
Retrieval-Augmented Generation (RAG) is transforming the way IT/software businesses access and use information. By combining powerful data retrieval with AI-driven generation, it ensures real-time updates, enhances accuracy, and streamlines workflows. RAG can pull insights from external sources. It adapts dynamically, making processes more efficient, cost-effective, and future-ready.
With a mountain of detailed documents to sift through, extracting vital information and addressing client queries swiftly is crucial. Traditional methods, like fine-tuning large language models (LLMs), often bog you down with slow, resource-draining processes. RAG is a game-changing solution. It streamlines the way we meet diverse client needs with agility and precision.
RAG is a way to find and create answers by using both information searches and smart writing. It helps make answers more accurate by using extra facts from other sources.
In this blog, I’ll guide you through the key applications of RAG and the steps to effectively integrate it for improved data retrieval and generation. You’ll also explore the production deployment process and the futuristic benefits it offers.
What Are the Applications of RAG in the IT Services Industry?
RAG systems can significantly streamline processes in the IT services industry, especially for requirement gathering, analysis, and project initiation. Here are some of its key applications:
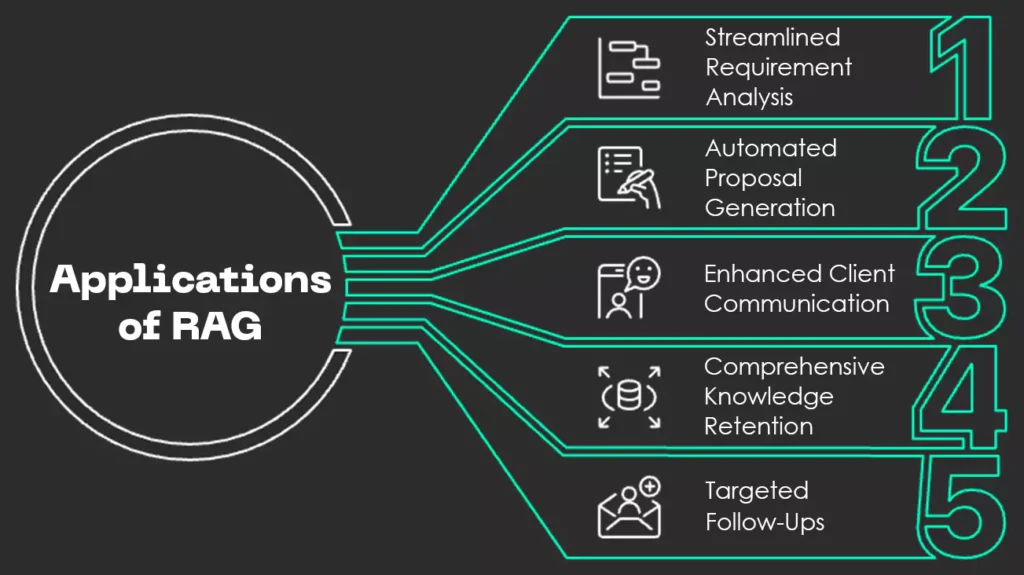
Fig: Applications of RAG
1. Streamlined Requirement Analysis: Quickly analyze lengthy client-provided documents and identify critical project details.
2. Automated Proposal Generation: Automatically generate initial drafts of project proposals based on extracted information from client requirements.
3. Enhanced Client Communication: Enhance communication by providing instant answers to client queries based on stored project data.
4. Comprehensive Knowledge Retention: Build a knowledge base by storing project-related documents and their processed outputs for future reference.
5. Targeted Follow-Ups: Identify gaps in client requirements and generate follow-up questions for clarification.
Extra read: The best evaluation metrics for LLM applications are here – optimize performance with the right insights!
Choosing the right approach for data retrieval and generation is crucial. Fine-tuning might seem like the obvious choice. However, RAG could be a better fit. Learn why up next!
Why Choose RAG Over Fine-Tuning?
RAG is favored over fine-tuning for several key reasons, including:
1. Dynamic Updates: RAG leverages an external vector database for retrieval. This allows the system to dynamically incorporate new information without requiring model retraining.
2. Cost Efficiency: Fine-tuning large models like deepseek-r1:14b can be resource-intensive. They can require significant computational power and time. RAG avoids this by using pre-trained models and focusing on retrieval.
3. Adaptability: Fine-tuned models are often tailored to specific tasks and may underperform on out-of-scope queries. RAG, with its retrieval-based approach, is inherently more flexible and adaptable to a wider range of queries.
4. Domain Independence: By separating the knowledge base (vector database) from the model, RAG allows the knowledge base to be domain-specific. This is while keeping the model generic. Thus, it enables better scalability and reuse.
5. Faster Deployment: RAG-based solutions can be deployed quickly by populating a vector store with embeddings. Whereas, fine-tuning requires additional cycles for data preparation, training, and evaluation.
Now that you understand the importance and benefits of RAG, it’s time to put that knowledge into action. Next, you’ll explore the installation and integration process of a RAG system.

Future-proof your business with GenAI-powered product modernization.
What Are the Steps Required to Set Up a RAG System Environment?
Before implementing the RAG system, it is vital to set up the environment properly. This section outlines the necessary steps to install, configure, and prepare all required components, ensuring the system runs efficiently on either CPU or GPU.
Here’s what you can do:
Phase 1. Setting up Ollama with Docker
Ollama is used to host the deepseek-r1:14b model. This makes it possible for any RAG tool to understand and process natural language. Here are the steps to set up Ollama with Docker:
Step 1: Install Docker
- Visit Docker’s official website and download the appropriate version for your operating system.
- Follow the installation instructions specific to your platform (Windows, macOS, or Linux).
- Once installated, verify Docker by running the following command in your terminal or command prompt:
docker --version
Step 2: Launch Docker and Pull the Ollama Image
- Open your terminal or command prompt.
- Then run the following command to pull the Ollama Docker image:
docker pull ollama/ollama:latest
- Start a Docker container for Ollama. If you have GPU support available and wish to utilize it for optimal performance, use this command:
docker run --gpus all -d --name ollama-container -p 11434:11434 ollama/ollama:latest
Wisdom Drop:
–gpus all: Enables GPU usage for accelerated performance.
-p 11434:11434: Maps the container’s port 11434 to your host machine.
- Ensure that the CUDA (Compute Unified Device Architecture) Toolkit is installed on your system for GPU functionality.
- To run on a CPU instead of a GPU, simply remove the –gpus all flag:
docker run -d --name ollama-container -p 11434:11434 ollama/ollama:latest
Step 3: Verify the Docker Container
- Check if the Ollama container is running by executing this command:
docker ps
- The output should display ollama-container in the list.
Note: Discover what Jenkins is and how you can leverage Docker as a Jenkins Agent for seamless automation.
Phase 2. Downloading the deepseek-r1:14b Model
The deepseek-r1:14b model must be downloaded within the Docker container to enable advanced natural language processing. To do so, follow these steps:
Step 1: Access the running Ollama container using this command:
docker exec -it ollama-container bash
Step 2: Use the Ollama CLI to download the required model:
ollama pull deepseek-r1:14b
This command fetches the deepseek-r1:14b model and prepares it for use.
Step 3: Exit the container once the model is successfully downloaded using this:
exit
This should be displayed if you follow the steps:
Screenshot: Exit the container
Phase 3. Installing Required Python Libraries
Python libraries play a crucial role in the implementation of this RAG system. You can install them by following these steps:
Step 1: Ensure Python 3.8 or higher is installed on your system. Verify your version by running:
python --version
Step 2: (Optional but recommended) Create a virtual environment to isolate dependencies:

Step 3: Install the necessary libraries using this command:
pip install gradio langchain langchain-chroma langchain-community fastembed langchain-ollam
Step 4: Finally, verify that all libraries have been installed correctly:
pip list
With the RAG environment set up, it’s time to dive into the implementation phase. We’ll start with an overview of the libraries and tools required.
What Are the Core Libraries and Tools for RAG Implementation?
Here are the core libraries required for RAG implementation:
- LangChain: Powers the chaining of document ingestion, embedding, and retrieval processes to enable seamless execution.
- PyPDFLoader: Handles the extraction and splitting of content from multi-page PDF files into smaller, manageable chunks.
- FastEmbedEmbeddings: Generates high-quality embeddings for document indexing and retrieval.
Here are the core tools required for RAG implementation:
- Gradio: Provides a dynamic, user-friendly interactive interface for document ingestion and querying.
- Chroma: Acts as the vector database for storing and managing embeddings.
- ChatOllama: Integrates the deepseek-r1:14b model, offering advanced natural language processing capabilities.
Onwards to the code implementation phase!
- ChatOllama: Integrates the deepseek-r1:14b model, offering advanced natural language processing capabilities.
How to Implement Key Components for a RAG System?
Here are the key components required to set up a RAG system:

Fig: Essential Components for Setting Up a RAG System
1. PDF Ingestion and Vector Storage
This process ingests a PDF document. Then, it splits it into smaller chunks for better processing. Next, it saves the processed data into a vector database (Chroma). This ensures efficient and accurate retrieval of relevant information.
Follow this code to implement it:
import logging import traceback
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings from langchain_chroma import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Configure logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') logging.error(f"Traceback: {traceback.format_exc()}")
def ingest(file): try:
logging.info("Starting PDF ingestion.") loader = PyPDFLoader(file.name)
pages = loader.load_and_split() logging.info(f"Loaded {len(pages)} pages from PDF.")
text_splitter = RecursiveCharacterTextSplitter( chunk_size=200,
chunk_overlap=100, length_function=len, add_start_index=True,
)
chunks = text_splitter.split_documents(pages) logging.info(f"Split pages into {len(chunks)} chunks.")
logging.info("Loading FastEmbedEmbeddings.") embedding = FastEmbedEmbeddings()
logging.info("Dumping data into Chroma database.") try:
Chroma.from_documents(documents=chunks, embedding=embedding, persist_directory="./s logging.info("Successfully persisted data to Chroma.")
except Exception as e:
logging.error(f"Error persisting data to Chroma: {e}")
return f"Processed {len(pages)} pages into {len(chunks)} chunks and saved to vector sto except Exception as e:
logging.error(f"Error during ingestion: {e}")
return f"An error occurred during ingestion: {e}"
Once you implement the code, you’ll get to see such an interface:

Screenshot: PDF Ingestion and Vector Storage
2. RAG Chain Creation
This configures the Retrieval-Augmented Generation (RAG) chain using the deepseek-r1:14b model. This is to enable natural language querying and precise response generation.
Here’s how you can implement it:
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains.retrieval import create_retrieval_chain
def rag_chain(): try:
logging.info("Creating RAG chain.")
model = ChatOllama(model="deepseek-r1:14b") prompt = PromptTemplate.from_template(
"""
<s> [Instructions] You are a helpful and precise assistant. Use the provided contex If the context does not contain enough information, respond with: "No context avail Ensure your answer is well-structured, concise, and directly addresses the question [Question] {input} [/Question]
[Context] {context} [/Context] [Answer]
"""
)
embedding = FastEmbedEmbeddings()
vector_store = Chroma(persist_directory="./sql_chroma_db", embedding_function=embedding retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={"k": 20, "score_threshold": 0.15},
)
document_chain = create_stuff_documents_chain(model, prompt) logging.info("RAG chain successfully created.")
return create_retrieval_chain(retriever, document_chain) except Exception as e:
logging.error(f"Error during RAG chain creation: {e}") raise
3. Query Processing
This processes user queries, retrieves relevant information from the vector database, and generates accurate responses using the RAG chain.
This is how you can implement it:
def ask(query): try:
logging.info(f"Received query: {query}") chain = rag_chain()
if not chain:
raise RuntimeError("RAG chain creation failed.")
result = chain.invoke({"input": query})
answer = result.get("answer", "No answer available.") context = result.get("context", [])
if not context:
logging.warning("No sources found in the context.") sources = ["No sources available."]
else:
sources = [doc.metadata.get("source", "Unknown source") for doc in context]
logging.info("Query successfully processed.") return answer, sources
except Exception as e:
logging.error(f"Error in ask function: {e}")
return "An error occurred while processing your query.", ["No sources available."]
Much like this:

Screenshot: Query Processing
4. Gradio UI
This provides an intuitive Gradio interface for document ingestion and querying.
Here’s how you can implement it:
import gradio as gr
def query_interface(query): try:
logging.info("Processing user query through interface.") answer, sources = ask(query)
return answer, sources except Exception as e:
logging.error(f"Error in query interface: {e}")
return "An error occurred while processing your query.", ["No sources available."]
def main(): try:
logging.info("Launching Gradio UI.")
with gr.Blocks() as ui:
with gr.Tab("Ingest PDF"):
pdf_input = gr.File(label="Upload PDF", file_types=[".pdf"]) ingest_button = gr.Button("Ingest")
ingest_output = gr.Textbox(label="Ingestion Status")
ingest_button.click(ingest, inputs=pdf_input, outputs=ingest_output)
with gr.Tab("Ask Question"):
query_input = gr.Textbox(label="Enter your question:") query_button = gr.Button("Ask")
query_output = gr.Markdown(label="Answer")
source_output = gr.Textbox
source_output = gr.Textbox(label="Sources") query_button.click(query_interface, inputs=query_input, outputs=[query_output,
ui.launch()
except Exception as e:
logging.error(f"Error during UI launch: {e}")
if name == " main ":
main()
Watch this demo for a walkthrough of the RAG-based requirement document analysis application:
In a RAG system, user queries drive information retrieval and generation. Without guardrails, harmful queries could compromise data integrity, expose sensitive information, or cause bias. So, next up, learn about securing your process!
How Do Guardrails Enhance Security in RAG?
To ensure Responsible AI, security guardrails are implemented to filter bad queries and prevent misuse. Here are the various techniques that can be applied:
1. Anonymization
Objective: Automatically removes personally identifiable information (PII) from user queries.
Code Example:
from langchain_guardrails import Anonymizer
anonymizer = Anonymizer()
query = "John Doe's email is john.doe@example.com" filtered_query = anonymizer.anonymize(query) print(f"Filtered Query: {filtered_query}")
2. Restrict Substrings
Objective: Prevents malicious queries containing restricted substrings like profanity or offensive terms.
Code Example:
restricted_substrings = ["badword", "offensiveterm"]
query = "This is a badword test."
if any(substring in query for substring in restricted_substrings):
raise ValueError("Query contains restricted content.")
3. Restrict Language
Objective: Blocks inappropriate or harmful language queries.
Code Example:
from langchain_guardrails import LanguageFilter
language_filter = LanguageFilter(allowed_languages=["en"])
query = "Este es un texto en español."
if not language_filter.is_allowed(query):
raise ValueError("Language not allowed.")
4. Restrict Code Injection
Objective: Prevents injection attacks through malicious code in queries.
Code Example:
from langchain_guardrails import InjectionFilter
injection_filter = InjectionFilter()
query = "SELECT * FROM users;"
if injection_filter.contains_injection(query):
raise ValueError("Potential code injection detected.")
Onwards to the evaluation aspects!
How Can We Ensure High-Quality and Fair RAG Responses?
To ensure the RAG system delivers high-quality and responsible responses, the following evaluation criteria are applied:
1. Fairness
- Goal: To ensure that the responses do not reflect unjust biases based on gender, race, or other attributes.
- Evaluation Method: Test queries are crafted to analyze how the model responds to diverse scenarios.
Code Example:
test_queries = [
"Provide maternity leave requirements.", "Describe policies for paternity leave."
]
for query in test_queries: answer, sources = ask(query)
print(f"Query: {query}\nAnswer: {answer}\nSources: {sources}\n")
2. No Unjust Bias
- Goal: To avoid biases in retrieved content or generated responses.
- Evaluation Method: Regularly audit the vector database for biased documents and incorporate fairness tests in the RAG chain evaluation.
3. Relevance and Accuracy
- Goal: To ensure the response is directly aligned with the query context.
- Evaluation Method: Precision and recall metrics are used for the retrieved documents. They are combined with manual checks for correctness.
4. Handling Ambiguity
- Goal: To generate follow-up questions for incomplete or unclear queries.
- Evaluation Method: Test queries with incomplete context. This is to evaluate if the system provides actionable follow-up questions.
Here’s an example of how you can evaluate a query regarding data privacy compliance using a simple code:
Query: “Explain the requirements for data privacy compliance.”
Code Example:
query = "Explain the requirements for data privacy compliance."
answer, sources = ask(query)
print(f"Answer: {answer}\nSources: {sources}")
Bonus: Visit my GitHub account to unlock more code examples.
Now you’ve learned how to deploy a RAG system locally. Let’s explore the steps to deploy it on-premises.
How Do You Successfully Deploy a RAG System On-Premises?
Here are the steps that you can follow to deploy a RAG system on-premises:
1. Infrastructure Setup
Hardware Specifications Required:
- Servers: 2-3 dedicated physical servers with dual Intel Xeon or AMD EPYC processors, 128GB RAM, and multiple NVIDIA A100 GPUs (if GPU acceleration is required).
- Storage: RAID-10 configured SSDs (at least 4TB capacity) for data reliability and fast I/O.
- Networking: 10Gbps network cards for fast intra-network communication.
To set up the network, follow these steps:
- Create a VLAN specifically for the RAG system to isolate its traffic.
- Use a load balancer (e.g., HAProxy or Nginx) to distribute traffic across multiple servers.
2. Data Storage
Use PostgreSQL or MySQL for metadata storage and Chroma for vector storage.
Here’s how you can maintain encryption:
- Apply AES-256 encryption for data at rest.
- Use SSL/TLS for data in transit.
Then, set up automated database snapshots and back them up to a secure network file system (NFS).
3. Model Hosting
- Install NVIDIA CUDA Toolkit (v11.x or higher) for GPU acceleration.
- Use Docker to containerize the Llama3.2-Vision model and its dependencies.
- Here’s an example of the Docker command:
docker run --gpus all -d --name llama-model -p 8000:8000 deepseek-r1:14b
4. Access Control
- Set up LDAP or Active Directory (AD) for centralized user management.
- Implement role-based access control (RBAC). Example roles include Admin, Data Ingestor, and Query User.
- Log all user activities for auditing purposes.
5. CI/CD Pipeline
Leverage GitLab CI/CD or Jenkins to:
- Automate code builds and deployments.
- Test model updates in a staging environment before moving to production.
- Automate container image builds for deployment consistency.
6. Monitoring and Observability
- Install Prometheus for metric collection and Grafana for visualization.
- Here are some of the metrics that you can monitor:
- Query latency
- GPU/CPU utilization
- Disk I/O performance
- Error rates
Then, set up alerts using Alertmanager for system failures.
7. Security and Compliance
- Apply firewall rules to restrict external access.
- Regularly run vulnerability scans using tools like Nessus.
- Enforce compliance with regulations (e.g., GDPR, HIPAA) by:
- Logging user queries for auditing.
- Implementing data retention policies.
8. Backup and Disaster Recovery
- Use rsync or backup tools to store encrypted snapshots offsite.
- Perform regular disaster recovery drills to ensure backups are recoverable.
9. Scaling and Optimization
- Add more GPUs or nodes if query latency exceeds acceptable thresholds.
- Use caching mechanisms for frequently queried documents or embeddings.
10. User Training and Documentation
- Develop a detailed user manual covering:
– Query best practices
– Error handling - Conduct quarterly training sessions for end-users and IT staff.
- Finally, maintain an internal FAQ repository to address common issues.
That’s it – deployment should be successful by now!
To help you stay ahead, I’ve highlighted key challenges and their solutions next.
Keep reading!
What Challenges Arise When Implementing a RAG System and How to Overcome Them?
Here are some of the common issues and their solutions:
1. Data Quality Issues
- Challenge: Poorly formatted or inconsistent data in client-provided documents.
- Solution: Use advanced preprocessing tools like PyPDFLoader and text splitters to clean and standardize the data before ingestion.
2. Scalability
- Challenge: Managing large volumes of documents and queries efficiently.
- Solution: Employ a scalable vector database like Chroma and optimize storage with techniques such as chunking.
3. Accuracy of Results
- Challenge: Generating relevant and accurate responses.
- Solution: Fine-tune the Llama3.2-Vision model with domain-specific data and use retrieval parameters like “mmr” to enhance context relevance.
4. Integration Complexity
- Challenge: Integrating the RAG system into existing IT workflows and tools.
- Solution: Design modular APIs and provide a user-friendly interface like Gradio for seamless integration.
Before we wrap up, let me share some futuristic enhancements with you.
What’s Next for RAG in Driving Business Success?
Here’s what you can expect:
1. Multilingual Support
- Enhancement: Extend the system to process and respond in multiple languages.
- Business Benefit: Serve global clients more effectively by breaking language barriers.
2. Real-Time Collaboration
- Enhancement: Enable multiple users to interact with the system simultaneously.
- Business Benefit: Boost team collaboration and decision-making efficiency.
3. Advanced Analytics
- Enhancement: Provide detailed analytics on requirement trends and gaps.
- Business Benefit: Help stakeholders make data-driven decisions and plan projects effectively.
The integration of Retrieval-Augmented Generation (RAG) into IT services has the potential to transform how client requirements are processed and managed. By leveraging tools like LangChain, Chroma, and Llama3.2-Vision, IT service providers can offer faster, more accurate, and scalable solutions to their clients. With continuous enhancements, RAG systems can serve as a cornerstone for intelligent project management and client engagement.
Ready to take the next course of action? Reach us at Nitor Infotech for cutting-edge software product engineering solutions.



