
Large Language Models (LLMs) have been revolutionizing the way we interact with technology, from generating creative text to answering complex questions for the past two years now. However, with such immense potential comes a crucial question: how do we assess the performance of these powerful tools? The answer to this lies within “evaluation metrics”.
In this blog, you’ll discover various evaluation metrics for LLMs that measure their effectiveness. You’ll also become acquainted with key metrics relevant to specific applications.
Let me begin by explaining why understanding evaluation metrics is crucial in 2024!
Why do we need evaluation metrics?
Integrating evaluation metrics into your pipeline can significantly enhance your application. With Generative AI evolving, new metrics emerge regularly, offering valuable tools to optimize your use case.
Here are the advantages of incorporating them into our applications:
a. For Developers:
- Objective Measurement: Metrics provide a quantifiable and less subjective way to assess LLM performance compared to relying solely on human judgment.
- Targeted Improvement: They highlight specific areas where the model excels or struggles (for example, grammar vs. factual accuracy), enabling developers to focus their optimization efforts.
- Progress Tracking: They allow developers to track the impact of changes and improvements over time, demonstrating whether the model is truly getting better.
- Benchmarking: Using standardized metrics enables fair comparison of different LLMs or different versions of the same model, aiding in model selection and research.
- Automated Evaluation: You can add many metrics to development pipelines, allowing for constant evaluation and quicker improvements.
b. For Users and Businesses:
- Increased Trust and Reliability: Knowing that the outputs of LLMs have been rigorously evaluated builds trust in its capabilities and the accuracy of its outputs.
- Improved User Experience: LLMs outputs optimized with appropriate metrics are more likely to provide relevant, coherent, and useful outputs. Thus, leading to a better user experience.
- Informed Decision Making: Evaluation metrics provide insights into the strengths and weaknesses of the outputs of different LLMs, helping businesses make informed decisions about which model to deploy for specific tasks.
- Reduced Risk and Bias: Metrics focused on bias detection and fairness can help identify and mitigate potential biases in LLM outputs, reducing the risk of unfair or discriminatory outcomes.
So, by effectively measuring and optimizing LLMs, we can fully unlock their potential to transform industries and everyday life.

Transform your business with our expertise in Generative AI.
Now, let’s head over to the various kinds of metrics that you should be aware of.
Types of Evaluation Metrics for LLMs
Evaluating large language models (LLMs) requires a multifaceted approach, broadly categorized into two types of metrics, namely:
A) Traditional word-based metrics
B) AI-assisted metrics
Let’s delve deeper!
A) Traditional word-based metrics: These offer a foundational approach to evaluating the quality and accuracy of text-based tasks. Here are some traditional word-based metrics borrowed from tasks like machine translation and text summarization:
i. BLEU (Bilingual Evaluation Understudy): This metric is primarily used for assessing machine translation quality. It compares a machine-translated text to one or more human-translated references. It operates on two main principles:
- N-gram precision: It measures how many word sequences (n-grams) in the machine translation match those in the reference translations.
- Brevity penalty: BLEU also accounts for text length, penalizing translations that are much shorter than the reference to prevent high scores for overly brief translations.
These factors combine to give a score that reflects both word accuracy and translation length. A higher BLEU score means a more accurate and fluent translation.
ii. ROUGE (Recall-Oriented Understudy for Gisting Evaluation): This assesses how well an automatically generated summary captures the essential information from the original text. It compares the generated summary to one or more human-written summaries (references) and measures their similarity. A higher ROUGE score generally indicates a more accurate and informative summary.
Note: While useful for measuring surface-level similarities and overlaps, these metrics fall short in capturing the nuances of human language and subjective aspects like coherence, creativity, and factual accuracy.
This limitation led to AI-assisted metrics, used in frameworks like RAGAS, UPTRAIN, and DEEPEVAL. These metrics use trained models or rules for deeper evaluation, focusing on semantics, factual accuracy, and style. Thus, they offer a more thorough assessment of LLM outputs.
B) AI-assisted metrics: These metrics use advanced language models, like transformer-based architectures, for more refined evaluations. These are the specific AI-assisted metrics:
- Factual Accuracy: AI models can be trained on large knowledge bases to verify the factual correctness of generated content. They can cross-reference claims made in the text against known information, helping to identify potential inaccuracies or hallucinations.
- Coherence and Fluency: Transformer models can analyze the logical flow and readability of generated text, assessing whether ideas are presented in a coherent and natural manner. This goes beyond simple grammatical correctness to evaluate the overall quality of writing.
- Semantic Similarity: Advanced language models can measure the semantic closeness between generated text and reference content, capturing meaning beyond just word overlap.
- Style and Tone Consistency: AI can be trained to recognize and evaluate specific writing styles or tones, ensuring that generated content matches desired characteristics.
- Contextual Appropriateness: These metrics can assess whether the generated content is relevant and appropriate given the input context or query.
By leveraging the power of large language models and deep learning, these AI-assisted metrics addresses many of the limitations found in traditional word-based metrics.
In addition to the two-evaluation metrics mentioned above, there’s another important metric you should be aware of.
Keep reading!
RAG-Specific Metrics
RAG-specific metrics rely on various frameworks to evaluate text generation systems that use retrieval, assessing factors like accuracy, content quality, and relevance. These metrics provide a more objective and efficient alternative to manual model evaluation, enabling large-scale testing through automation.
By integrating tools into CI/CD pipelines, developers can automate the evaluation and optimization of RAG applications, ensuring continuous improvements and more reliable performance in real-world use.
RAG applications typically use specific terms for evaluation. The terminology used can differ between various evaluation tools. Here are the common entity definitions:
- Question: Refers to the user’s query. In some of the tools, it may also be referred to as Input or Query.
- Context: Refers to the retrieved document context. Some tools call it Retrieval Context.
- Answer: Refers to the generated answer. Different terms like Actual Output or Response may be used.
- Ground Truth: Refers to manually labeled correct answers. It is used to evaluate the accuracy of the generated answers.
Focusing on a specific framework, RAGAS offers the following metrics:
- Faithfulness: Evaluates the consistency between the Question and Context.
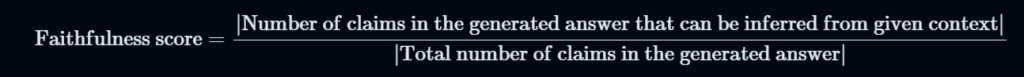
- Answer Relevance: Assesses the consistency between the Answer and Question.

- Context Precision: Checks whether Ground Truth ranks high in Context.

- Context Recall: Evaluates the consistency between Ground Truth and Context.
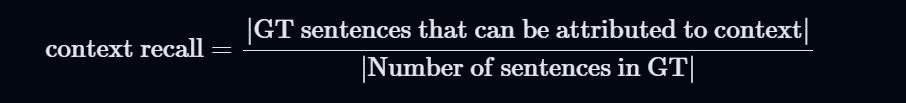
This is how I implemented RAGAS:
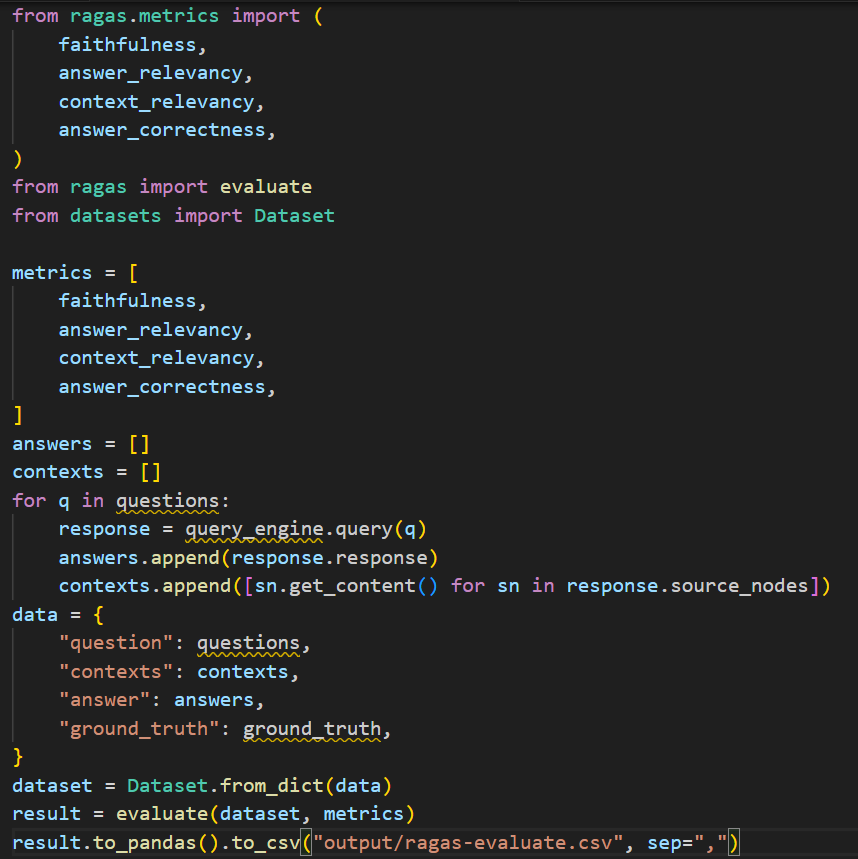
In the above example, we:
- used questions and ground_truth for the input data.
- employed the metrics faithfulness, answer relevancy, answer correctness and context relevancy.
- manually constructed the dataset, adding questions, answers, and contexts.rs, and contexts.
- saved the evaluation results to a local file.
Time to shift gears and compare RAGAS with other evaluation frameworks!
Comparing Evaluation Frameworks
Other frameworks provide similar metrics to RAGAS but with their own unique features. For example, Trulens, DeepEval, and Uptrain provide explanations along with their scores, helping us understand why certain texts are ranked highly or considered irrelevant.
Here is a comparison of four major evaluation metric frameworks:
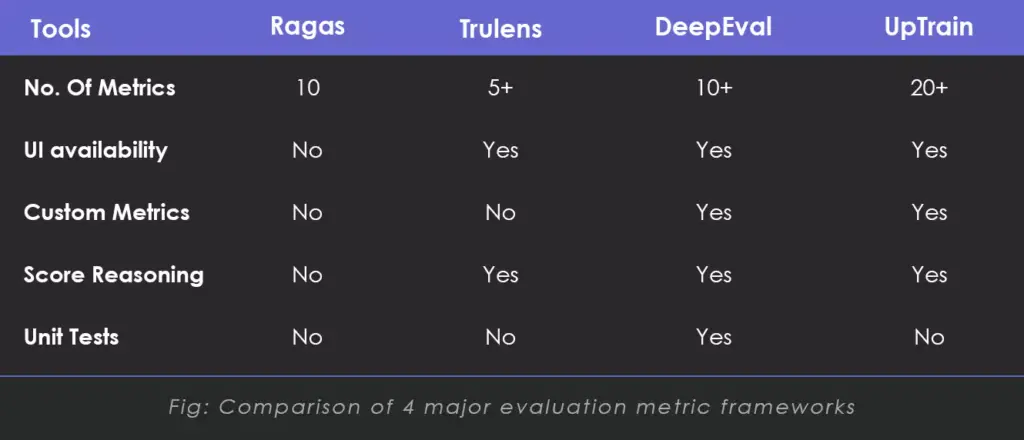
Fig: Comparison of 4 major evaluation metric frameworks
All these frameworks have integrations with Langchain and Llama index which makes it extremely accessible and easy to use. TruLens and Ragas are among the first RAG evaluation tools, with DeepEval and UpTrain emerging later.
These newer tools most probably draw inspiration from the earlier ones, leading to more comprehensive metrics and improved functionality. RAGAS is tailored towards RAG applications but frameworks like DeepEval contain metrics for all kinds of LLM applications such as summarization tasks, Q&A tasks, etc.
For example, here is how the summarization metric of DeepEval works:
The summarization metric checks if your LLM produces accurate summaries of all the original text’s key details. In DeepEval, the original text is the input, and the summary is the output.
The SummarizationMetric score is calculated according to the following equation:
Summarization=min(Alignment Score,Coverage Score)Summarization=min(Alignment Score,Coverage Score)
To break it down, the:
- Alignment_score determines whether the summary contains hallucinated or contradictory information to the original text.
- Coverage_score determines whether the summary contains the neccessary information from the original text.
Here’s the snippet for the above calculation:
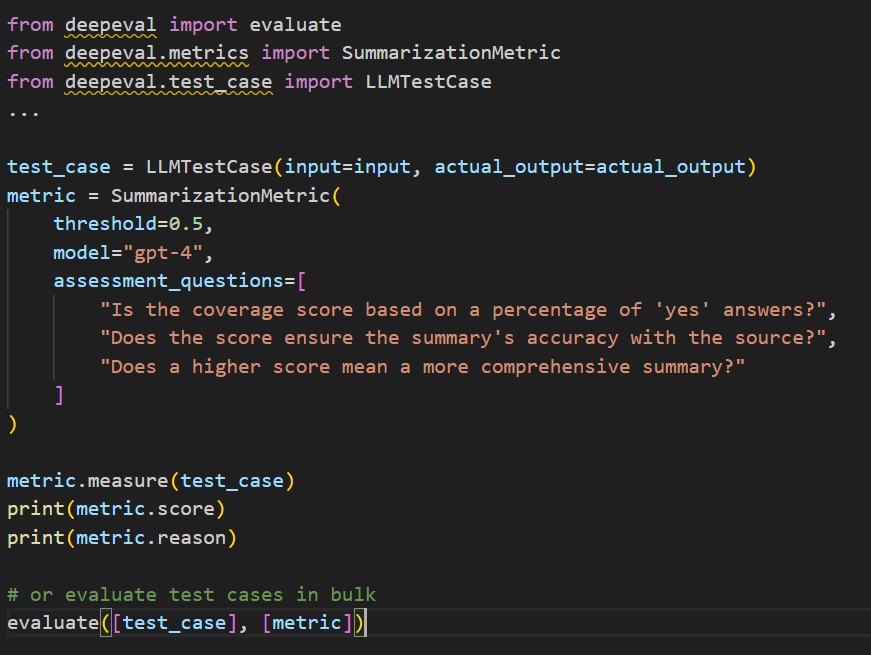
To evaluate the quality of a summary, you can provide a list of yes/no questions that the summary should answer. This list, known as assessment_questions, allows you to focus on what’s most important for your needs.
If you don’t have specific questions, don’t worry—some will be automatically generated during the evaluation. These questions help assess how well the summary covers key information, as indicated by the coverage_score.
In a nutshell, such frameworks will enable developers to advance beyond basic evaluations, addressing complex factors. Their unique features and integration with leading LLM platforms provide crucial insights for developing robust, user-centric applications.
As the field of LLM evaluation continues to evolve, we can look forward to more sophisticated and specialized metrics that enhance transparency and trust in AI. Embracing these advancements will help us build LLMs that truly augment human capabilities and drive positive impact across diverse domains.
I’d recommend you skim through some references once you’re done reading my blog:
1. Introduction | DeepEval – The Open-Source LLM Evaluation Framework (confident-ai.com)
4. Evaluating Large Language Models: A Complete Guide | Build Intelligent Applications on SingleStore
5. LLM Evaluation Metrics for Reliable and Optimized AI Outputs (shelf.io)
Feel free to write to us at Nitor Infotech with your thoughts about this blog.



