
In today’s fast-paced, data-driven world, industries are continuously inundated with vast and complex datasets that demand effective management and processing. As businesses strive to remain competitive, the reliance on third-party APIs for fetching XML data has become a common practice.
However, this approach introduces a new layer of complexity, particularly when it comes to ensuring scalability, optimizing performance, and efficiently utilizing resources. These challenges can strain traditional methods, often leading to bottlenecks that hinder operational efficiency, slow down decision-making processes, and ultimately impact the overall growth trajectory of a business. So, addressing these issues is crucial for organizations aiming to leverage data as a strategic asset.
To do so, in this blog, I’ll share an efficient approach for handling massive XML datasets. You’ll learn practical strategies that you can use to overcome big data challenges and improve performance in your own projects.
First, I suggest you learn about the major roadblocks that you need to overcome!
Challenges of Processing Large-Scale XML Data
Imagine the need to process information for over a million hotel properties. The data may be provided by a third-party API in XML format. However, here are several challenges that make this task daunting:
- Paginated Responses: Each response from the API is limited to 1,000 records, meaning multiple requests are needed to retrieve the full dataset. This adds complexity to managing the data flow, ensuring consistency, and avoiding duplication across requests. This can slow down the process.
- Detailed Data: The data for each hotel property includes multiple details like room count, amenities, and geolocation, which require careful parsing and validation. Handling diverse data types and ensuring accurate integration increases the complexity of the processing task.
- Continuous Data Retrieval: Since each API response provides a URL for the next page, continuous retrieval is necessary. This creates an intricate flow of requests, where tracking progress and handling errors are critical to prevent data gaps or interruptions.
- Massive Dataset: The dataset spans over 1.2 million records, requiring substantial resources for storage, transfer, and processing. Managing such a large volume demands advanced techniques to maintain performance and avoid slowdowns or crashes.
- Salesforce Limitations: With a daily limit of 300,000 records for updates, Salesforce creates a bottleneck in processing large datasets. This constraint limits the volume of data that can be ingested or updated at once. This forces businesses to process data in smaller chunks. As a result, managing the pace of data updates becomes challenging, particularly when dealing with millions of records that need to be updated or inserted within a short time frame.
Processing such large amounts of data sequentially would be too slow and use too many resources. To tackle these challenges, you need to use asynchronous programming, distributed computing, and optimized data processing techniques.

Discover how our cutting-edge data analytics solutions can reshape your manufacturing business.
Before getting to the solution, I want to highlight some of the libraries that you can analyze, up next!
Analyzing XML Processing Libraries
Analyzing XML processing libraries is a crucial step in selecting the most efficient and appropriate solution for your project’s unique needs. This involves evaluating various libraries, their attributes and their ability to handle large or complex XML data structures.
By carefully assessing the available options, you can identify the library that not only meets your technical specifications but also supports the scalability of your project. This will ensure that your solution remains adaptable as data volumes increase, providing the flexibility to accommodate future growth without compromising performance.
Here is the list of libraries that I analyzed:
1. XML:
- It processes XML data as it receives it, without building a complete in-memory representation of the document.
- It uses the Expat parser, which is a non-validating XML parser written in C.
- The standard library’s XML module is ideal for basic XML processing needs, offering simple XML parsing and manipulation capabilities. It’s particularly useful when advanced features, such as XPath or complex data handling, are not necessary. For straightforward tasks, it provides an efficient and lightweight solution.
2. BeautifulSoup:
- It relies on Python’s built-in html.parser or xml.etree.ElementTree for XML parsing. While these are good general-purpose parsers, they are typically slower than lxml.
- It doesn’t have built-in XPath support. You would need to use third-party libraries or implement your own methods for navigating the XML tree, which can be slower.
- It also employs a DOM (Document Object Model) approach for XML processing, which involves loading the entire XML document into memory. However, its implementation might be less optimized compared to other libraries like lxml, which can handle larger datasets more efficiently.
3. Simple Salesforce:
- It offers limited scalability for handling large datasets. This can result in slower processing times as the volume of data increases.
- Bulk operations tend to be slower due to API call limits, making it less efficient for large-scale data updates or insertions.
4. Salesforce Bulk API:
- For large datasets that exceed API limits or require efficient data transfer, the Bulk API is the way to go.
- If you need to process large volumes of data in batches, the Bulk API allows for asynchronous processing, improving performance and reducing API call overhead.
- When migrating large amounts of data between Salesforce and other systems, the Bulk API is well-suited for efficient data transfer.
Here’s a brief comparison of the libraries mentioned above based on my analysis:

Quick Note: Easily integrate Salesforce data with Azure Data Factory to improve efficiency and make better data-driven decisions.
| Feature | lxml (Lexical XML) | BeautifulSoup | Standard Library’s xml |
|---|---|---|---|
| Execution Time | Fastest; parses 3k records in 30 secs | Slower than lxml; parses 3k records in 1.5 mins | Slowest; parses 3k records in 2 mins |
| Scalability | Highly scalable | Less scalable for large datasets | Least scalable |
Onwards toward the solution!
How to Efficiently Process Large and Complex XML Datasets?
Managing large and complex XML datasets requires more than just a basic processing strategy—it demands a thoughtful, well-structured approach to ensure efficiency and scalability. At Nitor Infotech, we’ve refined our methods to address the unique challenges posed by XML data. We’ve done this by focusing on solutions that optimize performance and streamline workflows.
By adopting a combination of sophisticated technologies and proven design patterns, we’ve built a system that can handle the intricacies of XML data. It ensures smooth integration and processing.
Here are the specifics we used in our case that you can also apply to your project:
1. Asynchronous Data Retrieval Layer
- Technology used: aiohttp (asynchronous HTTP client for Python)
- Purpose: Enables concurrent API requests, significantly reducing data retrieval time.
- Implementation: Utilizes coroutines to enable non-blocking I/O operations.
2. XML Processing Layer
- Technology used: lxml library
- Purpose: Efficient parsing and extraction of relevant data from XML responses.
- Optimization: Utilizes C-based implementation for improved performance.
3. Data Flow Management
- Pattern followed: Producer-Consumer with asyncio
- Components required:
> asyncio.Queue: Manages data flow between producer and consumers
> asyncio.Event: Signals process completion
- Implementation process:
```python queue = asyncio.Queue(maxsize=100) stop_event = asyncio.Event() producer_task = asyncio.create_task(producer(queue, stop_event, list_of_giata_id)) consumers = [asyncio.create_task(consumer(queue, stop_event, url, username, pwd)) for _ in range(number_of_consumers)] await asyncio.wait([producer_task, *consumers]) ```
4. Distributed Data Processing
- Technology used: PySpark
- Purpose: Enables distributed computing for large-scale data transformations.
- Optimization process:
> In-memory data processing
> Strategic data partitioning
> Caching of frequently accessed DataFrames
5. Parallel Processing Layer
- Technology used: concurrent.futures.ThreadPoolExecutor
- Purpose: Utilizes multi-core processing for CPU-bound tasks.
- Implementation process: Requires parallel execution of data transformation and analysis tasks.
6. Data Loading and Integration
- Technology used: Salesforce-bulk library
- Purpose: For efficient bulk loading of processed data into Salesforce.
- Optimization process: Requires custom batching mechanism to handle Salesforce’s 10,000 record limit per bulk operation.
Next up, follow the architectural diagram and learn about the considerations for constructing a resilient and efficient data pipeline.
Architecture, Considerations, and Benefits of Efficient Data Pipeline
Here’s what the solution’s architecture looks like:
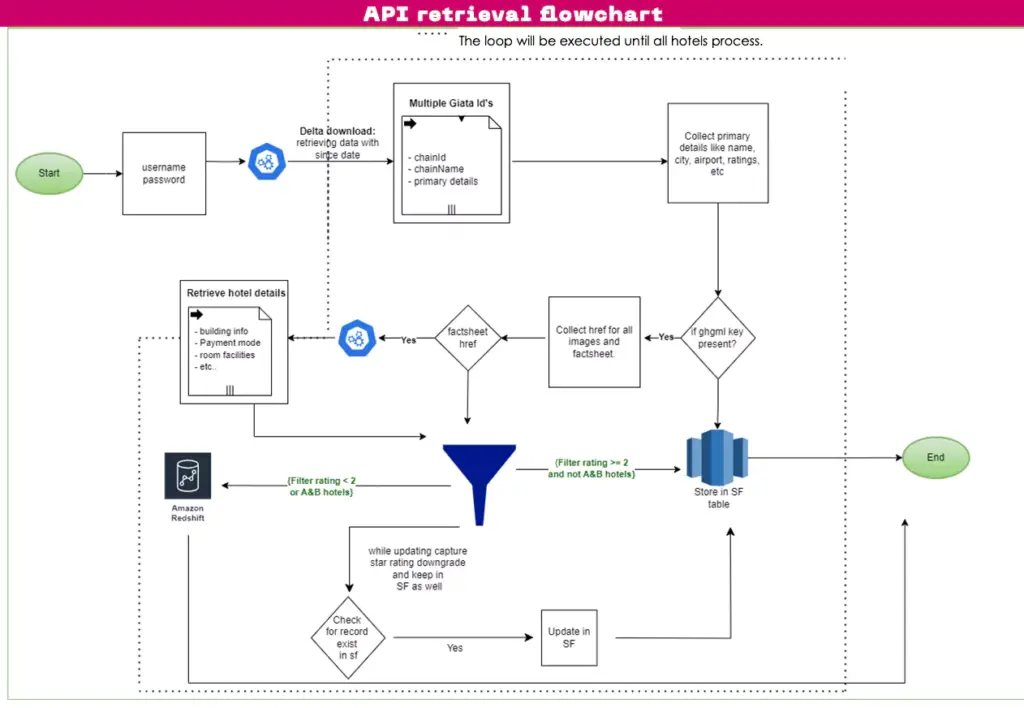
Fig: API retrieval flowchart
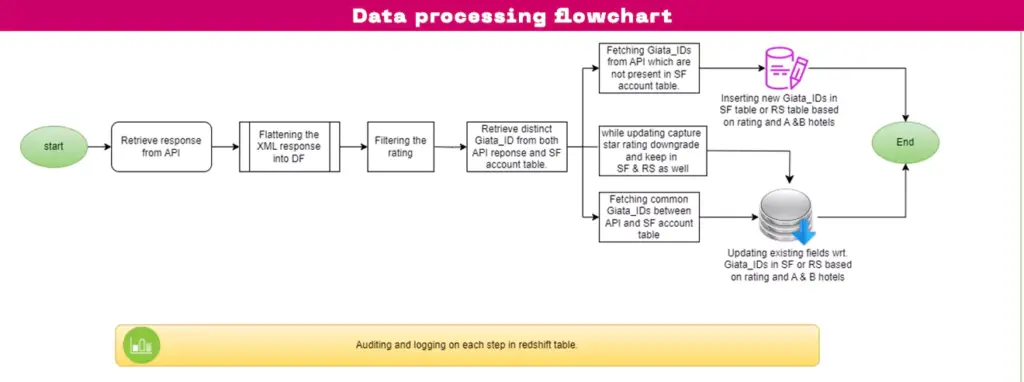
Fig: Data processing flowchart
Here are the advanced architectural considerations that you should keep in mind:
1. Fault Tolerance and Error Handling:
- Implement robust error handling and retry mechanisms at each layer.
- Use circuit breakers to manage failures in external service calls.
- Implement data checkpointing for long-running processes.
2. Monitoring and Logging:
- Integrate with a centralized logging system (for example, ELK stack).
- Implement detailed metrics collection for performance analysis.
- Set up real-time alerting for critical failures or performance degradation.
3. Data Validation and Quality Assurance:
- Implement schema validation for incoming XML data.
- Perform data quality checks at various stages of the pipeline.
- Maintain audit trails for data lineage and compliance purposes.
4. Scalability and Resource Management:
- Design for horizontal scalability to handle increasing data volumes.
- Implement dynamic resource allocation based on workload.
- Utilize containerization (for example, Docker) and orchestration (for example, Kubernetes) for easier scaling and management.
By adopting the above solution and architectural approach, you can avail the following benefits:
- Improved Performance: Asynchronous processing significantly reduces processing time by allowing multiple operations to occur concurrently, unlike the sequential nature of synchronous processing. This leads to faster data handling, minimizing delays and ensuring that large datasets are processed more efficiently.By reducing bottlenecks, businesses can achieve quicker response times. This enhances overall system performance and user experience.
- Efficient Resource Utilization: By enabling multiple consumers to process data simultaneously, resources are utilized to their fullest potential, avoiding idle time and improving throughput. This concurrent handling of tasks ensures that CPU, memory, and network bandwidth are optimally used, resulting in a more efficient system. Effective resource management also leads to cost savings, as the same hardware can handle larger workloads without the need for additional investment.
- Enhanced Scalability: The architecture allows for dynamic scaling by adjusting the number of consumers based on the current data load and hardware capabilities. This flexibility ensures that the system can grow alongside your data needs, maintaining performance levels as volumes increase. Scalability is crucial for businesses expecting growth. This is because it prevents system overloads and ensures smooth operation even during peak demand periods.
- Boosted Flexibility: The producer-consumer pattern supports seamless integration with other data processing pipelines. This allows for a modular and adaptable system design. The flexibility makes it easier to incorporate new technologies or modify existing workflows without disrupting the entire system. It also supports diverse data sources and formats, making it a versatile solution for evolving business requirements and technological advancements.
This approach showcases a robust integration of advanced technologies designed to efficiently handle large hotel property datasets. By employing asynchronous programming, PySpark, and the Salesforce Bulk API, it becomes feasible to manage large volumes of data with greater agility and performance.
Final Takeaway
To sum up, for those planning to implement a similar strategy, the first step is to conduct a comprehensive assessment of your current data infrastructure. This step will help you identify any inefficiencies or bottlenecks in critical areas like data retrieval, processing, or storage. By pinpointing these areas, you can prioritize improvements that will have the greatest impact on performance.
Once these inefficiencies are addressed, focus on selecting technologies that align with your specific data processing requirements, ensuring they integrate smoothly with your existing systems to optimize workflow and functionality.
It’s also crucial to equip your team with the right skills and knowledge to effectively leverage these tools, as this will maximize their potential and improve overall productivity. Beyond that, continuous monitoring and optimization are key to keeping your data pipeline agile and responsive to changing requirements. As data volumes and complexity grow, maintaining peak performance requires regular adjustments and improvements.
So, by refining your approach over time, you can ensure that your system remains scalable, efficient, and aligned with your long-term business goals, driving sustained success.
Bonus: Wish to learn more about our big data and leading-edge software development services? Write to us with your thoughts today.
To efficiently process large and complex XML datasets, follow these steps:
- Conduct a thorough assessment: Evaluate your current data infrastructure to identify areas where efficiency can be improved, such as data retrieval, processing, or storage.
- Adopt the right technologies: Focus on selecting and adopting technologies that best suit your specific data processing needs. Thus, ensure they integrate seamlessly with your existing systems.
- Equip your team with the right skills: Invest in training your team to leverage these tools effectively, maximizing their potential and boosting overall productivity.
- Focus on continuous monitoring and optimization: Regularly monitor your data pipeline and optimize it to adapt to evolving data requirements. Thus, ensure responsiveness to changing business needs.
- Ensure scalability and alignment with long-term goals: Regularly refine your approach to maintain peak performance as data volumes and complexity grow. Thus, ensure your system remains scalable and aligned with your long-term business objectives.



