
Today, the landscape of technology is buzzing with the remarkable advancements of Generative AI. This innovative technology not only exhibits tremendous growth potential but also offers a ton of capabilities for businesses to maximize their potential. Within GenAI lies a transformative power known as Large Language Models (LLMs) that have taken the whole world by storm.
Read a blog on the evolution of Multimodal GenAI.
In simple words, think of LLMs as a type of AI program that can not only turn your simple idea into a Shakespeare-like writeup with just a few prompts. They utilize deep learning techniques along with human input to proficiently execute a diverse range of natural language processing (NLP) tasks.
Sounds literally like a playground, right?
To get into this field, you should learn how to train LLMs, which is seen as a highly advanced language skill to have.
So, in this blog, I’ll guide you in training LLMs accurately. You’ll also gain insights into fine-tuning methods and inference techniques to develop and deploy strong LLMs, enhancing your business efficiency.
Let’s start!
How to Train Large Language Models (LLMs)?
Training LLMs involves 3 major steps. They are:

Learn about each step as you scroll:
1. Data Preparation & Preprocessing: The success of LLM training hinges on ample high-quality text data. The initial training involves gathering diverse natural language text from sources like Common Crawl, books, Wikipedia, Reddit links, code, and more. This variety enhances the model’s language understanding and generation, thus, boosting the performance and adaptability of LLMs.
As we progress, the data must undergo preprocessing to construct a comprehensive data corpus. The effectiveness of data preprocessing significantly influences both the performance and security of the model.
Note: Key preprocessing steps include – quality filtering, deduplication, privacy scrubbing, and the removal of toxic and biased text. These measures ensure that the training data is clean and high-quality, ultimately enhancing the model’s overall success.
2. Pre-Training Tasks: LLMs can learn language by practicing on large datasets from the internet. They use self-supervised tasks, like predicting the next word in a sentence. This helps them get better at vocabulary, grammar, and understanding text structure. As they keep doing this, the model becomes filled with linguistic knowledge.
3. Model Training: This refers to finding the right settings for a machine learning model. These are the types of training that you can follow:
- Parallel Training: This approach involves dividing the training data into smaller batches namely – data parallelism, tensor parallelism, and pipeline parallelism.
Data parallelism adds more GPU devices to boost throughput. Tensor parallelism splits model parameters across multiple tensors for large models. Pipeline parallelism vertically increases GPU devices to support larger models, often combined with tensor parallelism for optimal performance.
Fig: Parallel Training
- Mixed Precision Training: To speed up LLM training, researchers use 16-bit floating point numbers (FP16) instead of the default 32-bit (FP32) for efficiency. Converting from FP32 to FP16 during training can speed up computations since most model parameters fall within the FP16 range.
To prevent underflow during FP16 parameter updates, we use a technique. It represents updates in FP32 to avoid loss. High-precision updates join a lower-precision model by saving an extra single-precision parameter on the optimizer. Half-precision parameters are used for passes, and update quantities are temporarily kept in FP32 before turning back to FP16, making training faster without losing precision. - Offloading: Moving optimizer parameters (twice the model parameters) from GPU to CPU, despite the CPU’s slower computation, doesn’t slow down training speed. ZeRO3 optimization reduces parameters, gradients, and optimizer size to 1/n on multiple GPUs. Thus, making the load on each CPU lighter when one GPU is connected to multiple CPUs.
- Overlapping: Memory operations are often asynchronous, involving a two-step process where a memory request is sent in advance and served after other computations. During forward propagation in model training, parameters for the current layer are obtained through a gather operation. Asynchronous fetching proactively retrieves parameters for the next layer. After completing forward propagation for a layer, load the GPU with the next layer parameters for immediate successive forward propagation calculations and so on.
- Checkpoint: For efficient backward propagation in model training, we use a checkpoint system. This saves important in-between results while going forward on the GPU. In each transformer block, we do some complicated computations. We save the input for each layer as a checkpoint. During backward propagation, we redo the forward pass for major layers, which saves GPU memory. With a 24-layer transformer, this checkpoint method significantly reduces storage needs from 120 to 24 results.
Now that you know how to train LLMs, let’s explore ways to make them work better on specific tasks while keeping their language skills intact.
Fine-Tuning Large Language Models (LLMs)
LLMs are fine-tuned through 4 main approaches, each uniquely tailored for specific enhancements. Such as:
- Supervised Fine-Tuning (SFT)
- Alignment Tuning
- Parameter-Efficient Fine Tuning (PEFT)
- Safety Fine-Tuning
This table will help you navigate through each of these methods:
| Approach | Supervised Fine-Tuning (SFT) | Alignment Tuning | Parameter-Efficient Tuning | Safety Fine-Tuning |
|---|---|---|---|---|
| Concept | Adjusts LLM on labeled data for a specific task | Fine-tunes LLM for “helpfulness, honesty, and harmlessness | Minimizes computational cost by fine-tuning only a subset of parameters | Enhances safety by addressing LLM risks and ensuring secure outputs |
| Applications | Common for various NLP tasks like sentiment analysis, text classification, and QnA | Addresses issues like bias, factual errors, and harmful outputs in LLMs | Enables LLM fine-tuning on resource-constrained hardware, suitable for training with limited resources | Reduces risks of biased, harmful, or misleading outputs. Thus, promoting the ethical use of LLMs |
| Pros | Effective for specific tasks, improves accuracy and controllability | Promotes responsible and safe LLM usage. Thus, building trust in generated outputs | Reduces costs and computational demands. Thus, allowing efficient fine-tuning on smaller devices | Mitigates LLM risks like bias, factual errors, and harmful content |
| Cons | Requires labeled data preparation, which can be computationally expensive | Requires human feedback data collection and can be more complex to implement | May not match full finetuning’s performance and requires specialized techniques like LoRA or Prefix Tuning | Requires effort to create and curate safety demonstration data |
When we talk about fine-tuning, we must remember that certain frameworks can improve LLM accuracy using GPU, CPU, and NVMe memory. Keep reading to know!
LLM Framework
Here are the various frameworks that can be used:
- Transformers: This is an open-source Python library by Hugging Face for creating models with the Transformer architecture. Its user-friendly API allows easy customization of pre-trained models.
- DeepSpeed: This is an open-source library by Microsoft compatible with PyTorch, optimizing LLM training like MTNLG and BLOOM. It fully supports ZeRO technology, offering custom mixed precision training and fast CUDA-extension-based optimizers.
- BMTrain: This is an advanced toolkit from Tsinghua University for training large models with tens of billions of parameters. It supports distributed training without complex code modifications and integrates easily into existing PyTorch pipelines.
- Megatron-LM: This is a deep learning library by NVIDIA efficiently training LLMs using model and data parallelism, mixed-precision training, and FlashAttention for large transformer models. It achieves up to 76% scaling efficiency with 512 GPUs, significantly improving distributed training speed.
Besides these, Colossal-AI and FastMoE, alongside popular frameworks like PyTorch, TensorFlow, PaddlePaddle, MXNet, OneFlow, MindSpore, and JAX, are widely used for LLM training with parallel computing support.
Let’s now proceed to assess LLMs!
How to evaluate LLMs?
These powerful models bring great capabilities and responsibilities. Evaluation has become more complex, requiring a thorough examination of potential issues and risks from various perspectives. Here are the evaluation strategies you can follow:
1. Evaluation by Static Testing Dataset: To evaluate LLM effectively, use appropriate datasets for validation, such as GLUE, SuperGLUE, and MMLU. XTREME and XTREME-R are good for multilingual models. For multimodal LLM in computer vision, consider ImageNet and Open Images. Utilize domain-specific datasets, such as MATH and GSM8K for mathematical knowledge and MedQA-USMLE and MedMCQA for medical knowledge.
2. Evaluation by Open Domain Question Answering: LLMs improve question-and-answer realism to mimic humans. Evaluating Open Domain Question Answering (ODQA) is crucial for user experience. Mostly, we use datasets like SquAD along with F1 score and Exact-Match accuracy (EM) metrics for evaluation. However, F1 and EM can have issues, leading to the need for human evaluation, specifically when ground truth is not in predefined lists.
3. Security Evaluation: To ensure the potential biases, privacy protection, and adversarial attacks, specific considerations are being followed:
- Security assessments actively address and minimize these biases.
- Detect and Edit Privacy Neurons (DEPN) proposes privacy protection by editing neurons, preventing leaks while maintaining model performance.
- Security evaluations must assess their resistance to attacks and address “jailbreak” risks that could lead to the generation of harmful content.
Did you know?
Automated evaluations (BLEU, ROUGE, BERTScore) quickly assess LLMs but struggle with complexity. Manual evaluations by humans are reliable but time-consuming. Combining both methods is essential for a complete understanding of model performance.
You’ve almost mastered training and evaluating LLMs. To maximize your LLM skills, embrace these final best practices.
Inference Optimization of LLMs: Best Practices
LLM sizes can grow almost 10 times yearly, leading to significant computational and carbon footprint concerns. To address this issue and reduce the cost of training LLMs, you must follow inference optimization.
What’s that?
Well, think of it as a way to make models work better and use less energy. Here, are the techniques you can use:
1. Model Compression: This can be achieved by various types mentioned below:
- Knowledge Distillation: This compresses large models by training smaller ones to mimic outputs. Thus, minimizing divergence to retain essential information and approximate performance.
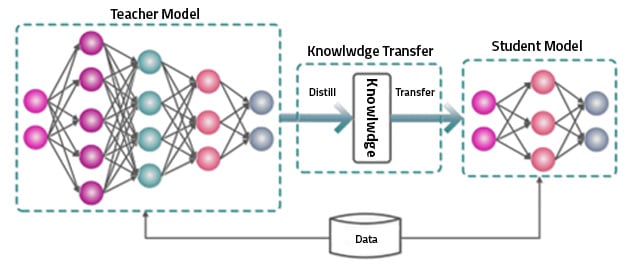
Fig: Knowledge Distillation
- Model Pruning: This compresses model size by removing unnecessary parameters, Thus, employing unstructured and structured pruning for enhanced compression and hardware efficiency.
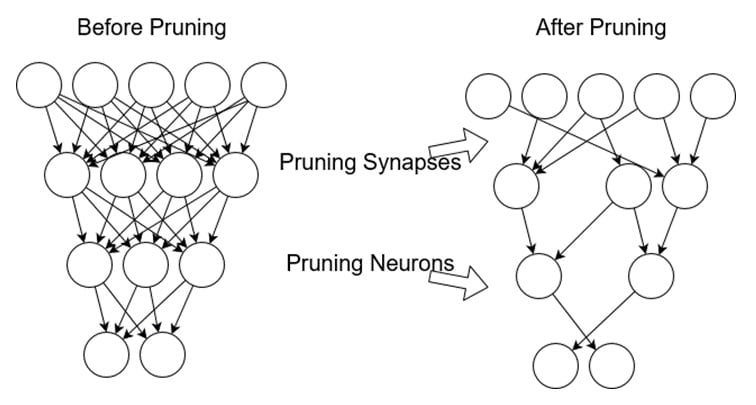
Fig: Model Pruning
- Model Quantization: This minimizes storage and computational costs by reducing the number of floating-point bits, transitioning from high-precision (usually 32-bit) to lower precision data types (float16, bfloat16, int16, or int8) for weights and activations.
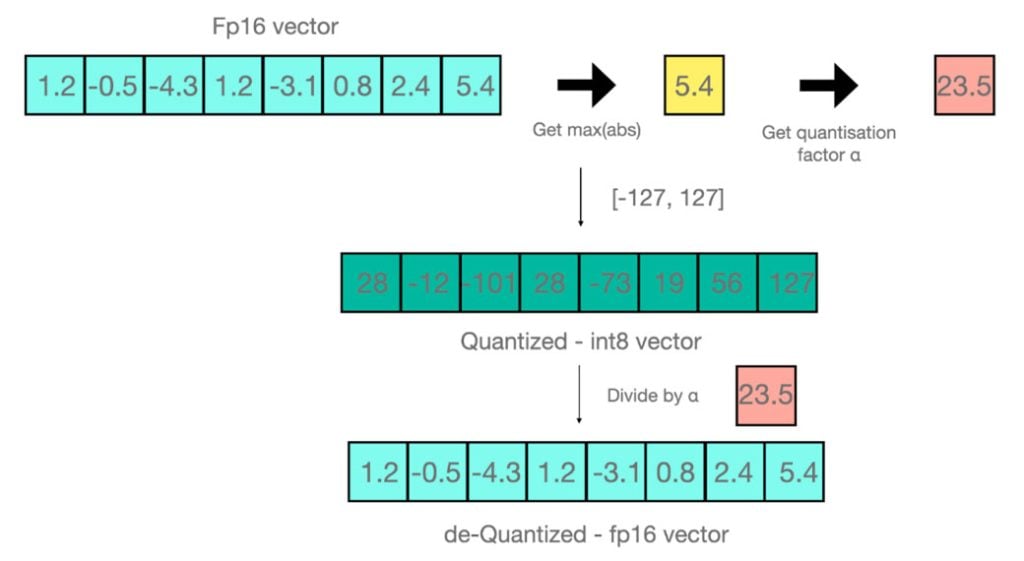
Fig: Model Quantization
2. Weight Sharing: Weight sharing in large language models involves utilizing a common set of parameters across multiple components. By avoiding distinct parameters for each part, this method enhances computational efficiency, mitigates overfitting, and proves beneficial in scenarios with limited data, minimizing the parameters that require learning.
3. Low-rank Approximation: Low-rank decomposition of a large language model involves factorizing its weight matrix into low-rank approximations, reducing computational complexity while retaining essential information. This enables more efficient training and deployment without sacrificing model performance.
Bonus: 2 technical intricacies to remember during inference optimization:
- Memory Scheduling: Memory scheduling strategies address these hardware limitations by efficiently managing memory access patterns during the complex inference phase of models.
- Structural Optimization: Minimizing memory access during inference is crucial. FlashAttention and PagedAttention enhance speed using chunked computation in SRAM, reducing reliance on High Bandwidth Memory (HBM) and boosting overall computational speed.
So, these frameworks serve as fundamental pillars, offering crucial infrastructure and tools for the seamless deployment of LLM models across a spectrum of applications.
For example: ChatGPT marks a significant turning point in the realm of Large Language Models, influencing a variety of tasks. Therefore, businesses must deepen their understanding to navigate this dynamic field and promote innovation in developing Large Language Models to stay ahead.

Discover our GenAI services for maximizing your business efficiency and scalability.
If you wish to learn more about LLMs and other cutting-edge technologies, feel free to reach out to us at Nitor Infotech.



