
Navigating the Multimodal GenAI Cosmos: A Journey Beyond Boundaries
In the expansive field of artificial intelligence, there’s a significant innovation known as Multimodal Generative AI, where text, images, and audio combine to create a comprehensive intelligence system. Picture this AI as an orchestra, where each mode functions like a unique instrument, blending to produce a masterpiece of creativity and comprehension. However, beyond this stellar performance, there’s a journey-a transition from the solitary domains of unimodal AI to the expansive realms of multimodal intelligence.
Unimodal to Multimodal: A Cosmic Evolution
Artificial intelligence, in its infancy, was confined to solitary domains-text-based AI deciphered words, image-based AI analyzed pixels, and audio-based AI decoded soundwaves. These unimodal entities were like stars in the night sky, each shining alone, unaware of the others’ existence.
However, the dawn of generative AI marked a paradigm shift. These solitary stars began to evolve, acquiring the ability to create, imagine, and innovate within their respective domains.
Text-based AI spun narratives, image-based AI painted landscapes, and audio-based AI composed melodies. Yet, they remained isolated-like planets orbiting distant suns, each bound by its gravitational pull.
But evolution is relentless, driving innovation forward. The emergence of Multimodal GenAI signifies a cosmic leap—a convergence of diverse modes of perception and expression. It’s akin to witnessing a celestial alignment, where stars align in perfect harmony, shedding light over the cosmos with their collective brilliance.
Paints a picture, doesn’t it? Hold on to your hats now while we dive deep into the details of this evolution.
- As we’ve seen above, unimodal GenAI laid the groundwork, specializing in text, images, or audio independently.
- Following that, researchers experimented with combining outputs from separate unimodal models resulting in the shift to convey learning facilitated knowledge transfer between different modalities. This enabled models to leverage pre-trained components for diverse tasks.
- As neural architectures evolved, multimodal fusion techniques emerged which meant simultaneous processing of multiple modalities within a single model.
- And then, with advancements in deep learning and neural network architectures, multimodal generative AI came into fruition, seamlessly integrating text, images, and audio to unlock a new frontier of creativity and understanding.
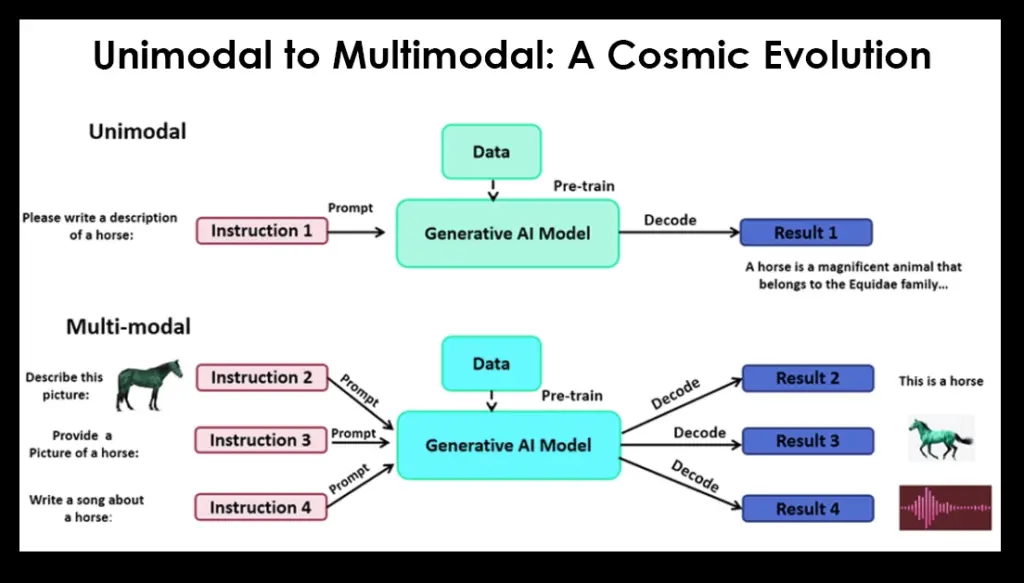
The diagram above highlights the difference between unimodal and multimodal models, where each represents different stages. The unimodal model has separate models for text, image, and audio generation. The multimodal model on the other hand shows how these separate models are merged into a single model capable of generating content across multiple modalities simultaneously. The result, you guessed it, text, visual, and audio depicting that our input image is in fact a horse!
Exploring the technology behind Multimodal GenAI
Multimodal GenAI operates on the principle of fusion—combining text, images, and audio to enhance understanding and creativity. At its core lies deep learning, a branch of artificial intelligence that mimics the human brain’s neural networks. Through a process known as multimodal fusion, these networks integrate information from different modalities, allowing the AI to comprehend and generate content across multiple domains.
- Text-to-Image Generation
One of the key functionalities of Multimodal GenAI is text-to-image generation. Using advanced neural networks such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), the AI translates textual descriptions into visual representations. This process involves encoding the text into a semantic space and decoding it into an image, effectively bridging the gap between language and vision. - Image-to-Text Generation
Conversely, Multimodal GenAI can also generate textual descriptions from images—an invaluable tool for tasks such as image captioning and content generation. By leveraging techniques like image feature extraction and natural language processing (NLP), the AI analyzes visual content and generates coherent textual descriptions, providing insights into the underlying visual semantics. - Audio-to-Image Generation
In addition to text and images, Multimodal GenAI can also generate images from audio inputs—a feat achieved through the fusion of audio processing and image synthesis techniques. By converting audio waveforms into spectrograms and leveraging generative models like generative adversarial networks (GANs), the AI transforms soundscapes into visual representations, opening new avenues for creative expression and accessibility.
Applications and Implications of Multimodal GenAI
The applications of Multimodal GenAI are diverse. From content creation and media synthesis to accessibility and assistive technology, the potential uses are limitless. Imagine a world where visually impaired individuals can experience visual content through audio descriptions or where artists can seamlessly translate their creative vision across different modalities. Take a look at these important applications:
- Enhanced Content Creation: Multimodal GenAI can generate text, images, and videos simultaneously. This allows creators to produce rich multimedia content quickly and efficiently.
- Improved Communication Tools: These systems can analyze both text and visual inputs. This means better understanding and responses in chatbots as well as virtual assistants.
- Personalized Learning Experiences: In education, multimodal GenAI can tailor lessons based on students’ needs. It can combine written material with interactive visuals to enhance engagement.
- Advanced Healthcare Solutions: In medicine, it can process and analyze patient data from various sources. This aids in diagnostics and personalized treatment plans.
These applications show the versatility of multimodal GenAI across different fields, driving innovation and improving user experience.

Explore how Nitor Infotech helped a healthcare organization by leveraging GenAI to stratify patients as per their risk score.
However, with great power comes great responsibility. As we navigate the Multimodal GenAI realm, we must remain vigilant, mindful of the ethical implications and societal impact of our creations.
Issues such as bias, privacy, and misinformation must be addressed proactively, ensuring that the benefits of AI are shared equitably among all.
So, as we embark on this journey, let us tread lightly, guided by the light of innovation and the principles of ethical stewardship, for the Multimodal GenAI cosmos holds the promise of a brighter, more inclusive future for all.
If you enjoyed this read, do reach out to us at Nitor Infotech to share your thoughts and explore our GenAI services to tap into the potential of this magnificent technology.



