Before jumping into CI/CD, let’s look at the motivation behind it. For example, your company is creating an ML-powered service. Being a data scientist, you always try to continuously update the existing ML model.
If you train a better model, how can you say for sure that the service won’t break when you deploy the new model?
Have you not considered having a workflow that automatically tests a pull request from a team member, then merges a pull request when all tests are passed and deploys the ML model to the existing service?

You can create such a workflow with GitHub Actions by creating a CI/CD pipeline.
Why is CI/CD important?
- It helps in eliminating the need for the data scientist in the process of ML pipeline again and again (building>testing>deploying) by automating it.
- The working solution can be delivered to users quickly and frequently with constant improvements
- A continuous feedback loop can be created using CI/CD, to keep models up to date and perfect without constant monitoring, interference, or attention.
- Data scientists will be able to focus more on the core implementation rather than the DevOps work.
CI/CD/CT
Changes can be made by development stage automation using CI/CD. In ML, a model depends on data and hyperparameters and deploying a model to production. CI/CD for software development is straightforward and probably the CI/CD pipeline won’t change a lot in the development phase. The same is not true for ML. Over time, a lot of changes can be seen in ML pipeline building.
CI is also about testing and validating data and models along with testing and validating code and components.
CD is about a system that automatically deploys model prediction service instead of a single software package or service.
CT is new and unique to ML systems, which looks upon automatically retraining and serving the models.
Notebooks are used while starting a ML project, and once a base code of different stages of the ML pipeline is built, the code is pushed to a version control system, and the pipeline is shifted to a CI/CD tool such as CML or Jenkins or TravisCI.
Let’s jump onto the basic tools used for having a ML pipeline.
GitHub Actions and Continuous Machine Learning (CML)
The above two concerns are handled by Continuous Machine Learning (CML).
GitHub Actions make it faster to build, test and deploy your code by automating your workflows. There’s an integrated solution in GitHub called GitHub Actions to build and develop our workflows and then automate the process. To start the workflows using Actions, the events like push, pull request, releases, etc. are utilized as triggers.
Reports can be generated in pull requests with metrics and plots using CML which can help the team to make correct data-driven decisions. Git Actions has a CML plugin. The YAML file consists of CI/CD pipeline and is committed to GitHub along with the code. You can refer to the documentation for creating a simple pipeline.
This blog will demonstrate the set up for running some stages of an ML pipeline, that combines the best models for making a Voting Classifier that predicts if a person will suffer from stroke or not based on past medical history. The models are built using scikit-learn and the dataset is from Kaggle i.e., Healthcare Stroke Prediction dataset. The aim is to run the stages of an ML pipeline using CML while observing the outcome of the pipeline.
Demonstration of a CI/CD Pipeline
Firstly, the data is processed like Numpy, Pandas and Seaborn. After all the preprocessing is done, this preprocessed data is stored as another csv file in the same GitHub repository. Splitting data in an 80-20 manner and then transforming using Standard Scaler, and building models using algorithms like Random Forest, Gradient Boosting, KNN, Decision Tree and Logistic Regression is the first thing to do. These models are evaluated to calculate accuracy, specificity and sensitivity. At the end, after every code commit, observe these metrics and the distribution of the errors. In this case, your false negatives should be less i.e., sensitivity or recall should be greater.
Let’s jump onto our demonstration.
Create a YAML file in “.github/workflows” so that GitHub Actions recognizes that there is a pipeline to run. If you have a workflow in your commit, GitHub Actions will automatically run that workflow. CML provides a docker image with Python3 and the CML library to use the CML capabilities, but we can use Marketplace for Actions to have Python3 and CML.
For this example, preprocess script is being run, then the output data of this script is saved in repository and passed in the training script to create a model out of it. These scripts run one by one using the YAML file.
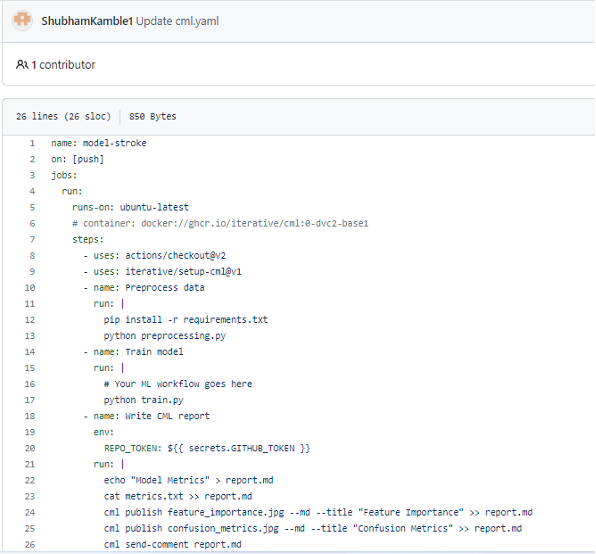
name: – The name of the workflow.
on: [push] – Trigger of the workflow. Our example uses the push event, so when someone pushes a change to repository or merger a pull request, a workflow run will be triggered.
job: – Encapsulate all the jobs that run in the model-stroke workflow.
runs-on: – job is configured to run on the latest OS, which means that the job will run on a fresh virtual machine.
steps: – this will encapsulate all the steps that run under “run” job (line no. 4).
uses: actions/checkout@v2 – specifies that v2 of the actions/checkout action will run. This action goes through your repository which allows you to run scripts or build or test tools.
uses: actions/setup-cml@v1 – In this step, specific version of cml (here it’s v1) will be installed using actions/setup-cml@v1.
run: – the specified command will be executed on the runner
cml publish [options] <image file> – for publishing and displaying an image in a CML report. “>> report.md” does the work of providing an image in a markdown file. Options mentioned: “–md” for producing output in markdown file. “–title=<…>” for title of markdown output.
cml send-comment [options] <markdown report file> – Post a Markdown report as a comment on a commit or pull/merge request.
Following is the metrics code snippet, which is responsible for offline evaluation metrics of Voting Classifier.

The above code changes are made, and the files are committed to the repository. Also you need to save the evaluated metrics in a file to display it using CML. A run of the workflow is started in GitHub Actions by detecting our YAML configuration.

When you click on any workflow run, you’ll see some steps that are run to setup a job, then run actions or setup CML to install everything you need to run the pipeline and check out the latest code. Then, the task of processing and training in our pipeline is run. At last, after completing our task, all resources are cleaned up.

When the job is completed, GitHub Actions in coordination with CML posts a comment and metrics image to the pull request conversation tab. These correspond to the CML commands that were written in the workflow YAML file after executing of the Python script.
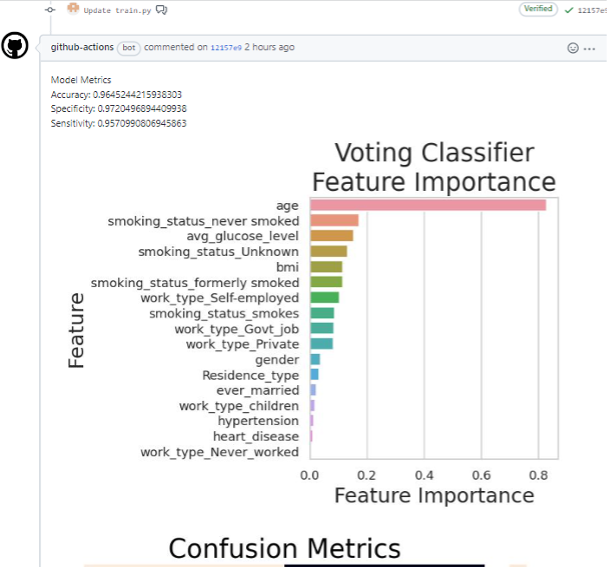
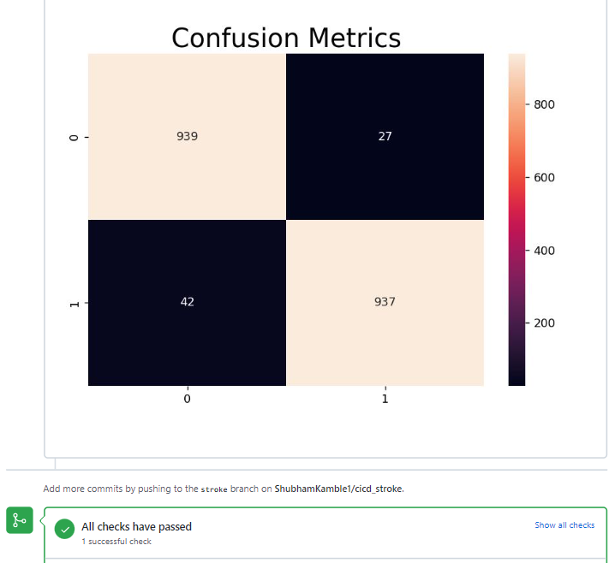
By doing this, whenever we make changes to the dataset/ pipeline/ ML logic, we will get a similar response in the pull request conversation tab only if we pass all checks. If the dataset is not present in GitHub repository, then CML can retrieve the dataset using DVC (Data Version Control) or pull it from any cloud storage.
This pipeline that I demonstrated can be expanded to deploy a docker container to a virtual machine and serve an API.
That’s why it makes a lot of sense to have a workflow that automatically tests a pull request from a team member and deploys the ML model to the existing service!

Propel your business with the advanced capabilities of Machine Learning.
Write to us at Nitor Infotech with your thoughts about the blog you just read, or if you’d like to learn more about our cognitive engineering services.



