Big Data and Analytics | 08 May 2024 | 14 min
Pandas vs. PySpark: Comparing Modern Python Data Processing Paradigms

Big Data and Analytics | 08 May 2024 | 14 min

In today’s data-driven world, organizations face the challenge of efficiently processing and handling large datasets. While Pandas came as a solution to handle small to medium-sized datasets, it struggled with heavy data loads. Fortunately, Apache Spark, an advanced big data processing framework, stepped in to address this issue.
In this blog, we will explore the various aspects of data processing and features using Spark, highlighting its scalability and in-memory computing. By the end of this blog, you will have a clear understanding of when to use pandas and when to leverage the power of PySpark.
So, let’s get rolling!

Pandas is a Python library that offers efficient and easy-to-use data structures and data analysis tools. It excels in handling small to medium-sized datasets, providing a high-level interface for data manipulation and exploration. With its intuitive syntax and extensive functionality, pandas have become the go-to tool for many data scientists and analysts.
PySpark is the Python API for Apache Spark. It is a distributed computing framework designed for processing large-scale datasets. Spark’s distributed computing model enables it to handle massive volumes of data across multiple servers, providing high performance and scalability. PySpark leverages Spark’s powerful features, such as in-memory processing and fault tolerance, to enable fast and efficient data processing and analytics.
Refer to this table for a clearer understanding:
| Pandas vs. PySpark: The Main Differences | ||
|---|---|---|
| Feature | Pandas | PySpark |
| Primary Use Case | Small to medium-sized datasets | Large-scale datasets |
| Data Handling | Single machine | Distributed computing |
| Performance | Good performance for smaller datasets | High performance and scalability for large datasets |
| Fault Tolerance | Not designed for fault tolerance | Built-in fault tolerance for data processing |
| Scalability | Limited scalability due to single-machine processing | Highly scalable across multiple servers |
| Dependencies | Few dependencies, mainly built on NumPy | Requires Apache Spark and its dependencies |
One of the most common questions is when to use Pandas and when to use Pyspark.
Here’s the answer:
The decision of whether to use PySpark or pandas depends on the size and complexity of the dataset, the specific task you want to perform, and the resources available.
To provide a clearer understanding, let me illustrate with an example of incremental data loading.
To compare these two, we will consider factors like performance, scalability, data processing speed and distributed computing.
For the first scenario, we will utilize PySpark code to migrate data from a MySQL database to a Redshift database, but with a Pandas approach. To accomplish this, you’ll need to perform the following actions:
for batch_id in batch_ids:
# Filter factFinancial_df by batch_id
start_time = datetime.now()
batch_df = fact_financial_df.filter(fact_financial_df.batch_id == batch_id)
end_time = datetime.now()
print('batch_df filtered for ',batch_id)
if batch_df.isEmpty():
print(f"No records found for batch_id: {batch_id}")
continue
print("batch_df is not empty")
def write_table_spark(df, url, table_name, user_name, password, source, mode):
driver = (
"com.mysql.jdbc.Driver"
if source == "mysql"
else "com.amazon.redshift.jdbc.Driver"
)
try:
df.write.format("jdbc").options(
url=url,
dbtable=table_name,
user=user_name,
password=password,
driver=driver,
).mode(mode).save()
print(f"Table written successfully: {table_name} ",df.count())
except Exception as e:
print(f"Error writing table: {e}")
raise e
Looks sorted, right? However, I have faced certain challenges while using pandas.
Keep reading to overcome such obstacles!
While performing the steps mentioned above for each batch_id in the list, including filtering data, checking if the dataframe is empty, and writing to database table, each step took me approximately 5 to 6 minutes. Therefore, the total time taken to write data to the Redshift table was around 16-20 minutes for each batch ID.
Although Spark is a distributed computing framework, the above approach does not fully leverage its capabilities. We could optimize the process by repartitioning our dataframe, persisting the dataframe, using the numpartitions option in the Spark dataframe write format, and loading the main dataframe into memory before filtering using the head function of PySpark. This would help us avoid functions like isempty(), which first read the entire dataframe before checking if it is empty.
That is, it’s time that we seek the best solution!
For the second scenario, I took the help of Apache Spark’s powerful features. Here’s how I did it:
Note: This limit() function will not read the whole data. We can just read the first row and check its count. If the count is not 0 then dataframe is not empty.
Here are some code snippets from the second approach that helped me overcome the previous obstacles:
a. Taking main dataframe in-memory:
def process_batch_ids(dim_tenant_df, fact_financial_df, tenant_schema, connection, batch_ids,
tgt_max_batch_id):
try:
fact_financial_df.persist()
fact_financial_head=fact_financial_df.head(1) # action on main df
dim_tenant_sk = retrieve_dimtenant_sk(dim_tenant_df, tenant_schema)
print(f"DimTenantSK: {dim_tenant_sk}")
for batch_id in batch_ids:
# Filter factFinancial_df by batch_id
start_time = datetime.now()
batch_df = fact_financial_df.filter(fact_financial_df.batch_id == batch_id)
b. Checking dataframe is empty or not:
# if batch_df.isEmpty():
if batch_df.limit(1).count() == 0:
print(f"No records found for batch_id: {batch_id}")
continue
print("batch_df is not empty")
Bonus info: Instead of using Spark’s ‘write’ function, we can also use AWS Glue’s DynamicFrame to write data to table. AWS Glue leverages the underlying AWS infrastructure to parallelize the writing process, distributing the data across multiple workers. This approach allows for faster and concurrent writing of data to the table.
def write_table_to_redshift( table_name, write_dyf):
try:
schema = ''
db_table_name = f"{schema}.{table_name}"
glueContext.write_dynamic_frame.from_options(
frame=write_dyf,
connection_type= "redshift",
connection_options={
"url": redshiftURL,
"user": redshiftUser,
"password": redshiftPassword,
"redshiftTmpDir": "s3://aws-glue-assets-12345-us-east-1/temporary/",
"useConnectionProperties": "true",
"dbtable": db_table_name,
"connectionName": "redshift",
},
)
By using Spark’s and AWS glue’s features we can significantly reduce the time required for data processing.
So, based on the comparison, it’s evident that Pandas is best suited for smaller datasets and situations where simplicity and interactivity are important. On the other hand, Spark’s distributed computing capabilities make it ideal for processing large datasets across multiple nodes, leading to faster and more scalable data analysis. Furthermore, Spark’s in-memory computing offers quicker data access and manipulation than Pandas’ reliance on disk-based operations.

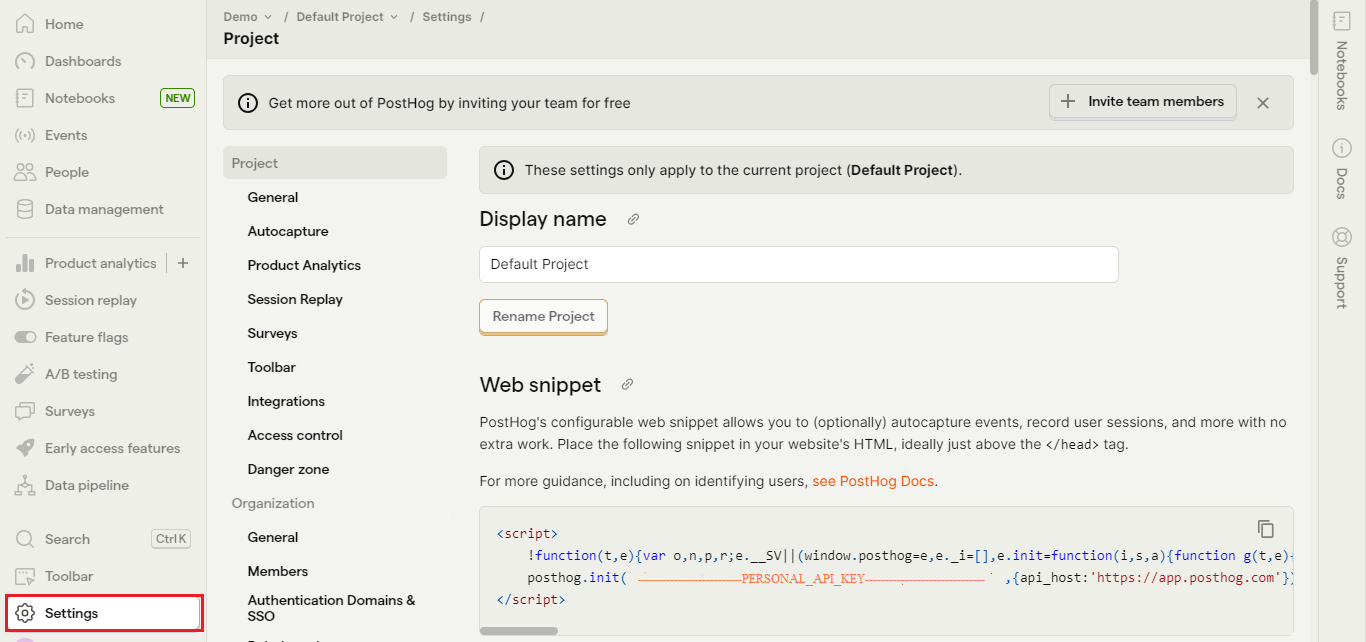
To know more about datasets and database management, write to us at Nitor Infotech.

we'll keep you in the loop with everything that's trending in the tech world.