In recent years, the field of NLP has seen a remarkable transformation. This is thanks to the emergence of language models. Fantastic progress in deep learning and artificial intelligence drives these models.
They are engineered to grasp, analyse, and generate textual content. This is in a way that closely emulates human-like communication.
We have trained them on massive amounts of text data. So, Large Language Models (LLMs) have acquired a wealth of linguistic knowledge that powers ML models in various applications.
In this blog, we are going to dive straight into training a Large Language Model. Let’s get set and go! Here is an overview of what you need to do as part of this training:
 Fig: Training Large Language Models (LLMs): Techniques and Best Practices
Fig: Training Large Language Models (LLMs): Techniques and Best Practices
There are two types of training:
Pre-training an LLM
The initial stage of training an LLM is pre-training. During pre-training, the model is exposed to a vast amount of unlabelled text data. The aim is to predict the next word in a sentence or fill in masked words within the sequence. This unsupervised learning task helps the model to learn the statistical patterns and structures of language.
Pre-training equips the LLM with a general understanding of grammar, syntax, and semantics. It allows the model to capture the relationships between words. It also helps it to build a strong foundation for language understanding.
Fine-tuning an LLM
Fine-tuning is the process of refining a pre-trained language model. You do this by training it on specific data related to a particular task.
This specialized training empowers the model to adapt its parameters and enhance its performance. This enables it to understand intricacies, nuances, and domain-specific patterns. These are necessary for generating precise and context-aware outputs.
You expose the model to targeted examples and relevant contexts. This enables it to produce more accurate and tailored responses.
Let’s now discuss some key aspects of training an LLM.
Hardware Requirements and Distribution Strategies for the Training of Large Language Models (LLMs)
Scaling up the training of large language models (LLMs)? This requires careful consideration of hardware requirements and distribution strategies.
Here are some practical points to understand the challenges and opportunities involved:

Fig: Practical points to understand the challenges and opportunities involved in training LLMs
- Starting small, scaling up gradually: Training a small neural network on a single GPU is a good starting point. It allows you to familiarize yourself with the training process and gain hands-on experience.
- Data parallelism for moderate-sized models: When dealing with moderately sized models, you can distribute the workload. Do this using a data parallel configuration. Many GPUs work in parallel. They train different parts of the model on separate data portions. You then average the results. This approach is effective. But it has limitations for very large neural networks.
- Pipelined model parallelism for complex models: To tackle the limitations of data parallelism, you need a pipelined model parallel architecture. You then distribute the model across a lot of GPUs. This is with careful partitioning to optimize memory and input/output (IO) bandwidth. Use sequential processing to ensure efficient training. Implementing this architecture requires meticulous optimization to overcome complexities.
- Tensor model parallelism for extremely large models: In cases where even a single GPU cannot accommodate certain layers of the model, tensor model parallelism comes into play. You split individual layers and spread them across a lot of GPUs. This enables the training of extremely large neural networks. But this approach demands manual coding, configuration, and meticulous implementation. Why? For correct and efficient execution.
- Experimentation and fine-tuning: Tackling the challenges of training large language models is an iterative process. Researchers often combine a lot of parallel computing techniques and experiment with different configurations. Fine-tuning the implementation based on the specific requirements of the model and the available hardware is crucial to achieve optimal results.
- Learning from failures: Training large language models is a complex task. You could expect a few failures along the way. It’s important to embrace failures as opportunities for learning and improvement. Analyze the failures, identify the root causes, and adjust your approach accordingly.
Understanding model architecture choices
Choosing the right model architecture is crucial for training Large Language Models (LLMs) that caters to ML models. Here’s a practical and concise breakdown to help you understand the choices and select the best model:
- Complexity and computational requirements: Consider the model’s depth and width. This is to balance complexity with available computational resources.
- Harness attention mechanisms: Use self-attention or Transformer-based attention. This is to capture context and dependencies effectively.
- Leverage residual connections: Opt for architectures with residual connections. These are to ease optimization challenges in deep models.
- Explore architectural variants: Understand the unique characteristics of GPT, BERT, and XLNet. Choose the one aligned with your task (e.g., generative modelling, bi-directional/masked language modelling, or multi-task learning).
- Contextualize for your task: Align the architecture with your specific requirements. Focus on bi-directional understanding, masked language modelling, or multi-task learning.
Consider complexity, attention mechanisms, residual connections, architectural variants, and task context. You can develop effective and efficient LLMs tailored to your needs.
Let’s turn to tokenization methods.
Implementing tokenization methods
Tokenization is a crucial step in training Large Language Models (LLMs). Here, you break down textual data into smaller units called tokens. Consider the following techniques:
- Word-based tokenization: Treat each word as a separate token, which is straightforward. But it may result in a large vocabulary size, especially in languages with extensive vocabularies.
- Subword-based tokenization: Techniques like Byte Pair Encoding (BPE) or SentencePiece split words into subword units based on their frequency in the training data. This reduces the vocabulary size and handles out-of-vocabulary words more effectively.
- Character-based tokenization: Treat each character as a token. This enables the model to handle unseen words. But this approach increases the input length. This may impact computational requirements.
Optimizing, Monitoring, and Regularizing Training for Large Language Models (LLMs)
1. Improving Performance with Loss Functions and Optimization Techniques:
- Minimize prediction errors and adjust parameters for better model performance.
- Common loss functions: Cross-entropy and mean squared error, measuring the differences between predicted and desired outputs.
- Optimization techniques: Stochastic gradient descent (SGD), Adam, and RMSprop, ensuring efficient parameter updates.
- Control learning speed through learning rate schedules (e.g., step decay or exponential decay) to strike a balance between acquiring knowledge and preventing overfitting.
2. Monitoring and Evaluating Training Progress:
- Evaluate model performance using metrics like accuracy, perplexity, or F1 score during training.
- Assess generalization ability and detect overfitting using validation datasets.
- Visualize training progress with plots or graphs to track metrics over epochs, gaining insights into the model’s development.
3. Enhancing Generalization and Preventing Overfitting with Regularization:
- Apply regularization techniques to improve the model’s generalization ability.
- L1 and L2 regularization methods penalize large parameter values to prevent overfitting.
- Dropout technique randomly deactivates neurons, reducing reliance on specific features and enhancing generalization.
- Employ early stopping to halt training when performance on the validation set deteriorates, preventing overfitting.
4. Diversifying Training Data and Data Augmentation:
- Increase the diversity of training examples through data augmentation techniques such as rotation, flipping, or adding noise.
- Augmentation enhances model stability and effectiveness while mitigating overfitting risks.
Optimize the training process, track progress, put in place regularization techniques, and diversify training data. We can significantly enhance the training of Large Language Models (LLMs). These practices lead to:
- Improved performance
- Better generalization
- Effective mitigation of overfitting risks
They enable LLMs to understand and generate language more accurately and efficiently.
Fine-tuning: Enhancing Large Language Model Performance
Fine-tuning is a powerful technique used in Large Language Models (LLMs). It helps to optimize their performance for specific tasks. Here’s a practical breakdown of the process:
1. Fine-tuning in a nutshell:
- Take a pre-trained language model like GPT-3 or BERT.
- Further train it using a task-specific dataset to adapt it to the desired task.
- Update the model’s parameters to optimize its performance.
2. Benefits of fine-tuning:
- Enables LLMs to learn task-specific patterns and nuances.
- Improves effectiveness and accuracy in generating task-specific responses.
- Allows the model to specialize its knowledge for the given task.
3. Practical considerations:
- Fine-tuning large language models typically requires high-processing GPUs due to their size.
- New techniques, such as Parameter Efficient Fine Tuning, aim to reduce GPU requirements while maintaining performance.
By understanding the fine-tuning process, we can optimize the performance of large language models for specific tasks.
Fine-tuning often demands high-processing GPUs. Emerging techniques like Parameter Efficient Fine Tuning seek to minimize resource requirements.
Let’s enjoy an overview of state-of-the-art techniques!
Low-Rank Adaptation (LoRA)
Low-Rank Adaptation (LoRA) is one of the main methods under Parameter Efficient Fine-tuning (PEFT). LoRA freezes the pre-trained model weights. It injects trainable rank decomposition matrices into each layer of the transformer architecture.
By making the middle part smaller, we can reduce the number of trainable elements. We can decrease the dimensionality of the features. This technique enables fine-tuning large models like GPT3 with 175B parameters. This is by reducing the trainable parameters up to 10,000 times.
![]()
Source: https://arxiv.org
Fig: The architecture of Low-Rank Adaptation (LoRA)
The diagram illustrates the architecture of LoRA. The red block on the right side represents the LoRA model’s weights that we want to train. By reducing the middle part, we can decrease the number of trainable elements and feature dimensionality to “r << d”.
The total number of elements can be calculated as “2 times LoRA times dmodel times r”. LoRA blocks are inserted into the Attention layer of the Transformer architecture. The specific value of “r” may vary depending on the task. But experiments have shown good results using values between 2 and 4.
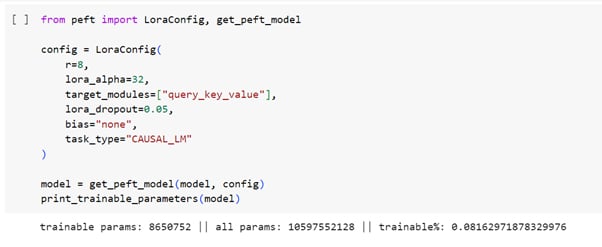
Fig: A code snippet that demonstrates the implementation of LoRA
The code snippet demonstrates the implementation of LoRA. We import LoraConfig and get_peft_model for specific configuration settings. We retrieve the initially fetched LLM in the PEFT model.
The code showcases the vast difference between the actual parameters of the model and the trainable parameters. This model will undergo further fine-tuning on the data.
Quantized LoRA (QLoRA):
QLoRA is another method. It involves backpropagating gradients through a frozen, 4-bit quantized pre-trained language model into Low Rank Adapters (LoRA).
Quantization is a technique used to convert input data from a format containing more information to a format containing less information.
It involves converting data types that use more bits into types that use fewer bits. An example is, converting from 32-bit floating-point numbers to 8-bit integers.
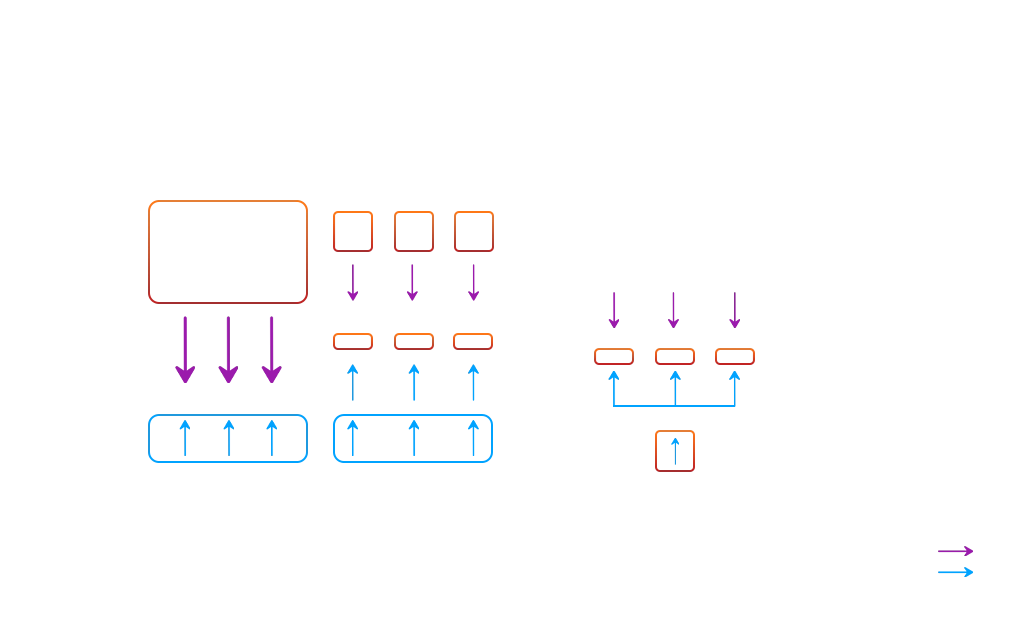
Source: https://arxiv.org
Fig: The variations between QLoRA and its predecessor, LoRA
The diagram illustrates the variations between QLoRA and its predecessor, LoRA. QLoRA implements 4-bit precision quantization for the transformer model. It utilizes paged optimizers on the CPU to handle unexpected data spikes.
This practical approach enables efficient fine-tuning of LLMs like LLaMA. This reduces memory demands while maintaining performance.
Besides LoRA and QLoRA, PEFT includes other methods:
- Prefix Tuning: Keeps the language model parameters frozen. Optimizes a small continuous task-specific vector called the prefix.
- Prompt Tuning: Modifies the input prompts given to the model during inference to optimize pre-trained language models for specific tasks. It operates at the prompt level instead of updating the entire model.
For these methods, implementation requires code using PyTorch and suitable transformers.
Tools like Generative AI Studio by Google simplify the fine-tuning of LLMs. Select the base model, upload data in JSON format, and fine-tune the model. This way, users can save time and effort.

Revitalize your products with GenAI for a distinctive market presence.
Allow me to wrap up my ideas…
In this blog, we’ve looked at the strategies and steps involved in pre-training a large language model. We’ve also looked at an overview of state-of-the-art LLM fine tuning techniques.
Write to us with your thoughts on training LLMs. Also visit us at Nitor Infotech to see what we’ve been exploring in the AI technology realm!



