
In today’s data-driven world, businesses heavily rely on accurate and timely information to drive decisions, create strategies, and fuel innovation. However, what happens when the data being consumed is flawed? Applications can fail, insights may become unreliable, and client trust can erode. Enter ETL testing standing as the gatekeeper of data integrity.
By meticulously verifying the processes of extraction, transformation, and loading, it ensures that the data powering applications is not only accurate but also aligned with business expectations. In doing so, ETL testing builds the foundation for reliable systems and enables businesses to confidently make decisions that shape their future.
In this blog, we’ll explore the essential validations for ETL testing, decode common industry jargon, and, most importantly, uncover best practices enriched with real-world business use cases.
Process and Architecture for Effective ETL Testing
While you may already have a good understanding of the basics of ETL testing, I’ve simplified it further for clarity. Below is a breakdown accompanied by a diagram to illustrate the process more effectively:
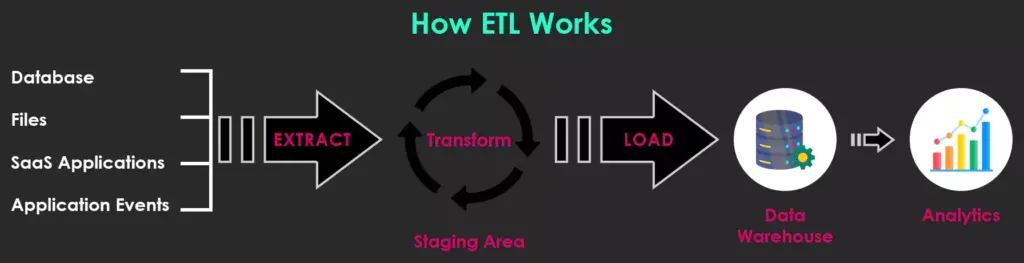
Fig: ETL Testing Process
- Extraction: Retrieve data from various source systems, such as databases, applications, or flat files.
- Transformation: Convert the extracted data into a standardized, analyzable format by applying business rules, data cleansing, and formatting.
- Loading: Store the transformed data into a target system, such as a data warehouse, where it is ready for analysis and reporting.
When talking about the data warehouse, the whole architecture looks like this:

Fig: Data Warehouse Architecture
Quick note: A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time within a data warehouse. It plays a crucial role in ETL processes, particularly in tracking the evolution of dimension records.
Here the various types of SCD:
- Type 0 SCDs (fixed dimension): No changes allowed; the dimension never changes.
- Type 1 SCDs (overwriting): Existing data is lost as it is not stored anywhere else.
- Type 2 SCDs (creating another dimension record): When the value of a selected attribute changes, the existing record is closed, and a new record is created as the current one. Each record includes effective and expiration timestamps to track its validity over time.
Onwards toward knowing about the validations!
Key Validations for ETL Testing
Here is the list of validations required for ETL testing:
- End-to-End Data Migration: Verifying successful data migration from source to target.
- Source-to-Target Record Count: Ensuring record counts match between source and target systems.
- Source-to-Target Data Match: Confirming data accuracy between source and target.
- Data Transformation: Validating proper data transformation according to business rules.
- Loading Techniques: Ensuring the correct use of Full or Incremental Loads.
- Current vs. Future System Comparison: Comparing legacy and new system data for consistency.
- Reports/Data Comparison: Verifying consistency in reports and data outputs.
- Loading Time: Measuring data load performance.
- Business Use Case Validation: Ensuring data meets specific business requirements.
- Downstream Data Transformation: Confirming correct data format for downstream systems.
- File Transfer: Ensuring secure and accurate file transfers during the ETL process.
Extra read: Get to know about the top 11 essential considerations for performing ETL testing.
Up next, familiarize yourself with the common ETL terminologies!
Important ETL Jargons
Here are the common ETL jargons that you should be aware of:
1. File Systems: There are 2 types of file structures as mentioned below:
- Structured – Clearly defined data types (CSV, database, tab-separated, etc.)
- Unstructured – Not as easily searchable (email, webpages, videos, etc.)
2. Dimensions: These are descriptive attributes that represent categories like products, locations, or time, typically stored as textual fields.
3. Facts: It consists of business facts and foreign keys that refer to primary keys in the dimension tables. Facts provide the measurement of an enterprise.
4. Staging Layer: This is a place where you hold temporary tables on data warehouse server after loading it from source systems.
5. Look-ups: Reference tables that are used to fetch the matching values.
6. Target tables: These are used to find the delta records or perform incremental load.
In addition to the challenges discussed in the first ETL blog mentioned earlier, I’d like to highlight a few more key obstacles you should be aware of.
More ETL Testing Challenges
Here are a few more ETL testing challenges that you should know:
- Managing large volumes and complex data
- Resolving incompatible or duplicate data
- Preventing data loss during the ETL process
- Addressing issues in business processes, procedures, and environment
- Ensuring stability in the testing environment
However, in order to overcome these roadblocks, you can follow the best practices outlined next!

Learn how we helped a leading tech company build an advanced analytics solution using Talend as the ETL tool to track 20+ business KPIs.
ETL Testing Best Practices
Here is a list of best practices you can follow in various scenarios to navigate ETL testing seamlessly:
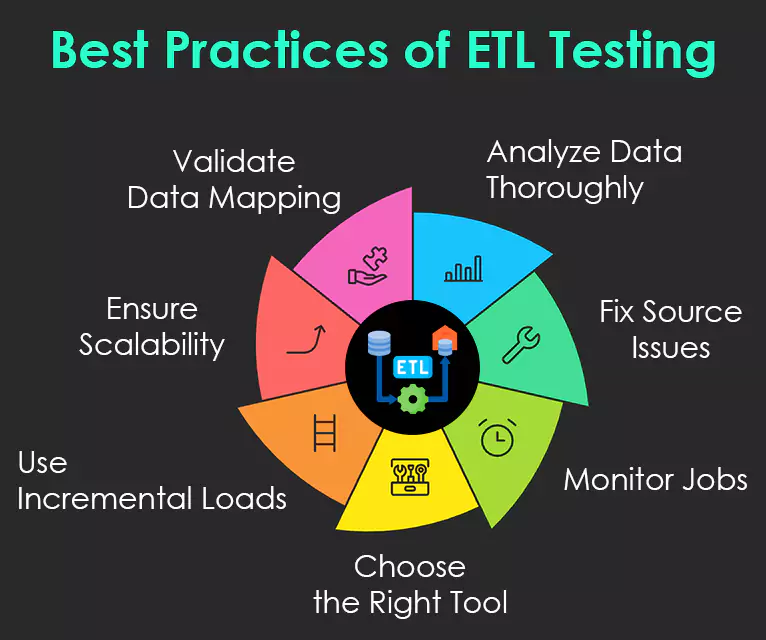
Fig: Best Practices of ETL Testing
1. Analyze the Data: It is extremely important to analyze the data to understand requirements and set up a correct data model. Spending time to understand the requirements and having a correct data model for the target system can reduce the ETL challenges.
It is also important to study the source systems, data quality, and build correct data validation rules for ETL modules. An ETL strategy should be formulated based on the data structure of the source and the target systems.
Business use case: Suppose we are dealing with the retail domain for multinational customers. So, before starting with any load of data we should analyze how they are sharing the sales details and what type of currency they are using. If we have previously implemented templates, we can reuse it for that type of currency.
2. Fix bad data in the source system: End-users are normally aware of data issues, but they have no idea how to fix them. It is important to find these errors and correct them before they reach the ETL system. A common way to resolve this is at the ETL execution time, but the best practice is to find the errors in the source system and take steps to rectify them at the source system level.
Business use case: Continuing our previous example, we should always check for bad data in the first place. Bad data can be a negative transaction amount for a particular transaction, discount more than the unit price of a product, and so on. So, we should report such issues and get the correct data before loading it into the next layer (staging layer).
3. Monitor ETL jobs: Another best practice during ETL implementation is scheduling, auditing, and monitoring of ETL jobs to ensure that the loads are performed as per expectation.
Business use case: Monitoring is very important when it comes to ETL, we should always check the parameters such as how much time it takes to load amount of data and whether there are any failures while loading or so on.
4. Find a compatible ETL tool: One of the common ETL best practices is to select a tool that is most compatible with the source and the target systems. The ETL tool’s capability to generate SQL scripts for the source and the target systems can reduce the processing time and resources. It allows one to process transformation anywhere within the environment that is most appropriate.
Business use case: There are numerous ETL tools available, each designed to handle different data sizes and project requirements. The choice of tool depends on factors such as project needs, data volume, and budget. For instance, if you’re working with large-scale data and need high scalability, tools like Apache NiFi or Talend may be ideal, while for smaller, more cost-effective solutions, something like Informatica or SSIS could be a better fit.
5. Integrate incremental data: When data warehouse tables are too large to refresh during every ETL cycle, incremental loads become crucial. They ensure only changed records are processed, improving scalability and reducing refresh time. However, if source systems lack timestamps or primary keys, identifying changes can be challenging and costly later. A key ETL best practice is to address this during the initial source system study. This helps the team identify data capture issues and choose the right strategy.
Business use case: This step relates to appending the incremental data once the full load is successfully done. This is critical since any mistake made in this can cause duplication in the tables and sometimes lead to loading the full load again, which is costly. Hence it is advisable to compare the incremental data with previously loaded data and make sure that they are aligned as per the business requirements.
6. Ensure scalability: This is the best practice to make sure the offered ETL solution is scalable. At the time of implementation, one needs to ensure that ETL solution is scalable with the business requirement and its potential growth in future.
Business use case: Scalability is something we should check whatever project we are dealing with, when it comes to data-related projects it is even more important since in today’s modern world data is getting expanded exponentially and a single CCTV camera can generate GBs of data in single day. So, we should always consider this and begin our project where ETL is easily scalable as we never know when the data size can get increased and our ETL is unable to handle that. In such cases, migrating to a new tool is required which is time-consuming.
7. Validate data mapping knowledge: Make sure data is transformed correctly without any data loss and projected data should be loaded into the data warehouse. Ensure that ETL application appropriately rejects and replaces default values and reports invalid data. Ensure appropriate load occurs at each data layer. Also ensure coding standards are in place while designing ETL mappings.
Business use case: Proper knowledge of data mapping and identification of data transformation rules becomes handy while performing validations.
Apart from all the above best practices, it is important to focus on the preparation of test data.
- For small projects, test data can be created manually.
- For larger projects, mass copying of data from production to the testing environment may be necessary.
- Alternatively, test data can be copied from legacy client systems.
- Automated test data generation tools can also be used to streamline this process.
Before we wrap up, let’s explore how the modern buzz – GenAI, can revolutionize ETL processes through integration along with some best practices for maximizing its potential.
The Future: ETL + Generative AI
Integrating generative AI into ETL processes transforms data workflows, enabling faster transformations and deeper, more actionable insights. It’s a strategic upgrade that enhances both efficiency and decision-making.
If you wish to harness the power of GenAI into ETL process, follow these optimal practices:
1. Standardize Data Formats: Validate and standardize data to ensure quality and prevent loss or corruption during the ETL process.
2. Leverage AI for Data Quality: Use AI/ML tools to detect and resolve anomalies, enhancing accuracy and reducing manual work.
3. Profile and Cleanse Data: Examine data for inconsistencies and correct inaccuracies to ensure AI models work with reliable datasets.
4. Implement Governance Frameworks: Set clear policies and metrics to maintain data consistency and accountability throughout its lifecycle.
Keep an eye out for an in-depth blog on integrating GenAI into ETL!
By now, you’re likely well-equipped to perform the ETL testing process seamlessly. If you still have any questions or would like to share your thoughts on this blog, feel free to reach us at Nitor Infotech.
ETL (Extract, Transform, Load) testing ensures that data is accurately extracted, transformed, and loaded into the target system. It plays a vital role in data warehouse testing, focusing on maintaining data quality and integrity.
Here the top six best practices of ETL Testing:
Fig: Best Practices of ETL Testing



