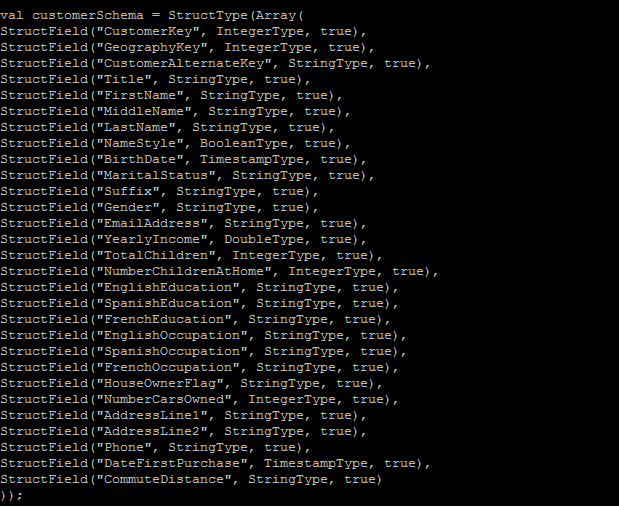
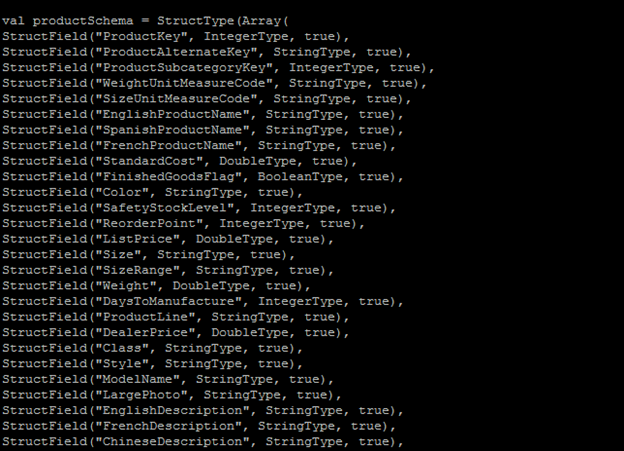
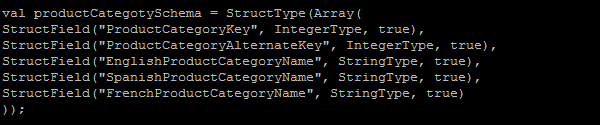
Spark has emerged as a favorite for analytics, especially those that can handle massive volumes of data as well as provide high performance compared to any other conventional database engines. Spark SQL allows users to formulate their complex business requirements to Spark by using the familiar language of SQL. So, in this blog, we will see how you can process data with Apache Spark and what better way to establish the capabilities of Spark than to put it through its paces and use the Hadoop-DS benchmark to compare performance, throughput, and SQL compatibility against SQL Server. Before we begin, ensure that the following test environment is available: SQL Server: 32 GB RAM with Windows server 2012 R2 Hadoop Cluster: 2 machines with 8GB RAM Ubuntu flavor Sample Data: For the purpose of this demo, we will use AdventureWorks2016DW data. Following table is used in query with no of records:
| Table Name | No. Of Records |
| FactInternetSales | 60458398 |
| dimProduct | 606 |
| DimProductSubcategory | 37 |
| DimProductCategory | 4 |
| Dimcustomer | 18484 |
We will compare performance of three data processing engines, which are SQL Server, Spark with CSV files as datafiles and Spark with Parquet files as datafiles. Query: We will use the following query to process data: select pc.EnglishProductCategoryName, ps.EnglishProductSubcategoryName, sum(SalesAmount) from FactInternetSales f inner join dimProduct p on f.productkey = p.productkey inner join DimProductSubcategory ps on p.ProductSubcategoryKey = ps.ProductSubcategoryKey inner join DimProductCategory pc on pc.ProductCategoryKey = ps.ProductCategoryKey inner join dimcustomer c on c.customerkey = f.customerkey group by pc.EnglishProductCategoryName, ps.EnglishProductSubcategoryName Let’s measure the performance of each processing engine:
- SQL Server:
While running query in SQL Server with the 32GB RAM Microsoft 2012 Server, it takes around 2.33 mins to execute and return the data. Following is the screenshot for the same:

- Spark with CSV data files:
Now let’s export the same dataset to CSV and move it to HDFS. Following is the screenshot of HDFS with the CSV file as an input source.














- Spark with Parquet file for Fact Table:
Now, let’s convert FactInternetSaleNew file to parquet file and save to hdfs using the following command: salesCSV.write.format(“parquet”).save(“sales_parquet”) Create dataframe on top of Parquet file using below command: val sales = sqlContext.read.parquet(“/user/nituser/sales.parquet”) And create temp view using sales data frame: sales.createOrReplaceTempView(“salesV”) Now, we will run the same query which we used in step 2: val df_1=spark.sql(“””select pc.EnglishProductCategoryName, ps.EnglishProductSubcategoryName, sum(SalesAmount) from salesV f inner join productV p on f.productkey = p.productkey inner join productSubCategoryV ps on p.ProductSubcategoryKey = ps.ProductSubcategoryKey inner join productCategoryV pc on pc.ProductCategoryKey = ps.ProductCategoryKey inner join customerV c on c.customerkey = f.customerkey group by pc.EnglishProductCategoryName, ps.EnglishProductSubcategoryName “””) It will return the same result set in less than 20 secs.




