
Essentially, sentiment analysis is a natural language processing technique used to determine the emotional tone of textual data. It is primarily used to understand customer satisfaction and gauge brand reputation, call center interactions, customer feedback, and messages. Various types of sentiment analysis are common in the real world. But how is it done? In this part of my blog series, let me walk you through the implementation of sentiment analysis.
Sentiment Analysis Process
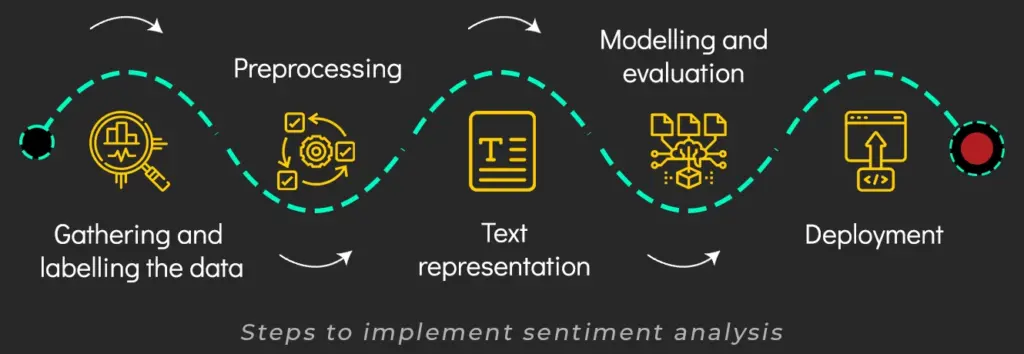
Every data science problem consists of certain inherent steps while modeling, hence sentiment analysis modeling is no different.
Here are the steps you need to follow to complete a sentiment analysis project –
If the question ‘What is sentiment analysis?’ popped up in your mind as you clicked on this blog, I think you will find my previous blog on the what of sentiment analysis interesting.
Let’s go back to the steps!
Step 1:
The first thing we must do before we solve a problem is to understand exactly what it is. We need to be able to translate the business problem into something valuable. Very often the business problem is not straightforward; this is where we must put our Sherlock Holmes hat on and ask the right questions. We need to identify the correct data then. Gathering them from a single source or various resources is our next step. Typically, these datapoints are not labelled or annotated, so we must ensure that we label them properly. Labelling is a step wherein we identify data and add meaningful labels to provide context so that our machine learning algorithm can learn from it. There are a lot of labelling tools in the market today, open source and paid as well. Some of them are – GATE, Label Studio, TagEditor, Doccano, and Amazon Ground Truth.
Step 2:
‘Garbage in, garbage out’ is an old expression used in data science. That is why data scientists dedicate most of their time to preprocessing data. Text preprocessing is a method to clean the text data and feed it into the model. Text data can have a lot of noise in the initial stage such as extra spaces, random cases, contractions, and emojis. Here are a few steps we can follow- expand contractions, remove extra spaces, stop words and punctuation, stemming and lemmatization, digits, or certain keywords, and making the text lowercase.
Step 3:
In this step, we convert our preprocessed text data into numbers so that machines can understand and learn from the underlying pattern. This is also called text representation and can be done in various ways – TFIDF, Bag of words, Word2Vec are a few of them.
Step 4:
NLP has a lot of applications for different industries and business functions. To name a few of them- Sentiment Analysis, Chatbots, Translation, Speech Recognition and Transcription, and text summarization. We can solve these by using various machine learning and deep learning models. In machine learning models, we can use Naïve Bayes Classifier, SVM classifier, Logistic Regression, Decision Trees, Boosting and Bagging. In deep learning models, we have RNN, CNN, GRU, LSTM and Transformer. From the sentiment analysis perspective, we can use any of them, provided they give us the best accuracy. In the case of text classification, accuracy can be measured based on 4 key classification metrics- Accuracy, Precision, Recall, and F1-score.
Step 5:
There are typically 3 types of deployment: real-time inference, batch inference, and edge deployment. Real-time inference is an architecture where a model is triggered anytime, and an immediate response is expected. Batch inference is a process to generate predictions on a batch of observations and the predictions are ideally stored for end users. In edge devices, the predictions happen at device level or local level by the machine learning/deep learning models.
Now let’s delve into implementing sentiment analysis.
We will start importing the necessary libraries for reading the data, processing the data, and modeling it. Here for modelling purposes, we will be using ktrain library. ktrain is a lightweight wrapper for the deep learning library TensorFlow Keras (and other libraries) to help build, train, and deploy neural networks and other machine learning models.
In the next step, we would be reading the data, and writing a small preprocessing function to process our raw texts. Text preprocessing varies a lot across domains, and we need to thoroughly go through a sample of texts to understand what kind of preprocessing our data needs. As it takes a lot of time to train a transformer model, we will take a sample of 20k sentences for the purpose of modeling.
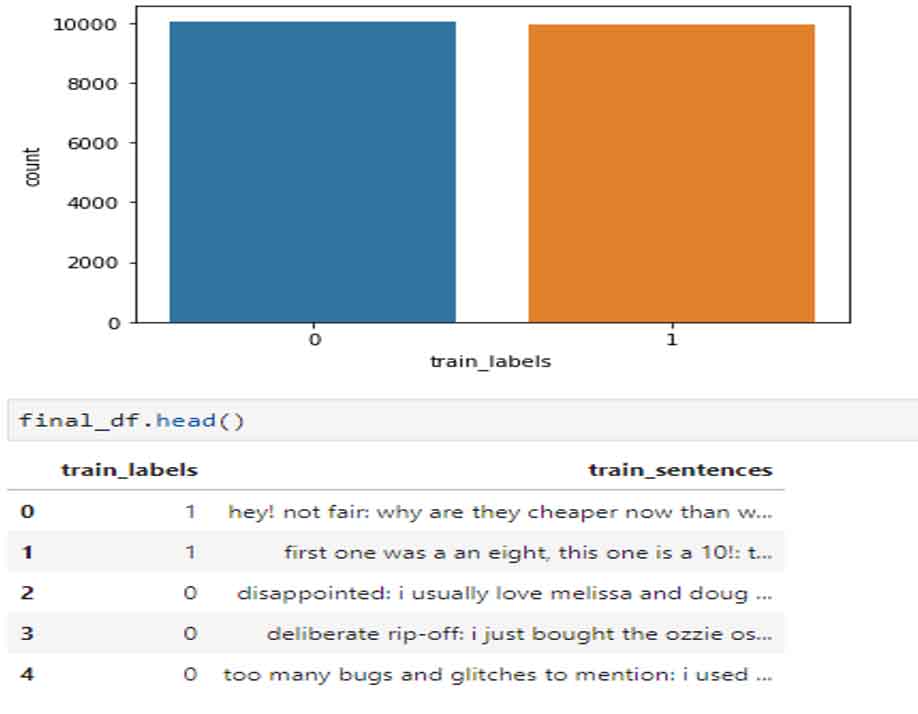
Next, we will check how the labels are present in the dataset with a simple count plot. Well, this looks good, as there is no imbalance of classes as we can see in the above plot. Now we need to represent data that the model will use to understand patterns. NLP has come a long way to represent language from a simple bag of words to BERT. Here we will be using BERT, as it gives a lot of advantage over all methods we had in the past. All the previous versions were context-independent whereas BERT is context-dependent. It allows us to have multiple representations for the same word, based on the context in which the word is used. For example, take a look at the image shown below:

Here BERT will generate two different vectors for the word “bank”, as the context is different in both cases one is related to finance and other is probably geography. Here we will be using DistilBERT, a small, cheap and light variant of BERT, to do the modeling faster.
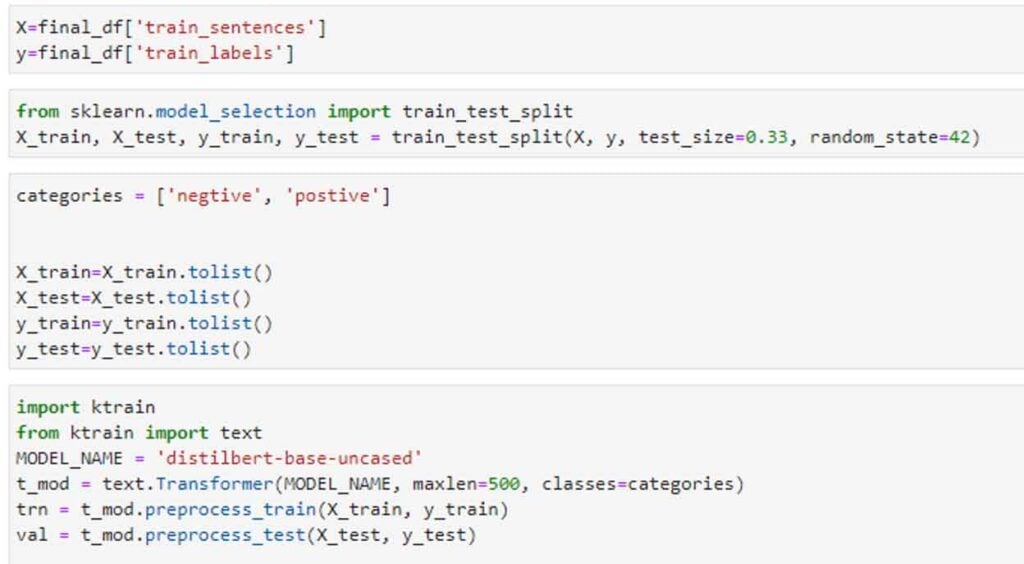
After text representation we can start the modelling process. Following are the steps to do the modelling. First, we get the transformer classifier, give the training set and the validation set as parameters, with a batch size of 6. We will run this for 4 epochs, but we can run this for more by monitoring the losses and training plot.
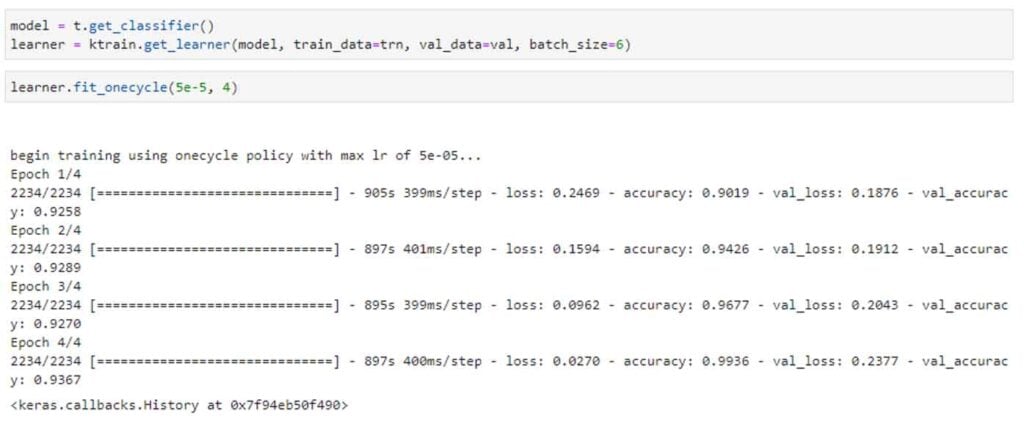
Then in the next step we can evaluate our model.
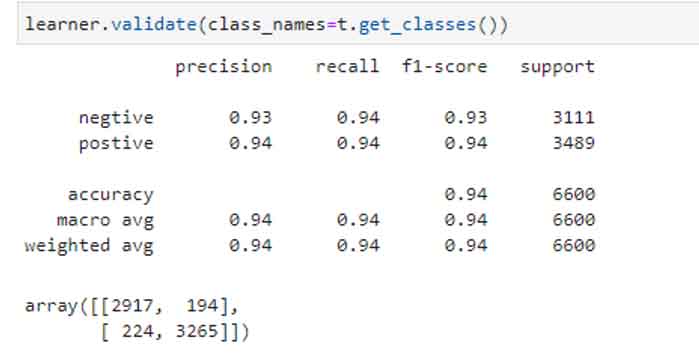
Awesome, with just 4 epochs we could manage a model of 94% accuracy. Well, let’s check one of the sentiments, and see what our model predicts.
Great, our model predicts accurately!
BERT has inspired NLP in a substantial way, especially the application of transformers. This has led to a lot of advancements in language modelling to understand language. Many of them like XLNet, ROBERTa, and ELECTRA have come up and have been outperforming BERT in different tasks.

Explore how we reduced order fulfillment time for a retail firm through NLP & AI integration.
So, ‘What next?’ you must be wondering. Well, we can try all these variants, get the most accurate model and deploy it. Write to us at Nitor Infotech with your thoughts about this blog! You may also enjoy reading this blog that explores an automated machine learning approach with H2O.ai.



