How can you integrate Spark & Cosmos DB?
This blog helps you understand how Spark and Cosmos DB can be integrated allowing Spark to fully take advantage of Cosmos DB to run real-time analytics directly on petabytes of operational data!
High-Level Architecture

With the Spark Connector for Azure Cosmos DB, data is run in parallel with the Spark worker nodes and Azure Cosmos DB data partitions. Whether your data is stored in tables, graphs, or documents, you will achieve performance, scalability, throughput, and consistency all backed by Azure Cosmos DB
Accelerated connectivity between Apache Spark and Azure Cosmos DB increases your capacity to solve your rapidly moving data science challenges where information can be quickly maintained and retrieved using Azure Cosmos DB.
We can use the Cosmos DB Spark connector to operate Spark jobs with information stored in Azure Cosmos DB.
For cosmos DB, three kinds of spark connectors are accessible
Let’s develop Cosmos DB service using SQL API and query the data in our existing Azure Databricks Spark cluster using Scala notebook using Azure Cosmos DB Spark Connector.
Prerequisites:
Before proceeding further, ensure you have the following resources:
- Active Azure account.
- Azure Cosmos DB Account
- Pre-configured Azure Databricks Cluster
Step 1: Cosmos DB creation
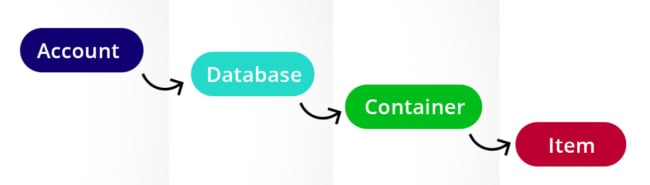
We must build a Cosmos Account in the first phase. We can build various databases under the Cosmos account. Each database includes a collection in which JSON formatted files are available. This database is similar to our RDBMS database; container is like a table, and item is like a row.
Create Database named Items and create Container Container1 in newly created database. We will be using these values in our script.
Data set: Please Yellow Taxi Trip Data from https://data.cityofnewyork.us/api/views/biws-g3hs/rows.csv?accessType=DOWNLOAD.
We will use a data migration tool to migrate data to Azure Cosmos DB. Download a pre-compiled binary from https://aka.ms/csdmtool, then run either of the following.
- exe: Graphical interface version of the tool
- exe: Command-line version of the tool
It is UI based tool, where we need to specify source and destination details. Once done, our data will be available on cosmos db.
Step 3: Azure Databricks Cluster Setup
Follow the steps at Azure Databricks to start setting up an Azure Databricks workspace and cluster – https://docs.azuredatabricks.net/getting-started/try-databricks.html
Step 4: Import the Cosmos DB connector library
- Download the recent Azure-cosmosdb-spark library for the Apache Spark variant that you are running (azure-cosmosdb-spark_2.4.0_2.11_1.3.5) from https://search.maven.org/artifact/com.microsoft.azure/azure-cosmosdb-spark_2.4.0_2.11/1.3.5/jar
- Upload the downloaded JAR files to Databricks
- Install the uploaded libraries into your Databricks cluster.
Step 5: Using Databricks notebooks
We have created notebook with Scala language. Azure Databricks supports Python, R and SQL also.
1. Import the required libraries to our notebook using the following command:
import org.joda.time._ import org.joda.time.format._ import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark import com.microsoft.azure.cosmosdb.spark.config.Config import org.apache.spark.sql.functions._
2. We can create Cosmos DB configuration in our notebook
Val configMap = Map(
"Endpoint" -> {URI of the Azure Cosmos DB account},
"Masterkey"->{Key used to access the account},
"Database" ->{Database name},
"Collection"->{Collection name})
val config = Config(configMap)
- Dataframe Creation : Let’s define a data frame variable df and read our current setup to read the Cosmos DB information.
val df = spark.sqlContext.read.cosmosDB(config)
3. Let’s create view from dataframe which we can use as table in Spark SQL
df.createOrReplaceTempView(“container1”)
4. Once you have connected to the table, you can create a Spark Data Frame (in the preceding example, this would be container1).
For example, below command will print the schema for our data frame.
container1.printSchema()
5. Run Spark SQL query against your Azure Cosmos DB table
val sql1 = spark.sql(""" SELECT ( 3959 * Acos(Cos(Radians(42.290763)) * Cos(Radians(PICKUP_LATITUDE)) *
Cos(Radians(PICKUP_LONGITUDE)
- Radians(
-71.35368)) +
Sin(Radians(42.290763)) *
Sin(Radians(PICKUP_LATITUDE))) ) AS
Distance
FROM CONTAINER1
""") sql1.show()
And voila! You’re all set. You have enabled Spark to make the most of Cosmos DB and run real-time analytics using operational data.
Reach out to us at Nitor Infotech to learn more about how easy it is to integrate Spark with Cosmos DB and how it can be extremely advantageous for you to do so.



