
The discussion of Generative AI marks a pivotal moment for businesses worldwide in today’s dynamic tech world. It has made space for a transformative shift for organizations to stand at the crossroads of unprecedented possibilities. When delving into the realm of GenAI, it is essential not to overlook one of its key potentials—Large Language Models (LLMs).
In simple terms, Large Language Models (LLMs) are powerful AI programs that are trained on vast datasets. They operate on transformer models within neural networks which gives them an edge to excel at tasks like – creating narratives, language translation, and mimicking human-generated content. LLMs represent a future where language manipulation offers diverse and advantageous possibilities.
However, this fascinating prospect is accompanied by a complex and concerning reality. These models’ results can cause hallucinations, biases, and toxicity, posing some serious challenges for businesses.
In this blog, you’ll get to explore the downsides of LLMs—like hallucinations, bias, and toxicity. Further, we’ll dig into their technical origins, understand how they impact the real world, and discuss responsible development practices to steer LLMs toward a positive societal future.
What are Hallucinations, Bias, and Toxicity in LLMs?
Let’s delve into each of the drawbacks one by one:
1. Hallucinations: This refers to the model’s ability to generate fabricated content by blending facts and fiction in its outputs, straying from reality. The problem arises from limitations in training data, the model’s structure, and our incomplete understanding of LLM operations. If not monitored, hallucinations can manipulate information, undermine trust, and present substantial hurdles for applications that depend on the accuracy of LLM outputs.
2. Bias: LLMs might have biases from their training data, showing up in various ways, like spreading stereotypes or worsening social inequalities. Bias in LLM outputs is a major concern with ethical and practical implications, demanding careful consideration for applications in sensitive areas like healthcare, news, and social media filtering.
3. Toxicity: This refers to the potential misuse of language generation, turning models into unwitting sources of hate speech, misinformation, and manipulation. This downside emphasizes the need for strong mitigation strategies and thorough assessment of downstream applications, especially in settings susceptible to online harassment and manipulation.
Take a quick glimpse on table summarizing the concepts discussed above:
| Hallucinations | Bias | Toxicity |
|---|---|---|
| LLMs producing fake information are considered hallucinations. These may contribute to misinformation, distort history, and pose risks in fields like medicine or law. |
Biased LLM outputs promote misinformation and unfair stereotypes, causing harm to marginalized groups and spreading negativity. This scenario, including biased AI hiring, prejudiced news, and hate-spewing chatbots, is something we want to avoid! |
LLMs can generate harmful content like hate speech and misinformation, requiring strict controls. Problematic LLMs can spread hate and lies online overshadowing truth—a scenario to prevent. |
Types of hallucinations:
|
Types of biases:
|
Sources of toxicity:
|
Clear about the basics? Great!
Furthermore, let me help you comprehend the situations in which LLMs experience hallucinations.
Additionally decode and understand the spectrum of LLM in our blog.
When do LLMs Hallucinate the Most?
Here are the situations when LLMs hallucinate the most:
1. Number generation or calculation: Models often hallucinate when generating numerals, such as dates, quantities, and scalars operations, indicating a challenge in accurately representing numerical information, like in the given example.
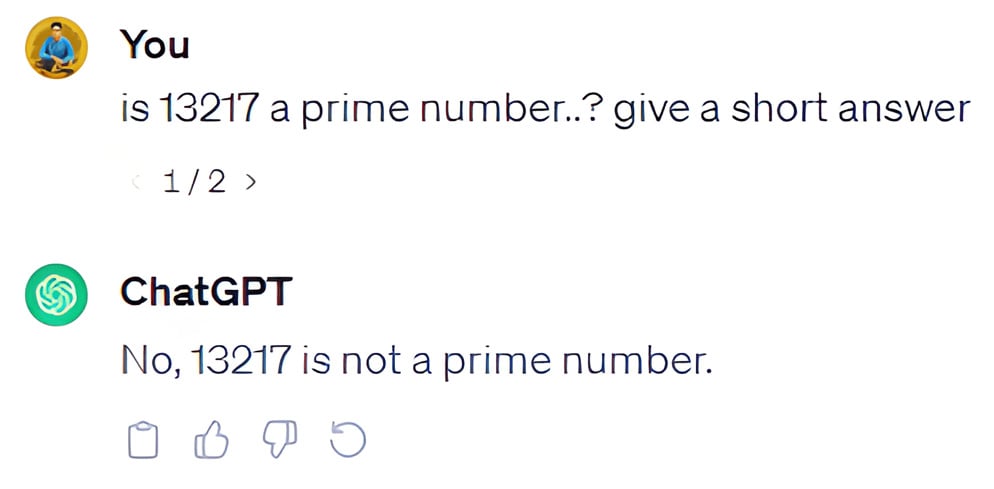
2. Long-range dependencies: Tasks that require understanding long conversations or summarizing documents can make the model create contradictory information. This shows that the model struggles to stay consistent over long sequences.
3. Reasoning challenges: Misunderstanding facts or information within the source text can result in hallucinations and errors, highlighting the importance of robust reasoning capabilities for faithful text generation.
Like for the given example, The correct answer is 21. Although the logic is fine, GPT can’t seem to get to the correct answer:

4. Conflicting knowledge: Models tend to prioritize parametric knowledge acquired during pre-training over contextual knowledge, even when the latter conflicts with the former, leading to potential inaccuracies and hallucinations.
5. False premises: When presented with contexts containing incorrect information or false premises, models often fail to detect these errors and generate outputs that perpetuate the inaccuracies, suggesting a need for enhanced fact-checking mechanisms.
Now that you know when it happens, you might be curious about why. Next, let’s explore the reasons behind these hallucinations.
Keep reading!
Causes of LLM Hallucinations
Hallucinations aren’t just mistakes; they come from the way these models work. Here are some technical details explaining these hallucinations:
1. Imperfections in Training Data: Models learn from various data sources like books and social media, but sometimes this data is incorrect or biased. This can lead the model to make mistakes or show bias in its new content.
2. Uncertainty of Probabilistic Models: Language models like GPTs are good at guessing the next word, but because of randomness, they can give surprising results. This randomness, based on math and statistics, can lead to both sensible and strange guesses happening simultaneously.
3. Absence of a Definitive Ground Truth: Text generation lacks universally accepted answers, making it a breeding ground for hallucinations. Without a definitive guide, the model relies on probabilities, navigating a sea of possibilities.
4. Challenges of Optimization: Teaching a language model is like finding your way through a maze blindfolded, guided only by a ‘score’ indicating performance. If the score doesn’t grasp the complexity of human language, the model might get confused and make things up.
5. Complexity of models: Models like GPT-3 have billions of complex parts, allowing them to perform well but also causing issues. The model may focus too much on unimportant patterns, leading to mistakes and nonsensical language.
Understanding these details is the first step to solving them. In the next part, we’ll explore ways to address these issues, aiming for a future where language models create honest, clear, and factual content.
Methods to curb Hallucinations
Crafting high-quality datasets can help reduce hallucinations in text generation theoretically. However, practical challenges in validating and cleaning massive datasets exist. Alternative solutions include using external knowledge for validation, adjusting decoding strategies, and assessing consistency through sampling multiple outputs.
To give you a clear idea, here are the top 5 ways to prevent hallucinations in LLMs:

I. Active Detection & Mitigation of Hallucinations via External Knowledge Validation
This is an iterative approach to detect and mitigate hallucinations in text generation. It involves generating sentences sequentially and applying detection and mitigation techniques at each step. This is how we do it in 2 steps:
a. Detection:
- Identify potential hallucinations by pinpointing key concepts in the generated sentence.
- Assess model’s uncertainty regarding these concepts using logit output values.
- Validate uncertain concepts (those with low probability scores) by retrieving relevant knowledge.
b. Mitigation:
- Repair the hallucinated sentence using retrieved knowledge as evidence.
- Add the fixed sentence to the input and keep generating to avoid spreading hallucinations.
II. SelfCheckGPT
SelfCheckGPT uses the idea that responses from a grounded knowledge base should be consistent, while those with hallucinations tend to differ. It samples multiple responses from a model using different temperature settings and checks information consistency to distinguish between factual and hallucinated statements. You can assess information consistency using measures like BERT-Score or IE/QA-based methods.
III. Factual Nucleus Sampling
This method argues that increasing randomness (“nucleus p”) in latter parts of generated sentences harms factuality compared to the beginning. As more information is gathered, the number of accurate word choices decreases, requiring a flexible approach.
It proposes factual-nucleus sampling, where nucleus probability (pt) for word t within a sentence decreases with a decay factor (λ) while being bounded by a lower limit (ω). This dynamically adjusts randomness based on generation progress, potentially improving factuality.
IV. Model Configuration
Model configuration and behavior play a crucial role in shaping the output of text generation models. Key parameters include:
- Temperature: Controls randomness and creativity, with higher values promoting more diverse and potentially surprising responses, while lower values lead to more deterministic and predictable output.
- Frequency penalty: Discourages repetition of tokens, encouraging variation in the generated text.
- Presence penalty: Promotes the use of less frequent tokens, increasing diversity and reducing the likelihood of repetitive patterns.
- Top-p: Controls response diversity by setting a cumulative probability threshold for word selection, ensuring that only the most likely words are considered at each step of the generation process.
Besides adjusting these settings, a moderation layer can be added to filter out inappropriate or irrelevant content. This ensures the generated responses meet ethical guidelines and user expectations, creating a balanced framework for text generation in terms of creativity, diversity, accuracy, and safety.
V. Context and Data Enhancement
To improve the reliability of LLM responses, two effective strategies are incorporating external databases and using carefully designed prompts. External data broadens the knowledge base, enhancing accuracy and reducing hallucinations.
On the other hand, well-crafted prompts with clear instructions guide the generation process, reducing ambiguity for more coherent and reliable outputs. Together, these techniques have significant potential to enhance the trustworthiness and effectiveness of LLMs in real-world applications, leading to a smooth prompt engineering journey.
Bonus Fact: Innovative tools like LOFT (LLM Orchestration Framework Toolkit) provide efficient integration of Generative AI into chatbots, giving organizations more control over LLM responses. LOFT seamlessly embeds within NLU providers, allowing the inclusion of external APIs and structured content. This boosts context awareness, minimizing hallucination risks and enabling ethical use of Generative AI in organizations.
As AI evolves from theory to real-world use, ethical considerations become more complex. Technologies like ChatGPT, while powerful, raise concerns about bias and content moderation. To address this, OpenAI’s Moderation API is a step towards responsible AI, using a combination of automated systems and human oversight. Examples from platforms like Twitter and YouTube show the effectiveness of this hybrid model.
So, as we come to conclude, you must have cleared your concepts around LLM hallucinations and various factors like data bias, privacy concerns, and source-reference divergence.
Following the best practices and methods, you can minimize hallucinations and improve the quality and trustworthiness of LLM outputs.
Quick Tip: What can you do?
Start exploring resources such as AI ethics podcasts, attend webinars on evaluating machine learning models, and take courses on AI ethics to stay informed. The ethical management of AI requires collective vigilance from all stakeholders, ensuring that technological advancements serve as a force for good in your business.

Explore the finer details of upgrading your product with GenAI.
To know about LLMs and GenAI-based cutting edge digital transformations, reach out to us at Nitor Infotech.



