
Consider a scenario where you are using a large language model (LLM) to process extensive documents. While doing so, you can encounter difficulties in efficiently retrieving relevant information. That is, conventional retrieval techniques often prove inadequate for lengthy contexts. This results in diminished relevance, heightened latency, and disjointed responses. As the applications of generative AI and AI continue to expand, the demand for a more organized and intelligent method of information retrieval becomes increasingly essential. Here, RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) redefines how LLMs manage vast amounts of information.
Now what’s that?
Well, I’ll share everything about this cutting-edge framework and its role in transforming long-context retrieval for LLMs in this blog. You’ll also learn about its key concepts, workflow, and real-world applications. Additionally, I’ll provide you with a step-by-step process to implement RAPTOR.
So, whether you’re a developer implementing retrieval-augmented generation or an AI enthusiast curious about advanced retrieval techniques, understanding everything about RAPTOR’s innovative design will help unlock new possibilities in LLM applications.
So, start feeding your curious mind as you read!
What is RAPTOR and Why Does it Matter?
RAPTOR is a sophisticated approach to how large language models (LLMs) handle information. Picture it like a treehouse built amid a vast forest of data. RAPTOR organizes information into a clear, hierarchical structure, helping the model navigate through long contexts with ease.
Instead of sifting through an overwhelming amount of data, RAPTOR allows the model to focus on what truly matters. RAPTOR guides it to the right sections in an efficient, systematic way. This approach makes processing large volumes of text smoother and more intuitive. With RAPTOR, long-context retrieval becomes not just manageable, but streamlined. This allows LLMs to operate with greater precision and speed.
Here are a few key reasons why RAPTOR is so important:

Fig: Importance of RAPTOR
- Scaling context length: It allows large language models (LLMs) to effectively reason over extensive documents. By accommodating longer texts, it enhances the model’s understanding and contextual analysis.
- Enhancing relevance: It delivers information tailored to the query’s complexity, ensuring that responses are at the appropriate level of detail. This targeted approach improves the overall relevance of the information provided.
- Improving efficiency: The recursive structure of the model significantly reduces redundant processing. This design choice streamlines operations. This leads to faster and more efficient responses.
Keep reading to learn about the core concepts of RAPTOR.
What are the Key Concepts of RAPTOR?
Listed below are some of the key concepts of RAPTOR:

Fig: Key Concepts of RAPTOR
1. Tree-Structured Representation
RAPTOR organizes documents in a hierarchical tree format, where each node represents a different level of abstraction. The root node contains the most general summary of the document. This is while deeper nodes hold increasingly granular details.
2. Recursive Processing
The model processes information recursively, starting from the root node and drilling down into lower levels only as needed. This allows RAPTOR to dynamically focus on relevant details while ignoring unnecessary information.
3. Abstractive Summarization
Each level of the tree is created using abstractive summarization. This means the information at each node is a condensed, high-level summary rather than a simple extract. This ensures that the tree captures the meaning and context at various levels of granularity.
4. Context Awareness
By working with the tree structure, RAPTOR can retrieve and provide responses that are both broad and contextually detailed, depending on the query. This approach is particularly useful for long documents. When it comes to these, traditional flat retrieval systems often struggle to manage relevance and coherence.
5. Efficient Computational Load
The hierarchical approach significantly reduces the computational load compared to traditional methods. Instead of processing the entire document at once, RAPTOR navigates the tree selectively, focusing only on relevant branches. This makes it well-suited for long-context tasks.
Wondering how RAPTOR functions? The answer lies in the section ahead.
How Does RAPTOR Enhance RAG Efficiency?
RAPTOR enhances Retrieval-Augmented Generation (RAG) through its hierarchical structure and recursive processing. Thus, it enables efficient and context-aware retrieval.
Internally, RAPTOR integrates these key mechanisms:
- Clustering: Similar text chunks are grouped using clustering algorithms like Gaussian Mixture Models (GMMs) to ensure related content is organized.
- Abstractive Summarization: LLMs generate concise summaries for clusters, reducing complexity while maintaining semantic integrity.
- Embedding Updates: Summarized clusters are re-embedded into vectors to facilitate further abstraction and context-aware retrieval.
- Tree Navigation: Based on query requirements, RAPTOR employs tree traversal or collapsed tree retrieval to prioritize relevance and efficiency.
This multi-step process ensures RAPTOR can handle diverse queries, from broad summaries to specific facts. It does this by leveraging its adaptable RAG mechanism.
Here’s a representation of RAPTOR’s document hierarchy:
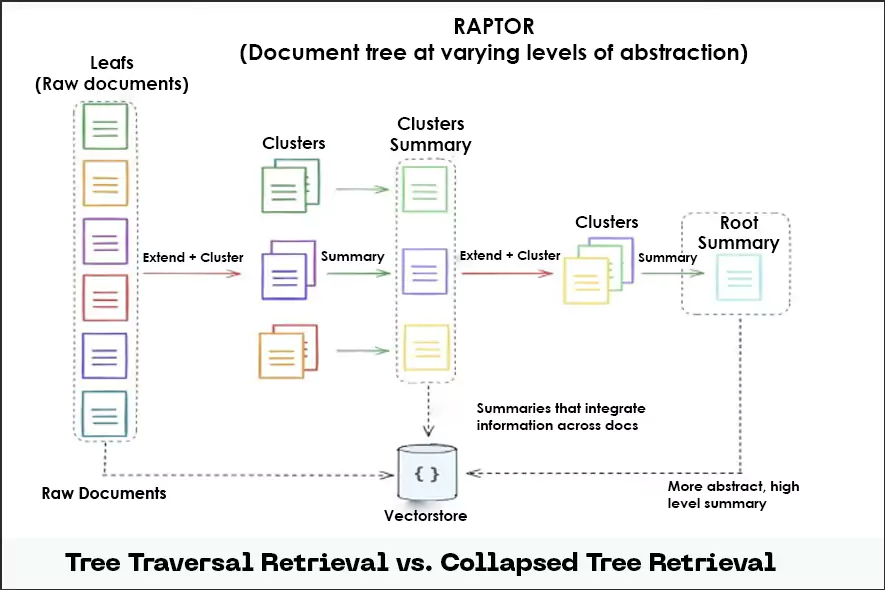
Fig: RAPTOR’s document hierarchy
It combines the above-mentioned advanced mechanisms to enable efficient and context-aware information retrieval. Here’s a step-by-step breakdown of its operation:
1. Preprocessing: Preparing the Document
The first step in RAPTOR’s workflow involves preprocessing the document to create a foundation for hierarchical organization. The document is divided into smaller, more manageable units, such as sentences or paragraphs, which are then transformed into dense vector embeddings.
These embeddings serve as numerical representations of the semantic meaning of the text, enabling the system to perform efficient similarity comparisons during retrieval. This step is crucial for ensuring that the document’s information is organized in a way that facilitates further processing and abstraction.
2. Recursive Processing: Refining Representations
At the core of RAPTOR is a recursive mechanism that iteratively refines the document’s representation. This process begins with clustering, where a clustering algorithm, such as Gaussian Mixture Models (GMMs), groups similar text chunks into clusters. These clusters are designed to group related information, making it easier to summarize effectively.
Once the clusters are formed, each is passed to a large language model (LLM), like GPT-3.5, which generates concise and informative summaries. These summaries encapsulate the essence of the clusters. They preserve their meaning while reducing their complexity. The summarized outputs are then re-embedded into vector representations. These can be processed in subsequent iterations. This cycle repeats until the desired recursion depth is reached. This gradually refines the document’s representation.
3. Tree Construction: Building the Hierarchy
After recursive processing, the refined document representations are structured into a hierarchical tree. At the base of the tree are the leaf nodes. These nodes represent the original text chunks.
Moving up the hierarchy, the nodes progressively contain summaries of their children, creating an organized abstraction of the document’s information. Each node in the tree has its own vector embedding. This embedding captures the semantic meaning of the information it represents.
This multi-layered tree structure allows the system to store data at varying levels of detail. It also ensures that retrieval tasks can be tailored to the user’s needs, whether they require broad summaries or detailed insights.
4. Retrieval: Navigating the Tree
When a query is presented, RAPTOR uses its hierarchical structure to retrieve relevant information efficiently. It employs two primary retrieval mechanisms depending on the query’s complexity.
The first, tree traversal retrieval, involves systematically exploring the tree, starting from the root node and progressing through its branches. Techniques like beam search help focus on the most promising parts of the tree. These ensure relevant information is prioritized. This approach is ideal for queries that require high-level context or overviews.
The second mechanism, collapsed tree retrieval, flattens the hierarchy, treating the tree as a single layer. In this mode, the query embedding is compared directly with the embedding of all nodes. This makes it suitable for factual or keyword-based queries requiring specific details.
This image illustrates the two different approaches to retrieving information from the hierarchical document structure:

Fig: Tree Traversal Retrieval vs. Collapsed Tree Retrieval
So, by selecting the appropriate retrieval strategy, RAPTOR adapts to diverse user needs, delivering both precision and efficiency.
Delve into the real-world applications of RAPTOR next.
How is RAPTOR applied in the real world?
RAPTOR’s capabilities make it suitable for a wide range of applications across these industries:
1. Education and E-learning
This is how RAPTOR helps:
- Personalized Learning: By analyzing students’ learning styles, progress, and knowledge gaps, RAPTOR helps create tailored learning experiences. This ensures that each student receives the most effective approach to their education.
- Intelligent Tutoring Systems: It can be used to develop intelligent tutoring systems that provide personalized feedback. These systems adapt to each student’s needs. They offer precise guidance and support throughout their learning journey.
- Content Summarization: It efficiently summarizes complex textbooks, research papers, and other dense content. It makes these materials more accessible by distilling key points and presenting them in a concise, easy-to-understand format.
2. Healthcare
This is how RAPTOR helps:
- Medical Diagnosis: It assists in medical diagnosis by analyzing patient records, medical literature, and imaging data. It helps identify potential health conditions. It enables more accurate and timely diagnoses.
- Drug Discovery: It accelerates drug discovery by analyzing vast amounts of biomedical literature and experimental data. This helps researchers identify promising compounds and streamline the development of new medications.
- Clinical Trial Analysis: It analyzes clinical trial data to identify trends, patterns, and potential side effects. This aids researchers in optimizing trial protocols and improving patient safety and treatment effectiveness.

Learn how we leveraged GenAI to revolutionize patient care and personalize treatment plans for one of our clients.
3. Financial Services
This is how RAPTOR helps:
- Risk Assessment: It assesses risk factors by analyzing historical data, market trends, and economic indicators. It helps predict potential financial crises. This enables businesses to take proactive measures and mitigate risks.
- Fraud Detection: It identifies fraudulent activities by analyzing large datasets of financial transactions. By spotting unusual patterns and inconsistencies, it helps prevent financial fraud and protect against potential losses.
- Investment Analysis: It analyzes market trends, company performance, and economic indicators to provide valuable insights. This enables investors to make informed decisions. This optimizes their investment strategies and maximizes returns.
Apart from these, RAPTOR also enhances Natural Language Processing (NLP) through capabilities like text summarization. This generates concise and informative summaries of long documents, and question answering. It provides relevant answers by understanding the context of complex queries.
All set with the foundation and curious to know the next steps? To be honest, this is where things get interesting! I’ve outlined a process to help you implement RAPTOR.
Enjoy the last bit!
How to Implement RAPTOR?
Here’s a step-by-step process that will help you implement RAPTOR using LlamaIndex:
Step 1: Setup and Configuration
Before diving into the implementation, you need to prepare your environment and set up the necessary configurations. This ensures that all tools, dependencies, and parameters are ready for smooth execution.
To do so, this is what you need to follow:
1. Install Required Libraries:
Use the following command to install the libraries:

Fig: Install Required Libraries
2. Create a Configuration File:
Once done, create a config.yaml file in your project directory to store sensitive information and parameters using this code:

Fig: Create a Configuration File
Step 2: Setting Up the Configuration
Now, you can implement the setup code to initialize the configuration. To do so, use this code:

Fig: Setting Up the Configuration
Step 3: Document Loading and Vector Store Setup
In this step, you need to focus on loading the document and preparing the vector store. To do so, use this code:

Fig: Document Loading and Vector Store Setup
Step 4: Configuring the RAPTOR Framework
With the document and vector store prepared, the next step is to set up the core components of the RAPTOR framework. This involves:
- defining the hierarchical structure,
- embedding models, and
- clustering algorithms essential for the system’s functionality.
Here’s how you can do it:

Fig: Configuring the RAPTOR Framework
Step 5: Setting Up the Retrieval and Query Engine
For the final step, you’ll need to configure the retriever and query engine. These components will enable you to efficiently execute queries on the processed document and retrieve the most relevant information.
To do so, follow this code:

Fig: Setting Up the Retrieval and Query Engine
That’s it! By now, you should be done implementing RAPTOR to reap its advanced benefits.
Key Insights and Takeaways – A Brief Recap
RAPTOR’s innovative approach to document processing and retrieval represents a significant leap forward in efficiently handling long-context data with large language models. By combining preprocessing, recursive refinement, hierarchical tree construction, and adaptive retrieval mechanisms, it provides a flexible and scalable solution for managing complex textual information.
Its unique recursive processing enables a deep, multi-level understanding of the document. The hierarchical structure allows for tailored retrieval based on the user’s needs, whether for broad context or detailed insights. The dual retrieval methods – tree traversal and collapsed tree retrieval – ensure that RAPTOR can efficiently handle both high-level queries and precise fact-based inquiries.
Overall, its ability to process and retrieve information through an organized, hierarchical framework enhances its effectiveness in real-world applications. This offers new possibilities for long-context reasoning and advanced information retrieval in large-scale systems.
No matter the field – whether applied in legal, research or any other data-intensive domain, RAPTOR continues to stand as a powerful tool for transforming how we interact with and extract value from complex documents. Start exploring more about it today!
For advanced AI-powered software product development services, connect with us at Nitor Infotech. Our experts specialize in crafting tailored solutions that deliver lasting value and support a sustainable, long-term future.
To effectively scale context lengths in Retrieval-Augmented Generation (RAG) models, the RAPTOR (Retrieval-Augmented Transformer) precision technique can be utilized. RAPTOR enhances the retrieval process by optimizing how context is integrated into the generation phase, allowing for longer and more relevant context lengths.
By leveraging advanced indexing and efficient query formulations, RAPTOR improves the model’s ability to access and utilize larger datasets, thereby increasing the precision of generated outputs. This approach helps in achieving a balance between context length and computational efficiency, ultimately leading to more accurate and contextually rich responses in RAG systems.



