
Highlights
Organizations struggle with fragmented data spread across databases, lakes, and warehouses. Traditional ETL pipelines are slow, costly, and inefficient. Here, Apache Trino emerges as the solution – a distributed SQL engine enabling ad-hoc, federated analytics across multiple systems without requiring data duplication. Its connector-based architecture integrates seamlessly with SQL databases, NoSQL, data lakes, and BI tools, making it ideal for interactive analytics, reporting, and machine learning pipelines. With scalability, lakehouse support, cost optimization, and compatibility with modern data architectures like data mesh, Trino offers speed, flexibility, and future-ready insights for organizations modernizing their data strategy.
What do you think is the most common challenge organizations still face? It’s data management. Data is scattered across databases, data lakes, warehouses, and cloud platforms. Moreover, traditional ETL (Extract, Transform, Load) pipelines are slow, complex, and require moving massive amounts of data just to run analytics. This creates bottlenecks, rising costs, and delays in decision-making. To address such roadblocks, Apache Trino emerged as the solution that lets you run fast, interactive queries across multiple sources without moving or duplicating data.
In this blog, you’re going to learn everything about Apache Trino, its complex architecture, and use cases.
What is Apache Trino?
Apache Trino (previously known as PrestoSQL) is an open-source, distributed SQL engine designed for high-speed, interactive analytics across diverse data sources. Developed in Java and fully aligned with ANSI SQL standards, it integrates effortlessly with popular BI platforms such as Tableau, Power BI, and Apache Superset.
Trino excels at running ad-hoc queries using standard SQL, allowing users to analyze data without needing new languages or tools. It doesn’t store data itself but connects to external sources—like databases, data warehouses, or data lakes—using connectors. This makes it ideal for federated queries and fault-tolerant ETL/ELT workloads.
Trino uses connectors like “bridges” that let it talk to many different data systems. Even if the system doesn’t store data in regular tables, Trino can still query it by using its API.
It includes ready-to-use connectors for relational databases, NoSQL systems, and data lakes. As Apache Trino separates compute from storage, it easily integrates with file systems, object stores, and custom services. It works with many systems, such as:
- SQL databases: MySQL, PostgreSQL, Oracle, and SQL Server
- NoSQL databases: MongoDB, Cassandra, and Elasticsearch
- Data lakes: Hive, Iceberg, Delta Lake, and Hudi
This wide support makes Trino a powerful tool for analyzing data from multiple sources.

Learn how to integrate multiple data sources with ease. Discover which Power BI version fits your business needs.
Time to break down the inner workings of Apache Trino’s architecture!
Apache Trino Architecture Explained
Trino is a distributed SQL engine that operates by spreading query processing across multiple servers – somewhat like MPP systems. Instead of upgrading a single machine, you can add more servers to the cluster to boost performance and scale easily.
Here’s how Apache Trino is architected:
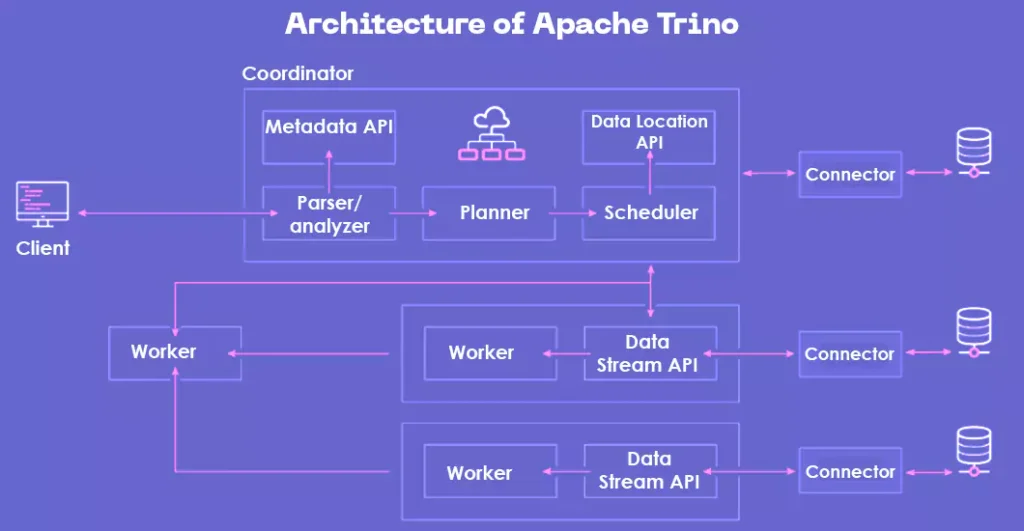
Fig: Architecture of Apache Trino
Let’s get down to deeper roots!
Part A: The left-hand side of the architecture
The diagram mentioned below showcases a Trino cluster with one coordinator and multiple worker nodes. A Trino user connects to the coordinator through a client, such as a JDBC driver or the Trino CLI. The coordinator then manages communication with workers, directing them to fetch data and run queries.

Fig: Left-Hand Side of Apache Architecture
To simplify:
- The coordinator is like a manager who receives queries and makes sure the workers handle them properly.
- The workers are like helpers who actually do the tasks and process the data.
- A built-in discovery service helps new workers join the team, so the system knows who’s available.
- All the communication between users, the coordinator, and workers happens through standard web connections (HTTP/HTTPS).
The diagram mentioned further illustrates how communication flows within a Trino cluster between the coordinator, workers, and between workers themselves.
The coordinator distributes tasks, tracks their progress, and compiles the result set for the user. Meanwhile, workers exchange data among themselves, pulling outputs from upstream tasks on other workers and retrieving results directly from the data sources.
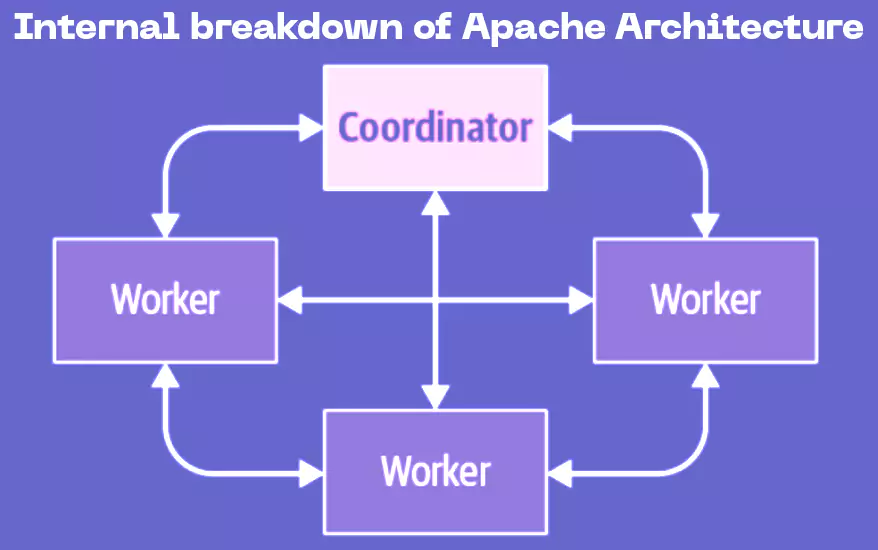
Fig: Internal Apache Architecture
Examine the roles of these three key components – the coordinator, the discovery service, and the workers.
1. Coordinator: Trino’s coordinator is the “brain” of the system. It is the master server that receives SQL requests from users, determines how to execute them, and then instructs the worker nodes to execute the task.
When a user posts a query, the coordinator divides it into smaller units, distributes them among workers, and ensures that everything is done in the right sequence.
As workers execute the data, the coordinator retrieves the results and forwards them to the user via an output buffer. As the user receives results, the coordinator continues to fetch additional data from the workers until the query is completed.
2. Discovery Service: To monitor all nodes of a cluster, Trino uses a discovery service. Whenever a Trino node starts, it registers itself with the service and regularly sends a ‘heartbeat’ signal to confirm that it’s active and running.
If a worker does not send these pings, it will be flagged as unavailable and will not be given any new work. This discovery service is executed on the coordinator and has the same HTTP server and port. Workers only utilize the hostname and port of the coordinator to communicate.
3. Workers: These are Trino’s “doers.” They obtain work from the coordinator, retrieve data from one or more sources via connectors, process it, and publish intermediate outputs to other workers if necessary.
Once the data is ready, the workers send it back to the coordinator, which combines all the pieces and delivers the final result to the user.
Part B: The right-hand side of the architecture
Connector-Based Architecture
Trino uses a connector-driven architecture that decouples computing from storage. These connectors act as table-like layers on top of different data sources, enabling Trino to query them with standard SQL—even when the source itself doesn’t support SQL.
As long as the data can be represented in tables with rows and columns using Trino’s supported data types, a connector can be built. Connectors implement Trino’s Service Provider Interface (SPI), which defines how Trino interacts with the source. This standard interface lets Trino perform queries uniformly. Meanwhile the connector handles the specifics of the data source.
Each connector implements three key parts of the API:
- Operations to fetch table/view/schema metadata: Retrieves information about the structure of tables, views, and schemas in the data source.
- Operations to produce logical units of data partitioning: Enables Trino to parallelize reads and writes by dividing data into manageable partitions.
- Data sources and sinks: Changes the data from its original format into the format that Trino’s query engine can use.
For example, every Trino connector that can read data must support the listTables method. This allows Trino to fetch a list of tables from any data source in the same way, without needing to know whether that information comes from a schema, a metastore, or an API.
The core Trino engine remains unaware of these details, as the connector handles them. This clear separation improves code readability, extensibility, and maintainability by isolating the query engine from data source specifics.
Beyond just connecting to diverse data sources, Trino also focuses on squeezing out maximum performance from every query.
Let’s get to know how.
How Apache Trino Optimizes Query Performance
Here’s how a SQL query travels through the engine and gets executed:
1. Query Execution Model
When you submit a SQL query to Trino, the coordinator first parses it, checks its validity, and creates an execution plan (query plan) that defines the steps to process data and return results.
To do this, the coordinator:
- Uses metadata SPI to validate tables, columns, and types, along with type and security checks.
- Uses statistics SPI for row counts and table sizes to enable cost-based optimization.
- Uses data location SPI to break data into splits—the smallest unit of parallel work.
The query plan is broken into stages, each with tasks distributed across workers. Workers process tasks in parallel, producing data in pages (rows in columnar format). These are passed between stages through exchange operators.
Each task runs drivers for every split, forming pipelines of operators (scan, filter, join, aggregate) that transform data step by step.
The coordinator manages scheduling, assigns tasks to workers, and ensures all splits are processed. Once completed, it collects the final outputs and returns the result to the client.
2. Parsing and Analysis
Before a query can be executed, it must first be parsed and analyzed. During the parsing phase, Apache Trino checks the SQL statement for syntax correctness. Once parsed, it proceeds to analyze the query by:
- Identifying Tables: It identifies the tables referenced in the query, which are organized within catalogs and schemas. Since multiple tables can have the same name, this is crucial for disambiguation.
- Identifying Columns: The analyzer determines which table each column belongs to, ensuring the correct table is associated with each column reference.
- Identifying Field References within ROW Values: The analyzer also handles references to fields within ROW values, ensuring that table-qualified column references take precedence in case of ambiguity. It follows SQL scoping and visibility rules.
This data analysis process helps collect important information, like identifier disambiguation, which is later used during the planning phase to avoid re-checking scoping rules.
The query analyzer performs complex, behind-the-scenes tasks, and its work generally remains invisible to users unless the query violates SQL rules, exceeds user privileges, or is otherwise invalid. After completing the data analysis, Trino moves on to query planning.
3. Initial Query Planning
A query plan in Trino defines the steps required to produce the query result. Since SQL is a declarative language, the user specifies what data they want, but not how to process it. The task of determining the sequence of steps to retrieve the desired result falls to the query planner and optimizer. The structured outline of these steps is called the query plan.
Theoretically, there could be an exponential number of possible query plans that yield the same result, but the performance of these plans can vary significantly. At this stage, Trino’s planner and optimizer step in to determine the most efficient execution plan. Different plans that yield the same result are referred to as equivalent plans.
What Are Catalogs and Schemas in Apache Trino?
These are two technical terms that you should be aware of when dealing with Apache Trino:
1. Catalogs: In Trino, a catalog represents a data source configured via a properties file and a specific connector. Each catalog contains one or more schemas, which organize tables similarly to how databases are structured.
Catalogs can connect to a wide range of systems, such as PostgreSQL databases, JMX metrics, Iceberg-based data lakes, or real-time OLAP stores like Pinot. Additionally, the same connector can be used in multiple catalogs, allowing connections to different PostgreSQL databases, for example.
All SQL queries in Trino operate on catalogs, with fully qualified table names following the format: catalog.schema.table.
For instance, datalake.test_data.test refers to the test table in the test_data schema of the datalake catalog, regardless of the underlying storage system.
2. Schemas: Within each catalog, schemas organize tables, views, and other objects. In relational databases like PostgreSQL, Trino schemas map directly to the database’s schema structure.
However, schema mappings may vary for other connectors; for example, in the Hive connector, a Hive database appears as a schema in Trino. While schemas are often pre-defined when configuring a catalog, Trino supports creating and managing schemas through SQL.
Note: The information schema, part of the SQL standard, is supported in Trino as a set of views that provide metadata on schemas, tables, columns, and other objects within a catalog. Each catalog has its own information_schema, and commands like SHOW TABLES or SHOW SCHEMAS act as shortcuts to this metadata.
Let’s move on to the use cases of Apache Trino.
What Are Some of the Major Use Cases of Apache Trino?
These are some areas where Apache Trino truly shines:
1. Interactive Analytics Across Systems
Trino allows users to run real-time SQL queries across multiple data sources like object storage, relational databases, and streaming platforms. It eliminates the need to move or duplicate data, enabling seamless cross-platform data analysis. This is ideal for fast, interactive exploration of heterogeneous datasets.
2. Federated Querying
It supports querying across disparate systems through its extensive connector ecosystem. It enables integration of relational, NoSQL, and data lake sources into a unified query layer. This helps enterprises unify data access without centralizing storage.
3. Data Lakehouse Analytics
It efficiently queries large datasets stored in modern data lakes using open formats like Parquet, ORC, and Iceberg. It provides high-performance access to structured and semi-structured data. This makes it suitable for scalable, ad hoc analytics on cloud-native storage.
4. BI & Reporting Tool Integration
It integrates with business intelligence tools via JDBC/ODBC and supports ANSI SQL. It acts as a backend engine for dashboards and reports requiring distributed query capabilities. This provides business users across departments with real-time insights.
5. Data Mesh Architectures
It supports decentralized data ownership by allowing teams to query domain-specific datasets without physical consolidation. It facilitates cross-domain analytics while preserving autonomy. This aligns with modern data governance and scalability principles.
6. Machine Learning Pipelines
Trino is used for preprocessing and feature engineering by joining and aggregating data from diverse sources. It streamlines the creation of training datasets for ML models. This enhances efficiency in building data-driven applications.
7. Cloud Cost Optimization (FinOps)
It aggregates billing and usage data across cloud providers and internal systems. It enables detailed cost analysis, trend identification, and chargeback reporting. This supports financial transparency and optimization in multi-cloud environments.
So, Apache Trino stands out as a powerful enabler for modern data platforms—offering speed, flexibility, and scalability without the overhead of data duplication.
Whether for analytics, BI dashboards, or advanced architectures like data mesh and lakehouse, Trino provides a unified way to unlock deeper insights across diverse data sources. As data ecosystems continue to expand, Trino will become a more reliable and future-ready query engine well worth considering.
Learned something new today around the big data space? Share your thoughts with us at Nitor Infotech, an Ascendion company—we’d love to hear from you.



