
In the hustle and bustle of today’s data-driven world, real-time data synchronization is the unsung hero, ensuring organizations stay ahead of the curve with lightning-fast, informed decisions. Databases like MongoDB and other relational databases can assist, but they alone cannot guarantee seamless data synchronization in real time. Below are some common issues that often arise:
- Network latency can create issues when synchronizing data in real time. If the network connection between the two databases is slow or unreliable, data may not be synchronized correctly.
- Synchronizing data in real-time can be resource-intensive and expensive, especially when dealing with large amounts of data.
To learn more about the issues and overcome such challenges, I’d first recommend you to first read our latest blog on “PySpark-Powered Real-Time Data Synchronization for MongoDB and Azure SQL“. This blog talks about an innovative approach using PySpark to synchronize both databases, offering valuable insights for your integration efforts.
BONUS: Guess what? I’ll provide you with another approach to solve this problem in this blog.
Here we’ll explore another alternative approach to synchronizing databases using Azure services. In this approach, we will leverage Azure Event Hub, Azure Stream Analytics, Azure Data Lake Storage, and Azure SQL Database to achieve seamless synchronization between the databases.
Before we dive into the core details and actionable steps, I encourage you to take a quick look at why data synchronization in real-time is important for your business in 2024.
Why Synchronize Data in Real-Time?
Real-time data synchronization is essential for several reasons:
1. Improved Data Consistency: Synchronizing data in real-time ensures that data is consistent across all sources. This results in reducing errors and inconsistencies that can occur when data is updated manually.
2. Enhanced Collaboration: It facilitates collaboration among teams working on different systems, enabling seamless sharing and updating of information.
3. Better Decision Making: With access to real-time data, businesses can make informed decisions quickly. Thus, responding to changing market conditions and customer needs.
4. Boosted Efficiency: It helps automate data transfer, reducing manual effort and improving operational efficiency.
5. Better customer experiences: It can help organizations provide better customer experiences by ensuring that customer data is consistent across all touchpoints, such as e-commerce websites, mobile apps, and customer service platforms.

Learn how we helped a retail company slash reporting time by 50% with our transformative GenAI-powered data analysis solution.
By now, I’m confident that you are all excited and ready to learn about the alternative approach. So, let’s get into it!
An Alternative Solution: The Azure Service Approach
Here’s a simple breakdown of how we plan to synchronize data in real time between MongoDB Atlas and relational databases using Azure Services:
In an event-driven architecture, systems communicate through events. When a change occurs in one system, it triggers an event that propagates to other systems, ensuring data synchronization in real-time.
This is what is exactly happening in the following diagram –
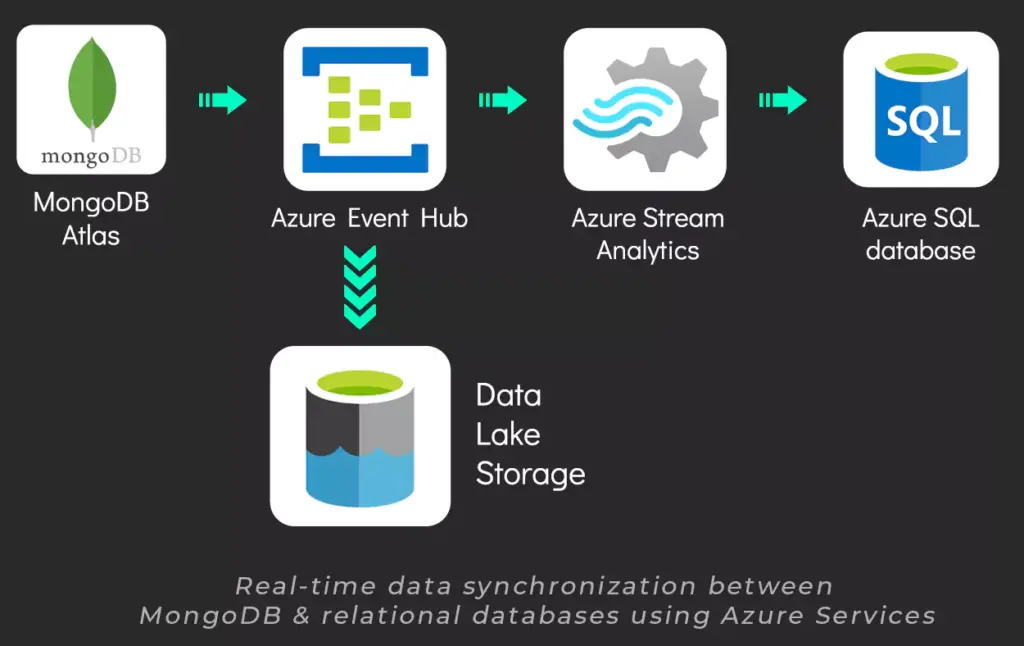
Fig: Real-time data synchronization between MongoDB & relational databases using Azure Services
1. MongoDB Atlas: This is our source database which provides change streams. This allows applications to listen to and respond to all data changes on a single collection, a database, or an entire deployment.
2. Azure Event Hub: This data streaming service can send millions of events per second, from any source to any destination, with very little latency. The change streams are captured and forwarded to the event hub, which then forwards the incoming event to stream analytics.
3. Azure Stream Analytics: It is a fully managed, real-time analytics service designed to assist you in analyzing and processing fast-moving data streams. You can utilize this to transform and flatten your data before sending it in real time to a relational database.
4. Azure SQL database: This is our destination relational database, where tables are synced with collections from MongoDB. In our experiment, we’ve implemented triggers to capture changes occurring in our source database. This data can then be used for insights and further sent to visualization tools.
5. Azure Data Lake Storage Gen2: This acts like a data warehouse in our case which acts like a staging area.
Sounds simple? I’ll make it simpler!
Let’s see the step-by-step guide of how we achieved the above next.
Implementing Real-Time Data Synchronization using Azure Services
Here are 5 steps that’ll help you synchronize your data between MongoDB Atlas and relational databases using Azure services:
Step 1: Establish a connection to MongoDB Atlas, like this:

Step 2: Connect to the Event Hub and send the captured change streams to it, using this command:

Step 3: Connect the Event Hub to Stream analytics.
After creating a stream job, add an EventHub input and SQL database output. Refer to the images below:

Fig: EventHub as input

Fig: SQL database as output
You can either create a new table or use an existing one from the database to store your data. Simply sign in with your username and password to proceed.

Fig: Username and password entry
Step 4: Transform the data and dump the output to SQL database.
To do so, write an appropriate query to transfer your data from the Event Hub to the SQL database table.

Fig: Query for data transfer
Step 5: Create triggers to synchronize and update the data in the display table.
In our case, the raw data was dumped into a table called raw table and all the insert, update and delete operations were performed. Our final data was shown in a table named displaytable.

Fig: Raw Data Table

Fig: Insert, update, and delete

Fig: Display table
That’s it! By following the above 5 steps, you’ll be able to successfully synchronize data in real-time.
Next, head over to the performance details and expenditures associated with implementing this approach!
Performance, Costing, and More
A. Here are the details of the computational resources used during the implementation process:

B. This table highlights the synchronization time required (performance) for different numbers of records inserted in MongoDB:
| No of records inserted in MongoDB | Time taken to Sync in Relational Database |
|---|---|
| 100 | 3 mins |
| 1000 | 30 mins |
C. Given below are the monthly and yearly cost for each of the services availed to conduct this process:
| Services | Monthly cost | Yearly cost |
|---|---|---|
| Azure Event Hub | $11.3 | $135.6 |
| Azure Stream Analytics | $240.90 | 2890.8 |
| Azure SQL database | $320.76 | $3849.12 |
| Azure storage account | $167.25 | $2007 |
| Total | $740.21 | $8882.52 |
*This is the estimated costing based on the above resources.
* The cost estimate is calculated for handling 1 million records per day.
D. Pros & Cons from the Process
Pros:
1. Cost-effective: In comparison to the other methods, this methodology is quite inexpensive and efficient.
2. Data loss prevention: In this architecture, we can retain data at each stage. Thanks to the implemented retention policy, which safeguards against potential service failures! Therefore, even if a service fails during the process, there won’t be any data loss, and we may pick up where the service left off.
3. Single script Supervision: We can keep an eye on the entire database and each collection inside it without having to execute several scripts for each collection.
4. High availability: As we are utilizing Azure cloud architecture, there is almost no downtime for this service, allowing us to operate our services around-the-clock.
5. Connectivity: Due to the single cloud design, these services have excellent connectivity and may effectively link to other services.
Con:
This design works well with low data latency. However, as the data frequency increases, multithreading becomes necessary, and there may be some latency with large data volumes.
Although maintaining the data schema is necessary and an important aspect in our approach, we were able to overcome a few other challenges and achieve real-time synchronization of the MongoDB Atlas and relational database using Azure services.
The services we utilize have data retention policies, ensuring that our data remains secure even if a service outage or failure occurs. This allows us to resume operations seamlessly and collect reliable data. Moreover, our approach is scalable, as we can adjust processing power to handle large data volumes effectively, all while maintaining real-time synchronization.
So, to get familiar with more approaches and the latest technologies, reach out to Nitor Infotech. We’ll be more than happy to help you become the next big thing!



