memories:
Sometimes agents benefit from remembering things across many sessions. An LLM can be used to update or create memories. For example, ChatGPT, Cursor, and Windsurf can auto-generate semantic memories (facts), procedural memories (instructions), and episodic memories (examples) that last indefinitely.
So, never waste context that you can store.
2. Select: Retrieving the Right Context at the Right Time
If “write” creates memory, “select” decides what comes back. Each type of stored information demands its own retrieval strategy, such as:
2.1. Scratchpad: Selecting context from a scratchpad depends on how it’s implemented. If it’s designed as a tool, the agent can simply read from it through a tool call. But if it’s part of the agent’s runtime state, developers can decide which parts of that state to expose at each step.
2.2. Memories: When it comes to memories, AI agents need to pull only what’s relevant to the task, like past behavior, step-by-step instructions, or useful facts. But as memory collections grow, picking the right information gets tricky. Many systems rely on embeddings or knowledge graphs to index and retrieve the most relevant pieces.
2.3. Tools: When agents are given too many tool descriptions, they can easily get confused. Using RAG to pull in only the most relevant tools for each task helps simplify choices and boost accuracy.
2.4. Knowledge: Code agents are some of the best examples of RAG in large-scale production. However, embedding search becomes unreliable as codebases grow. Using Windsurf can help overcome this by combining AST parsing, semantic chunking, grep/file search, knowledge graph retrieval, and re-ranking to surface the most relevant context efficiently.
3. Compress: Reducing Context Without Losing Meaning
Even with retrieval, the token window is finite. Compression preserves the signal while reducing the size through two main strategies:
3.1 Summarization: It’s a key method for handling long interactions between agents that use many steps or large tool outputs. For example, Claude Code automatically runs “auto-compact” when 95% of the context window is filled. This way, it summarizes the entire user-agent conversation.
Summarization can also be applied at specific points in an agent’s workflow. For example, to reduce token load after large tool outputs, like token-heavy search tool or at an agent-to-agent boundaries to simplify knowledge transfer. The challenge lies in ensuring that important events or decisions are not lost during compression.
3.2. Trimming: This refers to filtering via hardcoding, like removing older messages, without using an LLM.
The balance has to be delicate: compress too little wastes tokens; compress too much loses reasoning anchors.
4. Isolate: Isolating context to split across sub-agents
OpenAI’s Swarm and Anthropic’s multi-agent researcher use isolation for the separation of concerns. Anthropic found parallel subagents outperformed single-agent approaches but required 15× more tokens and significant coordination complexity.
Claude Code takes a conservative approach. That is, subtask agents only answer questions, never write code in parallel to avoid conflicts.
The critical failure point: Parallel agents working on interdependent tasks may create conflicting assumptions and unreliable results. In contrast, single-threaded architectures with context compression remain more reliable until agents communicate better.
Onwards to learn about the best practices – observability and transparency.
How Can Observability and Transparency Improve Context-driven Agentic LLM Systems?
The straightforward answer to building trust in agentic LLM systems is through continuous monitoring of contexts that are being fed to the models.
For example, LangSmith and similar platforms enable tracing of context flows across agent trajectories, helping identify when the four failure modes emerge and whether engineering techniques actually improve performance.
Transparency is equally critical. Here’s a real-world example highlighting its importance:
Simon Willison, a British programmer, shared a case where ChatGPT remembered his location and used it in a picture he asked for. He felt that the model’s context was beyond his control because the model seemed to have knowledge that it didn’t have. When agents become capable of handling their own memories, it becomes very important to let the users know what the model “knows” at each step to be able to keep trust and control. This can be done by using logs, dashboards, or interface panels.
To secure your agentic AI-based journey, I’ve further listed a few pitfalls that you need to be aware of while dealing with contexts.
What are the Most Common Pitfalls in Context Engineering that You Need to Avoid?
Context engineering is all about steering clear of traps. Here are the four most common pitfalls that you need to be aware of:
- Over-stuffed prompts confuse the model: If an AI model considers everything that is given to it, its performance may degrade even if the capacity is not exceeded.
- Unbounded growth confuses the model: AI models may start to repeat the patterns that they have used before instead of coming up with new ones.
- Circular context causes the model to be poisoned: When the model is given its own past output without abstraction, early errors may accumulate, and the model may consider them as “facts”.
- Parallel agents without shared context breach the Principles of Cognition: If agents run without sharing the full trace, different implicit decisions and context clash may occur due to conflicting traces.
In short, large language models have transformed building products into a form of reasoning. Meaning, as AI agents become more autonomous, the challenge has shifted from training intelligence to organizing intelligence.
That’s where context engineering plays its part: managing the model’s attention as a finite resource to be structured and optimized. It’s about anticipating what can go wrong and designing systems that keep reasoning on track.
The four failure modes – context poisoning, distraction, confusion, and clash, show that reliability isn’t about the size of the context window, but how it’s managed.
Moreover, mastering the four pillars can define how agents think, remember, and collaborate. The better you understand and design for these dynamics, the closer you get to systems that reason, not just respond with purpose, reliability, and coherence.
Now, I trust that you are ready to take the agentic leap and leverage intelligence at every juncture of your business journey. Contact us at Nitor Infotech, an Ascendion company.



