
In today’s day and age, an increase in demand for digitization has fueled a massive growth in technology and communication and the use of printed materials such as books and papers has significantly reduced. As humans we can understand the contents of these printed materials simply by looking at them. We perceive the text on the image as text and can read it. Computers don’t work the same way. They need something more concrete and organized in a way they can understand. This is where Optical Character Recognition (OCR) comes in.
OCR has applications across industries and finds several use cases in everything such as scanning bank statements, invoices, receipts, handwritten documents, coupons, recognition of car number plates and much more.

Explore how we digitized vendor invoice management for an automotive firm using OCR technology.
In this blog, we will delve into OCR and its application areas and discuss how we can improve our input quality to get the best possible output.
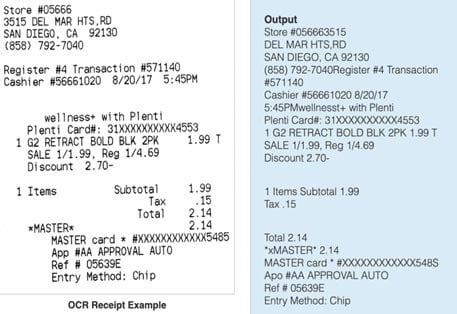
To start off, lets first understand what OCR is. Optical Character Recognition (OCR) is a technology that enables extraction of data from documents and converts it to text which we can then manipulate using a data analysis tool. These documents could be handwritten text, printed text, invoices, receipts, name cards, etc., or even a natural scene photograph.
OCR detects text on documents and this locates it to text show where the text is extracted from the image.
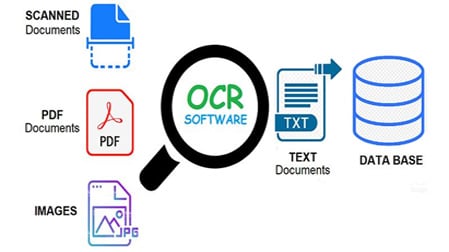
But, nothing is perfect and OCR is no exception. When it comes to increasing accuracy, it always boils down to two things, getting our data from the best source and choosing the right OCR engine for our use case. To understand this better, let’s first see some of popular applications of OCR.
OCR has made it possible to digitize printed documents without much manual effort. Through OCR we can easily produce a word document from an image.
If you have a document scanner on your phone, you have probably encountered OCR technology in use.
OCR is used in manufacturing and retail companies to digitize invoices ,receipts and purchase orders. This helps companies track overpayments ,duplicate payments, price mismatch or quantity mismatch, etc.
The banking industry has been extensively using OCR to archive customers’ paperwork, account number, amount, cheque number, etc. leading to enhanced user experience.
Other uses of OCR include automation of data entry processes, detection, book scanning, handwriting recognition, etc.
Now that we understand what OCR is and what it can do, let’s see top tools in the market which can be used to build an OCR product.
Google vision OCR
Google vision is the OCR API developed by Google Cloud. Google has released an API that can be used to extract information from images very accurately. There are many features within this API, such as detection and extraction of objects, faces, positions, etc. It can read image text in different fonts, languages, and even orientations. Because of this, it has to be one of the best products in the market for OCR.
AWS Textract
Amazon Textract uses machine learning to automatically extract text and data. Using Amazon Textract, we can easily extract text and data from images or scanned documents beyond OCR. Amazon Textract is based on the same proven, highly scalable, deep-learning technology that was developed by Amazon’s computer vision scientists to analyze billions of images and videos daily. Good thing is that we don’t need machine learning expertise to use it.

Azure API Vision
Azure API vision is an OCR product developed by Microsoft. It can extract printed text, handwritten text, digits, and currency symbols from images and multi-page PDF documents. It’s optimized to extract text from text-heavy images and multi-page PDF documents with mixed languages but focuses mainly on images. Thus, you can find a classification card of your image with categories such as object, keywords, description, format, colors, etc. Additionally, this OCR will allow us to identify and tag content. For example, we can use the object-detection tool to locate an object in an image.
In addition to these popular ones, there are other OCR solutions in the market like Rossum , Taggun etc., but they are exclusive solutions with a price tag. At the moment of writing it seems that Tesseract is considered the best open source OCR engine. Its accuracy is fairly high and can be increased significantly with a well-designed Tesseract image preprocessing pipeline.

Tesseract
Tesseract is a completely open-source OCR engine being developed and maintained by Google. As of today, Tesseract can detect over 100 languages and can process even right-to-left text such as Arabic or Hebrew. Previously Google used pattern matching but the recent version 4 uses a neural network system based on Long Short Term Memory (LSTM),which is a powerful method for sequence prediction problems.
The quality of image should be such that it is visible to the human eye. If that is the case then the OCR will produce good results. The better quality of image we have in our hand, better our OCR results will be. Although some OCR engines come with built in image preprocessing filters to improve the quality of the text image, they cannot tweak the images according to our use case. In order to achieve the best results, it is crucial to understand different components of this image processing pipeline.
Let’s see how we can increase the existing accuracy of our OCR engine:
Scaling of image
Image Rescaling is important for image analysis. Most OCR engines give an accurate output of the image which has 300 DPI(Dots per inch). Keeping DPI lower than 200 or greater than 600 may result in inaccurate results.
Increase contrast
Low contrast can result in poor OCR. We need to increase the contrast and density before carrying out the OCR process. Contrast and density are vital factors to be considered before scanning an image for OCR.

import cv2 as cv
import numpy as np
from PIL import Image
img =cv.imread('image.jpg')
#image scaling
im = Image.open("test.png")
im.save("test-300.png", dpi=(300,300))
#image increase contrast/brightness
alpha = 1.5 # Contrast control (1.0-3.0)
beta = 0 # Brightness control (0-100)
adjusted = cv.convertScaleAbs(img, alpha=alpha, beta=beta)
#binarising the image
im_gray = cv.imread('image.png', cv.IMREAD_GRAYSCALE)
(thresh, im_bw) = cv.threshold(img, 128, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
im_bw = cv.threshold(im_gray, thresh, 255, cv.THRESH_BINARY)[1]
#image noise removal
im_nr = cv.fastNlMeansDenoisingColored(img, None, 10, 10, 7, 15)
#skew correction
def deskew(image):
coords = np.column_stack(np.where(image > 0))
angle = cv.minAreaRect(coords)[-1]
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv.getRotationMatrix2D(center, angle, 1.0)
rotated = cv.warpAffine(image, M, (w, h), flags=cv.INTER_CUBIC, borderMode=cv.BORDER_REPLICATE)
return rotated
img_ds=deskew(img)
Binarising Image
Binarizing an image means converting the colored image to black and white format. The simplest way is to calculate a threshold value and convert all pixels to white with a value above threshold value and convert the rest of pixels to black. This step helps the engine to understand the data well. Binarizing an image can also help in decreasing the size of input.

Noise Removal
If an image has background or foreground noise present in it, we need to remove it in order to extract data. Noise can drastically reduce the quality of information retrieved. This process is also called as denoising of an image. It is a way of reconstructing signal from noisy images.

Skew Correction
Skewed images directly impact the line segmentation of an OCR engine, reducing its accuracy. Scanned documents often become skewed (slanted) during scanning because of human negligence or other alignment errors. Skew is the amount of rotation necessary to return an image to horizontal and vertical alignment and is measured in degrees. Deskewing is a process wherein skew is removed by rotating an image by the same amount as its skew but in the opposite direction. If the image is skewed to any side, deskew it by rotating it clockwise or anti clockwise direction.

To summarize, we have discussed how we can improve the existing accuracy of an OCR engine by simply adding an image processing pipeline. Increasing accuracy can help us to retrieve as much information as possible from an image/pdf. In my upcoming blog, I will dive deeper into how we can use this pipeline to leverage data extraction from images.
Reach out to us at Nitor Infotech to learn more about our services and read our case study to see how we leveraged OCR to help a leading automotive component company digitize vendor invoice management system.



