
Elasticsearch (ES) is the living heart of today’s most popular log analytics platform. As we all know, it is a NoSQL, distributed, and full-text database. With NoSQL, it doesn’t require any structured data and it does not use any structured query language for querying the data. It is not just a database but like other NoSQL databases ES also provides search engine capabilities and other related features. It helps you to store, search, and analyze copious amounts of data swiftly. It saves data and indexes automatically using restful API.
In this blog, I’d like to share insights on the ‘Elasticsearch with Python’ partnership. Let’s get started! For starters, let’s delve into how it works.
How does it work?
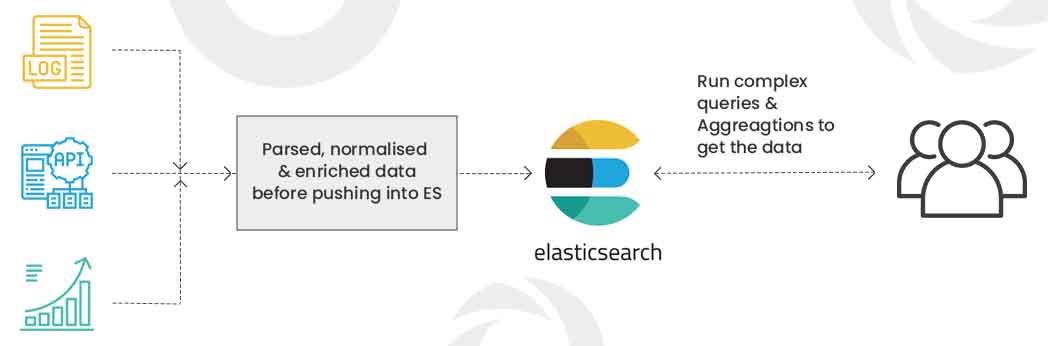
Raw data from different sources like logs, web applications, system metrics flows into Elasticsearch. The raw data is cut up, normalized, enhanced and then indexed in Elasticsearch. Once the data is indexed into Elasticsearch, users can run complex queries against their data and use aggregations to retrieve complex summaries of their data.
Now let’s dive into setting up the environment.
Setting Up the Environment
Setting up Elasticsearch locally is so easy. It needs to be downloaded and the executable should be run as per your system. Ensure that you have installed Java on the machine (the Lucene engine is built in Java).
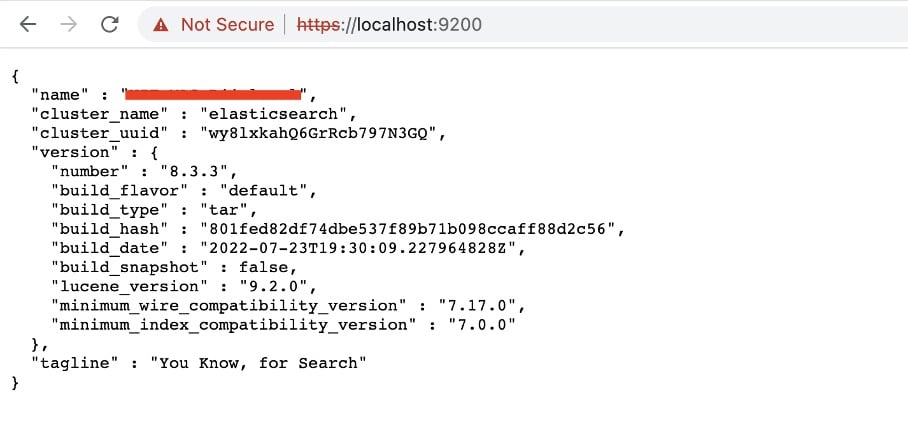
After you set up the local environment, check whether it’s working by entering http://localhost:9200 in your browser or via cURL. You will see a JSON response like this:
Let’s learn how to ‘pythonize’ this –
Elasticsearch offers REST APIs for data management, but there is an official library named elasticsearch if you’d like to use ES with Python effectively.
Use the following command to install it in Python:
pip install elasticsearch
In Python, this library can be used to connect to the ES instance running on http://localhost:9200/:
# make sure ES is up and running[Text Wrapping Break]from elasticsearch import Elasticsearch[Text Wrapping Break]es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
Now using this ES instance, we can easily do a basic CRUD operation as follows –
Let’s understand the concept using some dummy data.
Let’s first insert some data from JSON. Here, I’m going to add some dummy employee details held by a company.
data=[{"salary":"$2,410.62","age":40,"name":"Matt Aronoff","gender":"male","company":"EVENTEX","email":"mattaronoff@eventex.com","phone":"+1 (857) 491-2461"},{"salary":"$1,143.56","age":28,"name":"Matt Gates","gender":"male","company":"EVENTEX","email":"mattgates@eventex.com","phone":"+1 (825) 524-3896"},{"salary":"$2,542.95","age":20,"name":"Bella Marshall","gender":"female","company":"EVENTEX","email":"bella@eventex.com","phone":"+1(920)569-2780"},{"salary":"$2, 235.86","age":34,"name":"MarinaPlommer","gender":"female","company":"EVENTEX","email":"marina@eventex.com","phone":"+1(823)451-2064"},{"salary":"$2, 606.95","age":34,"name":"WillJose","gender":"male","company":"EVENTEX","email":"willjose@eventex.com","phone":"+1(913)425-3716"}][Text Wrapping Break][Text Wrapping Break]for dt in data:[Text Wrapping Break] res = es.index(index='first-index', body=dt)[Text Wrapping Break] print(res)
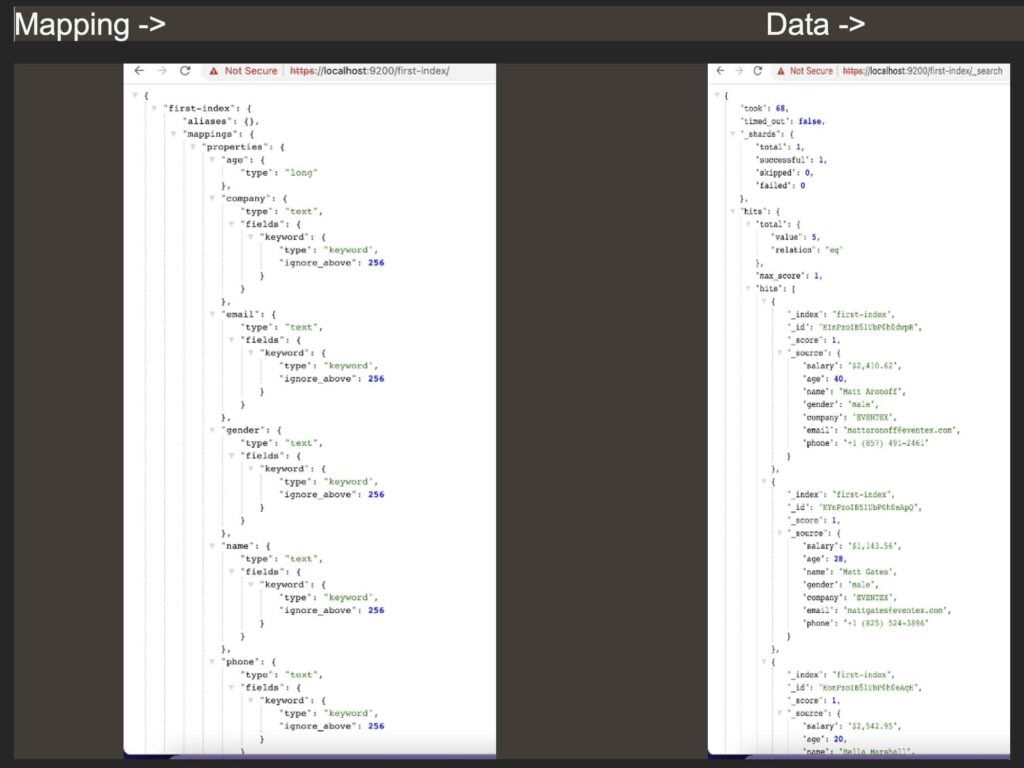
Once we execute the above command,
- firstly, it creates an index named ‘first-index’ if it is not present already and
- it will add each dictionary one by one.
The data is identical, so ES handles index creation automatically. To list all the available indices, we can use the following command –
print(es.indices.get_alias("*"))
Now ES queries are similar to database queries which are used to retrieve data from ElasticSearch. The query can be directly executed by writing it in a dict form.
Now let’s write a query to simple search records from first-index where gender is male and age is greater than or equal to 25:
search_by_gender_age_query={[Text Wrapping Break] 'query': {[Text Wrapping Break] 'bool': {[Text Wrapping Break] 'must': [[Text Wrapping Break] {[Text Wrapping Break] 'match': {[Text Wrapping Break] 'gender': 'male'[Text Wrapping Break] }[Text Wrapping Break] },[Text Wrapping Break] {[Text Wrapping Break] 'range': {[Text Wrapping Break] 'age': {[Text Wrapping Break] 'gte': 25[Text Wrapping Break] }[Text Wrapping Break] }[Text Wrapping Break] }[Text Wrapping Break] ][Text Wrapping Break] }[Text Wrapping Break] }[Text Wrapping Break]}
# Use above query to search the data into ES - [Text Wrapping Break]results=es.search(index='first-index', body=search_by_gender_age_query)
[Text Wrapping Break]print(results)
Now, let me acquaint you with the features of Python Elasticsearch.
Features of Python Elasticsearch
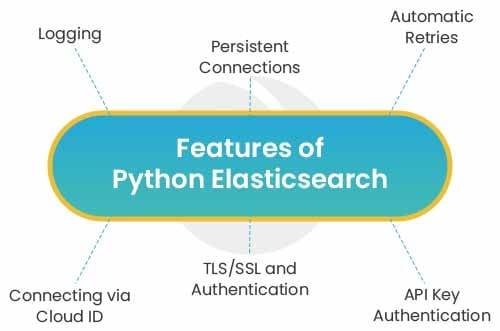
1. Logging – Python Elasticsearch uses the standard logging library. i.e. elasticsearch and elasticsearch.trace. Elasticsearch is used to log standard activity while elasticsearch.trace logs requests to the server in the form curl commands using pretty-printed JSON that can then be executed from command line.
2. Persistent Connections – Python Elasticsearch uses persistent connection inside of individual connection pools. The transport layer will create an instance of the selected connection class per node and monitor the health of individual nodes. In case a node becomes unresponsive, it is put on a timeout by the ConnectionPool
3. Automatic Retries – If a node connection failed due to some connection issue which raises “ConnectionError” then it is considered in faulty state. It will be placed on hold for dead_timeout seconds and the request will be attempted again on another node. In case a connection fails several times, the timeout will become larger to avoid hitting a node that is down. If a live connection is not available, the connection with the smallest timeout will be utilized.
4. Connecting via Cloud ID – We can also configure our application to work with our elastic cloud deployment just by configuring Cloud ID. We need cloud_id with http_auth or api_key to authenticate our ES cloud deployment.
from elasticsearch import Elasticsearch
es = Elasticsearch(
cloud_id="cl-bpresxxx...",
http_auth=("elastic", "<password>"),
)
5. TLS/SSL and Authentication – We can also configure our client to use SSL for connecting to our Elasticsearch cluster, including certificate verification and HTTP auth:
from elasticsearch import Elasticsearch
# you can use RFC-1738 to specify the url
es = Elasticsearch(['https://user:secretkey@localhost:443'])
# … or specify common parameters as kwargs
es = Elasticsearch(
['localhost', 'anotherhost'],
http_auth=('user', 'secret'),
scheme="https",
port=443,
)
# SSL client authentication using client_cert and client_key
from ssl import create_default_context
context = create_default_context(cafile="path/to/cert.pem")
es = Elasticsearch(
['localhost', 'otherhost'],
http_auth=('user', 'secret'),
scheme="https",
port=443,
ssl_context=context,
)
6. API Key Authentication – We can configure the client to use Elasticsearch’s API Key for connecting to our cluster. This method of authentication has been initiated with the release of Elasticsearch 6.7.0.
from elasticsearch import Elasticsearch
# you can use the api key tuple
es = Elasticsearch(
['node-1', 'node-2', 'node-3'],
api_key=('id', 'api_key'),
)
Now that you are familiar with the features, read on to know what Elasticsearch DSL is.
Elasticsearch DSL
Elasticsearch DSL is a high-level library. It aims to help with writing and running queries against Elasticsearch. It is built atop the official low-level client.
It provides a more convenient and idiomatic way to write and manipulate queries by mirroring the terminology and structure of Elasticsearch JSON DSL while exposing the whole range of the DSL from Python. This can be done directly by making use of defined classes or query set-like expressions.
Well, it’s time for me to wrap up my thoughts. Elasticsearch is a one-of-a-kind search engine that allows deep analysis of data using aggregation. It can make sense of large logs of data. Allow me to outline some more of its helpful features:
- It combines various types of searches include structured, unstructured, Geo, and so on.
- It uses standard RESTful APIs and JSON. The community builds and maintains clients in multiple languages.
- Tools like Kibana and Logstash help you to comprehend your data in easy and immediate ways.
Send us an email with your thoughts about getting started with Elasticsearch with Python and visit us at Nitor Infotech to get to know us. Also give this blog a read if you would like to get a comprehensive idea about Elasticsearch.



