
In today’s fast-paced digital landscape, businesses are increasingly relying on real-time data to make informed decisions and provide timely services. Google Cloud Datastream is a powerful service that enables seamless and efficient real-time data replication and synchronization across various data sources and targets within the Google Cloud Platform (GCP) ecosystem.
What’s more, Google Cloud Datastream supports a wide range of data sources and targets. Here are some of the key ones:
Data Sources
1. Databases: You can employ Google Cloud Datastream as it can replicate data from popular databases such as MySQL, PostgreSQL, Oracle, Microsoft SQL Server, and more.
2. Change Data Capture (CDC): You can capture real-time changes from CDC-enabled databases and replicate them using Google Cloud Datastream.
Data Targets:
1. Storage: You can replicate data to Cloud Storage buckets, enabling further processing or analysis.
2. BigQuery: You can leverage Datastream as it can replicate data to BigQuery, allowing real-time integration with your data warehouse for analytics and reporting.
3. Google Cloud Pub/Sub: You can publish data changes to Pub/Sub topics, enabling real-time data streaming and integration with downstream system.
Benefits of Using Datastream:
Here are some of the common benefits of using Google Cloud Datastream:
- Real-Time Data Replication: With Datastream, you can avail real-time replication of data changes from various sources to targets within the GCP ecosystem. It captures and streams data changes with minimal latency, ensuring that the replicated data is always up to date.
- Simplified Data Integration: Datastream provides a simplified and managed approach to data integration. It abstracts the complexity of data synchronization, handling tasks such as schema mapping, change data capture, and transformation, making it easier to set up and maintain data pipelines.
- Near-Zero Downtime: With Datastream, you can perform data replication with minimal to no impact on the source systems’ availability and performance. It utilizes log-based change data capture methods, which minimize the impact on production databases, ensuring near-zero downtime during the replication process.
- Scalability and Flexibility: Datastream is built on Google Cloud’s scalable infrastructure, allowing it to manage high volumes of data changes efficiently. It scales dynamically based on workload demands, ensuring optimal performance and throughput for data replication tasks. It also offers flexibility in choosing data sources and targets, supporting a wide range of databases and cloud storage services.
- Data Consistency and Reliability: Datastream ensures data consistency by maintaining the order of data changes during replication. It guarantees reliable delivery of data changes, even in the event of network disruptions or failures. It provides features like automatic retry, fault tolerance, and error-handling mechanisms, ensuring the integrity and reliability of replicated data.
- Monitoring and Alerting: Datastream offers monitoring and alerting capabilities, allowing you to track the status and health of data replication tasks. It provides metrics, logs, and monitoring dashboards to monitor the progress, latency, and throughput of data replication. You can set up alerts and notifications to get notified about any issues or failures in the replication process.
- Integration with GCP Services: As a part of the Google Cloud Platform, Datastream seamlessly integrates with other GCP services. For example, you can replicate data to Google Cloud Storage for further processing, analyze the replicated data in BigQuery, or stream the changes to Google Cloud Pub/Sub for real-time data streaming and integration with downstream systems.
Let’s consider a use case scenario where real time changes need to be copied from Cloud SQL (MySQL) to BigQuery. You can follow these steps to complete the setup:
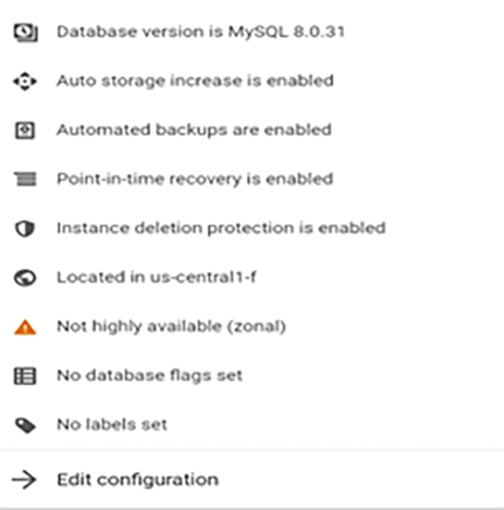
Step1: Setup GCP Cloud SQL (MySQL) instance

Step 2: Enable Auto recovery of MySQL instance
- Connect to the instance and create datastream user with the following commands:
cloud MySQL server
- CREATE USER ‘datastream’@’%’ IDENTIFIED BY ‘[YOUR_PASSWORD]’;
GRANT REPLICATION SLAVE, SELECT, RELOAD, REPLICATION CLIENT, LOCK TABLES, EXECUTE ON *.* TO ‘datastream’@’%’; FLUSH PRIVILEGES;
- Confirm that the binary log is configured correctly: To enable binary logging on a MySQL server, you need to modify the MySQL configuration file (my.cnf or my.ini, depending on your operating system).
Here’s how you can enable binary logging:
- Locate the MySQL configuration file:

- Open the MySQL configuration file using a text editor.
Look for the [mysqld] section in the configuration file. If it doesn’t exist, add the following line at the beginning of the file to create the section:[mysqld]
- Add the following configuration options under the [mysqld] section to enable binary logging:
makefile log_bin = mysql-bin Save the configuration file and exit the text editor.
- Restart the MySQL server to apply the changes. The method for restarting the MySQL server depends on your operating system. For example, on Linux, you can use the following command:
sudo service mysql restart
After the server restarts, binary logging will be enabled. You can verify this by connecting to the MySQL server and running the following command:
SHOW BINARY LOGS;
This command will display a list of binary log files that have been created.
With binary logging you can utilize features like point-in-time recovery, replication, and other advanced MySQL functionalities. However, keep in mind that binary logging can consume disk space, so it’s important to manage the log files and set up a regular backup strategy to maintain the necessary storage capacity.
Step 3: Creating connection profiles with data stream
Connections need to be created as source, sink/target to be configured to create streaming pipeline.
- Create stream to transfer data from Cloud MySQL to BigQuery table

- Create connection to source database

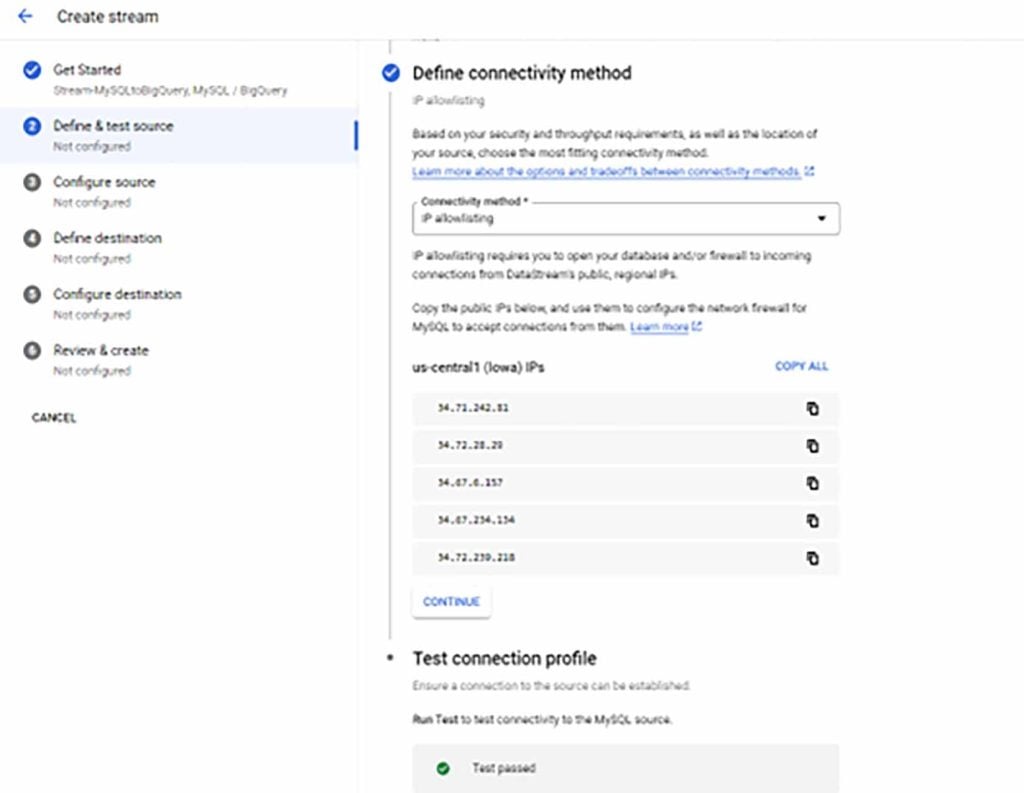
- Whitelist below list of IP addresses in the cloud MySQL server
- Select objects to load into BigQuery

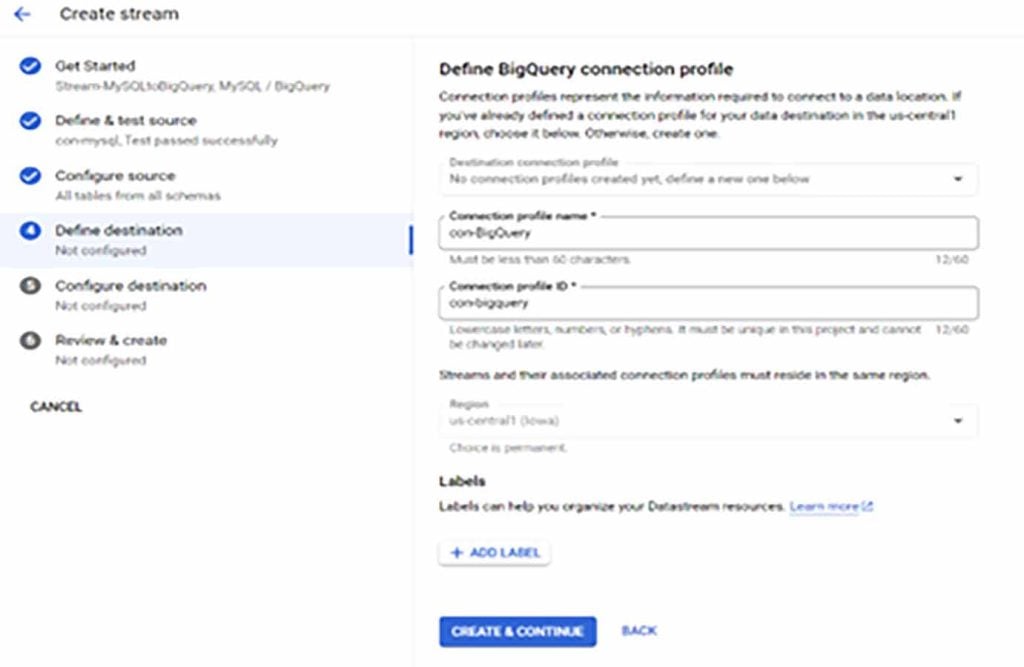
- Create target BigQuery connection
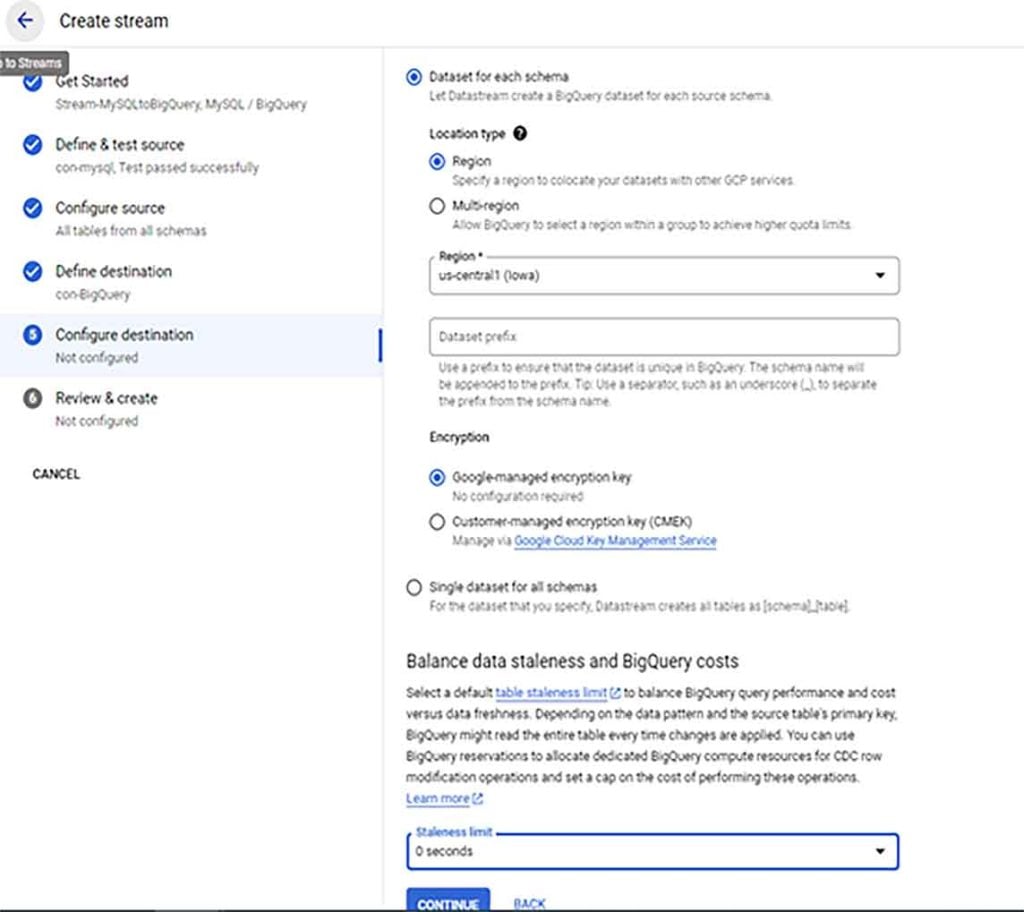
- Set staleness limit to 0 for realtime data
- Datastream is created for Cloud MySQL to BigQuery realtime replication

- Stablish source and target connection profile in Datastream

- Observe that Datastream is running

- Source : Employee table without PRIMARY KEY

- Source : Product table with PRIMARY KEY

Datastream will add some metadata columns in the table to implement the change in data capture. The employee table has an is_deleted column because the table does not have a PRIMARY KEY.Table without PRIMARY KEY and it will be APPEND ONLY.

- The product table did not have is_deleted column because the table has a PRIMARY KEY. The table with PRIMARY KEY will update the existing record.

- After the record being inserted, updated, and deleted in the employee source table, the following replica in BigQuery is obtained:

Price is updated from 20000 to 40000 in Product source table for product_id =3.
Datatsream has now updated the existing record with modified values.
It is key to note that if the record is deleted from the source then It will be deleted from Target also.

The table has a primary key and if is_deleted column is required in the target table then create Datastream from Source to GCS in the required file format and read those files into BigQuery.
With that, you have now learned how to successfully sync data real time using GCP Datastream. Easy, right?
Now, before you start practicing on your own, I’d love for you to go through our blog on data modelling and reach out to us at Nitor Infotech with your thoughts!



