Artificial intelligence | 27 Mar 2024 | 20 min
Artificial intelligence | 27 Mar 2024 | 20 min

Finally, the robots (transformer models) will do the heavy lifting! 😀
I’m not saying this, but a recent study has shown that 44% of business leaders are willing to embrace Generative AI for their growth and advancements in 2024. This means manual tasks are about to get replaced to save resources and amp up productivity. So, it’s high time for organizations to familiarize themselves with the knowledge of GenAI and LLMs (Large Language Models) like ChatGPT and its internal working.
If not already aware, GenAI comes in all types of forms (variational autoencoders, diffusion models, generative adversarial networks, and transformer models) and you must learn it all to use its capabilities to the fullest to stay at par with the latest industrial advancements. Enjoy reading about these too!
Today, I’ll focus on the transformer model, exploring its unique features that set it apart from other AI models. By the end of this blog, you’ll not only understand how it works but also feel confident enough to train your very own model.
Sounds like a fun activity?
So, let’s dig straight in!
The transformer model was first introduced in “Attention is All You Need”, a paper written by Ashish Vaswani, a member of Google Brain in 2017.
In the world of deep learning, transformer models can be defined as a game-changer for processing sequences, like sentences in natural language. They don’t rely on the older methods of convolutions and recurrence. Instead, they use an “attention” mechanism to understand which parts of the input are most important when processing each part of the output. This allows them to better grasp the context and meaning of a sentence, even when words are far apart.

Transformer models are widely used in AI for tasks like summarization, translation, and text generation. This means you can now translate entire sentences at once, preserving meaning and context. Also, they can help you create relevant text, used for writing articles, poetry, and even generating code.
With these special abilities, your organization can certainly achieve much more!
Transformers are like super-fast readers, processing input all at once, which makes them efficient for training and inference. Unlike older methods that rely on adding more GPUs for speed, transformers can handle tasks faster. You can get an idea of its capabilities by understanding its various kinds.
There are three main types of transformer models:
When prompted: "Once upon a time," The model will generate this output: "there was a little girl who lived in a cottage."
When prompted: "The cat sat on the _____" The model may predict this output: "mat.”
When prompted: Translate this english sentence "How are you?" Into French. The model might translate it as: "Comment ça va?"
Now that you know the basics, let me help you understand how these models work.
The transformer model comprises two primary components: the encoder and the decoder.
1. Encoder: This component processes input sequences, converting a sentence from one language into a format that the model can understand.
2. Decoder: This component translates the transformed format into a sentence in another language.
Both the encoder and the decoder are composed of multiple blocks. The input sentence passes through the encoder blocks, with the output of the final encoder block serving as the input features for the decoder. Similarly, the decoder comprises multiple blocks.
It appears as shown below (where “Nx” represents multiple blocks):
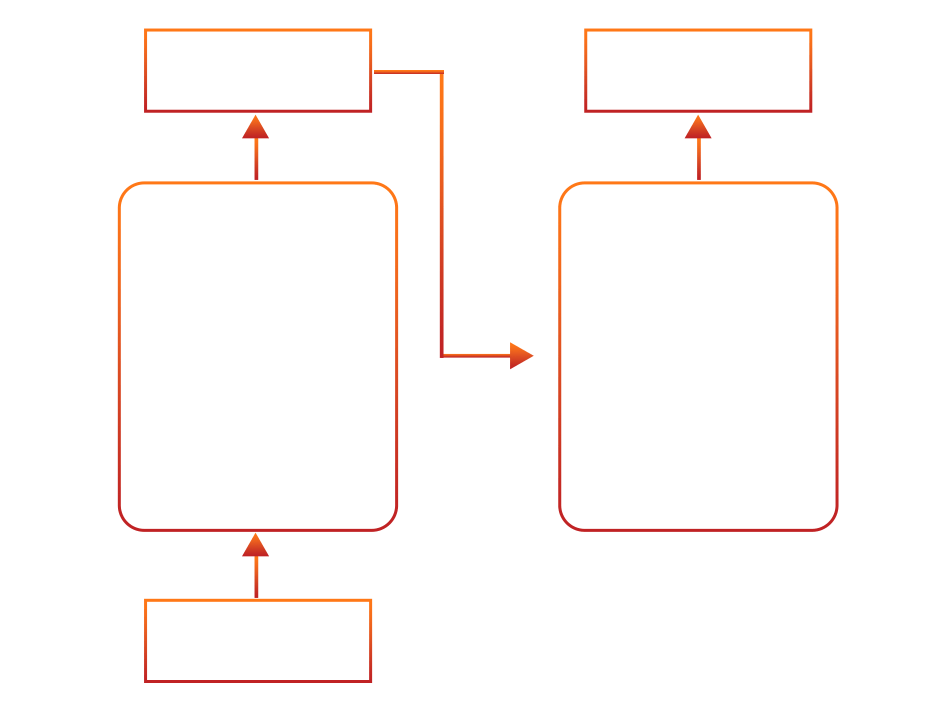
The following diagram illustrates the complete transformer architecture (breakdown of encoder and decoder) and demonstrates how each component interacts harmoniously:
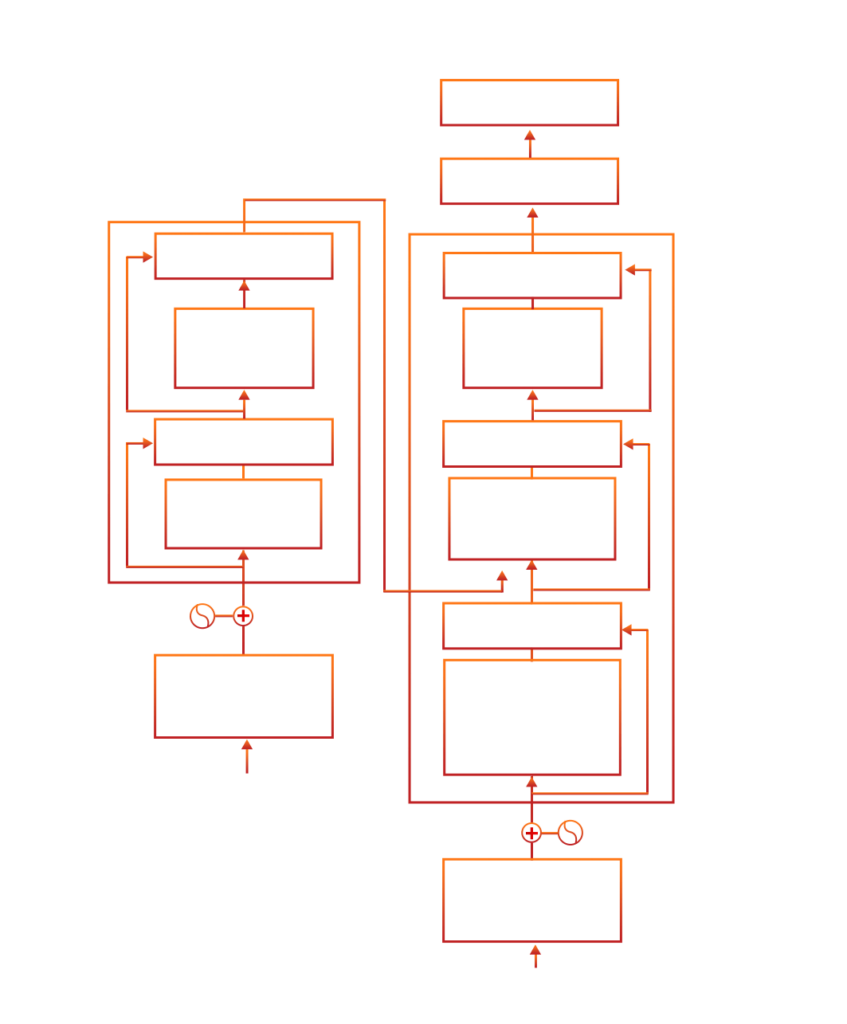
Fig: Architecture of transformer models
Let’s understand in detail!
Here’s what the encoder blocks contain:
The first step begins with the input embedding layer. This layer is crucial because it turns words into number codes called vectors. These vectors represent the meaning of the words in a compact way. The values in these vectors are learned as the model gets trained.
It’s much more efficient than using a method like one-hot encoding, which would create very long vectors for big vocabularies.
Without the use of recurrence or convolutions, the transformer model faces a unique challenge. That is, it doesn’t naturally understand the order of words in a sentence. This is where positional encoding comes into play.
To maintain the order of words in the sentence, positional encoding vectors are added to the word embeddings, providing meaningful distances between words. It is like giving the model a map of where each word is in the sentence. It works by adding this positional information to the input embeddings before they go through the model. This extra information helps the model understand the position of words as it processes the sentence.
Fact: While there are different ways to do positional encoding, the original transformer paper uses a method called “sinusoidal encoding”.
In the encoder, multi-head self-attention is a key component that allows the model to understand the relationships between different words in the input sentence. This mechanism operates on the input embeddings and helps the model focus on different parts of the input sentence simultaneously.
Note: Self-attention is like a spotlight that helps the model focus on important words in a sentence. For instance, in the sentence “The animal didn’t cross the street because it was too tired,” self-attention helps the model understand that “it” refers to “animal” instead of “street.”
Here’s how self-attention works in the encoder:

In each part of the transformer model, there’s a special type of network called a feed-forward neural network. This network works on its own at each position and has many layers and special functions that help it understand complex patterns in the data.
These networks play a crucial role in changing the representations created by the self-attention mechanism. By doing this, the model can understand more complex relationships in the data than what the attention mechanism alone can handle. Using hidden layers and special functions, the model can uncover hidden complexities in the data, leading to a deeper understanding overall.
In the model’s complex design, two important elements stand out: normalization and residual connections. These elements are crucial for ensuring the model learns effectively and stays stable during training.
Here’s what the decoder blocks contain:
1. Multi-Head Self-Attention: Like the encoder, the decoder uses multi-head self-attention to understand different parts of the input sentence. However, in the decoder, the self-attention mechanism only attends to earlier positions in the output sequence to ensure that the model generates the output sequentially. This helps the decoder generate the output one word at a time, ensuring that each word is generated based on the context of the previous words.
2. Position-Wise Feed-Forward Network: This network processes the representations created by the self-attention mechanism, understanding complex patterns in the data and transforming the representations into a format suitable for generating the output sequence. The position-wise feed-forward network helps the decoder learn the relationships between words in the output sequence and generate accurate translations.
3. Encode-Decoder Attention Layer: This layer allows the decoder to focus on different parts of the encoder’s input when generating the output sequence. It helps the decoder understand the relationships between words in the input and the output, ensuring that the generated output is contextually relevant. The encode-decoder attention layer helps the model generate accurate translations by aligning the input and output sequences.
4. Output Layer: This stands as the end layer of the transformer model. It is responsible for creating the result of the model, turning its learned knowledge into something tangible. For instance, in language translation, the output layer transforms the model’s understanding into a sequence of words in the target language.
This layer usually consists of two parts: a linear transformation and a softmax function. Together, they create a probability distribution that helps the model choose the most likely word for each position in the output. This allows the model to generate its output, step by step, creating a clear and meaningful message.
Bonus: If complex terms seem overwhelming, here’s a simple example to help you understand how the functions mentioned above work:
1. Suppose you say “car” and the model will convert it into a vector like [0.3, -0.1, 0.5].
2. If you say, “blue car”, it adds positional information, like [0.3, -0.1, 0.5, 0.2, -0.4, 0.7].
3. The model focuses more on “blue” for understanding the car’s color.
4. The model learns that “blue” is associated with a specific color.
5. The model enhances its learning capabilities and accurately identifies the car’s color in context.
6. The model can then generate “voiture bleue” if you say French for “blue car”.
Stay tuned for an explainer blog or video that’ll help you grasp the workings of such models more precisely.
If you’ve found the content intriguing so far, you’re likely eager to delve into training transformer models.
So, let’s get the last chunk!
Follow these steps to train your transformer model:
That’s it! So, with all the above knowledge, you can start implementing the perks of transformer models within your organization and slash off manual efforts in building the best software products.

We are excited to help you build your next disruptive software product with the power of GenAI. If you think you’re ready to take such a leap to stay ahead on the competitive tech island, feel free to write to us at Nitor Infotech.
Until then, happy transforming!

we'll keep you in the loop with everything that's trending in the tech world.