
Real-time data synchronization is becoming increasingly important in today’s fast-paced world, as organizations seek to make faster and more informed decisions based on the latest information. When talking about traditional batch processing methods, they are no longer sufficient as they introduce delays in data processing and analysis. While some of you may prefer MongoDB and Azure SQL to fulfill your database requirements, relying solely on them can lead to synchronization issues. This is where Apache PySpark’s Spark Streaming comes into play.
In this blog, we will explore the challenges of synchronizing data between MongoDB and Azure, and how to overcome them using Spark Streaming. I’ll also explain why Spark Streaming is a popular choice for real-time data processing. Additionally, I’ll walk you through one of our recent projects to demonstrate the steps we took to achieve seamless data synchronization.
Enjoy the read!
Challenges & Considerations in Synchronizing MongoDB and Azure SQL
There are several challenges that can arise when synchronizing data between MongoDB and Azure SQL, such as:
1. Differences in Data Structures: MongoDB is a NoSQL database that handles unstructured data, whereas Azure SQL is a relational database designed for structured data. This fundamental difference in data structure can pose challenges when mapping and transforming data between the two systems. The varying schema designs and data models require careful consideration to ensure compatibility and consistency during synchronization.
2. Data Volume and Velocity: Real-time data synchronization involves handling large volumes of data with high velocity. As data continuously flows into both databases, ensuring efficient and timely synchronization becomes crucial. Managing the constant influx of data and maintaining synchronization performance can be challenging, especially when dealing with high-traffic applications or complex data transformations.
3. Data Consistency and Integrity: Maintaining data consistency and integrity across both databases is vital. Any discrepancies or inconsistencies between MongoDB and Azure SQL can lead to data quality issues and impact business operations. Ensuring that data is accurately synchronized, without loss or corruption, requires robust error handling, conflict resolution mechanisms, and thorough testing.
4. Security and Access Control: Data security is a critical concern when synchronizing data between databases. Organizations must implement appropriate security measures to protect sensitive information during the synchronization process. This involves:
- protecting network connections
- encrypting data as it travels
- enforcing access controls to prevent potential data breaches
5. Performance and Scalability: As the volume of data grows, the synchronization process needs to scale accordingly. Ensuring optimal performance and scalability can be challenging, especially when dealing with large datasets or complex data transformations. So, organizations must carefully design their synchronization architecture to handle increasing data loads and maintain synchronization efficiency.
6. Oversight and Issue Management: Successful real-time data synchronization relies on vigilant monitoring and strong error handling processes. Organizations need to proactively monitor the synchronization process, identify any errors or failures, and promptly address them to minimize data inconsistencies and downtime. Implementing effective logging, alerting, and automated error recovery processes are essential for maintaining a reliable synchronization workflow.
To address such roadblocks, read how Spark Streaming steps up into the picture next!
What makes Spark Streaming a game-changer for real-time analytics?
Apache PySpark offers a powerful framework that allows you to process and analyze streaming data using the same Spark API as batch processing. This is known as Spark Streaming. It provides a unified approach to both batch and stream processing, making it an ideal choice for real-time data synchronization between MongoDB and Azure SQL.
Here are some reasons why Spark Streaming is helpful in real-time data synchronization:
1. Fault-tolerant and scalable: Spark Streaming is designed to be fault-tolerant and scalable, making it an ideal choice for real-time data synchronization. It can handle large volumes of data and can automatically recover from failures, ensuring that data is synchronized accurately and efficiently.
2. Unified API: It provides a unified API for both batch and stream processing, making it easy to integrate with existing Spark applications. This allows us to use the same codebase for both batch and stream processing, reducing development time and costs.
3. Real-time data processing: It allows us to process data in real-time, making it an ideal choice for real-time data synchronization. This enables us to synchronize data between MongoDB and Azure SQL as soon as it is available, ensuring that data is up-to-date and accurate.
4. Support for multiple data sources: It supports a wide range of data sources, including MongoDB and Azure SQL. This allows us to easily synchronize data between these two databases and other data sources using a single framework.
5. Rich set of transformations: It provides a rich set of transformations that allow us to manipulate and transform data as it is being synchronized. This enables us to perform complex data transformations and aggregations, as well as filter and clean data, before synchronizing it between MongoDB and Azure SQL.

Learn how we helped a leading electronics manufacturer save 40% on data management time with an advanced enterprise analytics platform.
Implementing Real-Time Data Synchronization using PySpark
To effectively synchronize data between MongoDB Atlas and a relational database, the following approach will be beneficial:

Fig: Data Synchronization Approach using Spark Streaming
MongoDB offers change streams, enabling real-time monitoring of document updates within a collection and immediate reaction to those changes. To process these change streams using Spark, we can use the Spark-Mongo connector. This connector allows us to establish a connection between MongoDB and Spark, enabling us to read and process the change streams.
Next, we’ll also establish a connection with Azure SQL using the appropriate driver. Once we have processed the change streams, we can use the data to generate SQL queries to fire on an Azure SQL database. This enables us to synchronize data in real time between Azure SQL and MongoDB.
In parallel, we’ll use Spark Write Stream to store the unprocessed MongoDB change stream in Azure Blob Storage. To do this, we’ll first mount the Azure Blob Storage container to the Databricks cluster, and then use Spark Write Stream to write the data seamlessly.
Finally, we can use PowerBI to connect to the Azure SQL database and create visualizations on the real-time data. This allows us to gain insights into the data and make informed decisions.
Let’s break the above theory into simpler bits!
Here are the prerequisites needed for the process:
- MongoDB on Atlas
- Databricks cluster for Spark Streaming
- Azure blob container
- Azure SQL database
To implement the real-time data synchronization process between MongoDB and Azure SQL, we followed these steps:
Step 1: While configuring the Spark session, first we integrated MongoDB and Spark using the Spark-Mongo connector jar using this code:
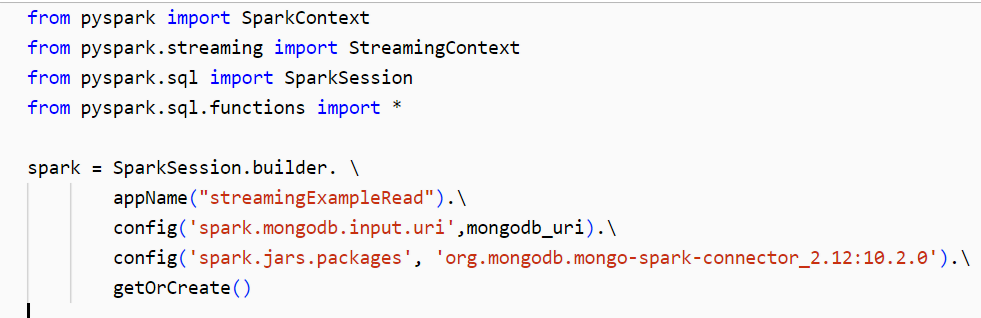
Step 2: Then we mounted an Azure blob container to the Databricks cluster using this command:

Step 3: Next, we established a connection to an Azure SQL database using the pyodbc module.

Step 4: We then defined the JSON schema for the MongoDB change stream as follows:

Step 5: After establishing the connection, we initiated the reading of MongoDB change streaming using the readStream method.

Step 6: Next, we wrote the unprocessed MongoDB change stream into Azure blob container.

Step 7: Then, we extracted the necessary field from the raw MongoDB change stream.

Step 8: Finally, we wrote a function that generates a SQL query and executes it on a SQL database. We then, passed the processed MongoDB change stream to this function, which synchronized the MongoDB database with the SQL database.

Here are some use cases where this approach may be a better fit: –
- When data is inserted, updated, or deleted in a MongoDB database at a very high volume and velocity.
- When data should be sunk across databases in near real-time.
- When reports and visualizations should be updated in near real-time.
Performance, Costing, and More
Let’s dive deeper into the performance and cost aspects of the solution, as they hold significant importance in shaping the design and implementation of our solution.
A. Here are the details of the computational resources used during the implementation process:

B. This table highlights the synchronization time required (performance) for different numbers of records:
| No. of records inserted in MongoDB | Time taken to Sync in Relational Database |
|---|---|
| 1000 | 30 sec |
| 10000 | 2 mins |
| 50000 | 8 mins |
| 100000 | 16 mins |
C. Given below are the monthly and yearly costs for each of the services availed to conduct this process:
| Services | Monthly cost | Yearly cost |
|---|---|---|
| Azure Databricks | $1268.01 | $15216.12 |
| Azure SQL database | $320.76 | $3849.12 |
| Azure storage account | $167.25 | $2007 |
| Total | $1756.02 | $21072.24 |
*This is estimated costing based on the above resources.
D. Pros & Cons from the Process
Be sure to consider these advantages and drawbacks during the implementation process:
Pros:
- Regardless of the number of change streams or their rate of generation, Spark will promptly synchronize these changes to the RDBMS.
- Running on a Databricks cluster, Spark can dynamically scale the cluster up as data volume and velocity increase, and scale it down when data inputs are low.
Cons:
- A limitation of the Mongo-Spark connector is that it can only listen to changes from a single collection at once. However, this can be addressed by configuring a separate Read Stream for each collection, allowing Spark to simultaneously monitor changes across multiple collections.
In this approach, we focused on boosting performance by cutting down synchronization time and handling large volumes of data quickly. We simplified things by consolidating the process into a single stage between the source and target databases. In a nutshell, PySpark gave us the flexibility we needed for connectivity and data transformation processing within the solution.
In the upcoming blog of this series, we’ll delve into an alternative solution to address this same problem. Specifically, we’ll introduce a fresh approach centered around leveraging Azure services. This new approach will encompass a robust solution hosted entirely on the Azure cloud platform.
Sounds exciting?
So, stay tuned for the read, and till then reach out to us at Nitor Infotech with your thoughts about this blog.



