
In today’s day and age, we’re seeing exponential growth in the field of Artificial Intelligence & Machine Learning, and with it, significant advances in the tools used to build these models. In this blog I would like to introduce you to one such tool that makes the job of building robust AI-ML models extremely easy- H2O.
Allow me to give you a brief introduction to H2O, it is a fully open-source platform which aids distributed in-memory machine learning and facilitates linear scalability. It supports most statistical & machine learning algorithms and also comes with an AutoML functionality. With its core code written in Java, coupled with a REST API, H2O enables access to all of its capabilities from an external script. A platform that has gained massive popularity in both the R & Python communities, it has become a global favorite with over 18,000 organizations using it to automate machine learning.
I’m hoping that by now I’ve sold you on H2O as a platform. But let’s delve a little deeper and learn more about its nitty-gritties. Here are some of the key aspects commonly associated with H2O.
1. Leading Algorithms
H2o framework is a collection of fully tested implementations of numerous ML algorithms. All you need to do is pick up the best-suited algorithm for you from a comprehensive repository and apply it to your dataset. A few examples of these algorithms are Extreme Gradient Boosting (Xgboost), Deep Learning, Generalized Linear Model (GLM), anomaly detection, etc.
2. Access from R, Python, Flow, etc.
H2O can be easily configured and used with several different options as mentioned below
- Python
- R
- Web-based Flow GUI
- Hadoop
- Cloud Services
Of course, you can use any programming language that you’re comfortable with such as R, Python, etc. to build models in H2O. Another alternative is to use their web-based graphical notebook to build models that don’t require any form of coding.
3. AutoML
The process of building Machine Learning models as well as choosing the best model is extremely tedious. It takes many lines of code and consumes a lot of time to reach completion. However, Data Science and Machine Learning are fields associated with automation. Combine them and we have automated Machine learning or AutoML.
With a few lines of H2O’s AutoML, you can automate the ML workflow, including automatic training and tuning of models within a predetermined time limit. With this, you can train individual models as well as their ensembles to subsequently develop highly accurate models.
4. Distributed in-memory processing
H2O conducts in-memory processing aided by rapid serialization between nodes and clusters to support voluminous datasets. Its distributed processing on Big Data delivers speeds up to a 100x faster with fine grain parallelism, enabling optimal efficiency without reducing computational accuracy.
5. Simple Deployment
H2O enables you to transform your models into either a Plain Old Java Object (POJO) or a Model Object, Optimized (MOJO). It allows you to easily package the model H2O and deploy it to development in a way that it can scale to millions of rows of data. You should note that the MOJO and POJO models are easily embeddable in any Java environment. The only compilation and runtime dependency for a generated model is the h2o-genmodel.jar file produced as the build output for these packages.
Now, allow me to take you through some of H2O’s technical features & capabilities.
1. H2O Sparkling Water
With Sparkling Water, you can combine the fast and scalable machine learning algorithms of H2O with the abundant capabilities of Spark. Sparkling Water is ideal for H2O users who want to manage large clusters of data for their processing needs as well as for those who want to transfer data from Spark to H2O (or vice versa).
2. H2O4GPU
H2O4GPU is an open-source, GPU-accelerated ML package with APIs in both Python and R. With it, you can use GPUs to build advanced machine learning models.
3. H2O Driverless AI
H2O Driverless AI is H2O.ai’s commercial product specifically built for automatic machine learning. It can fully automate the most challenging and productive tasks in applied data science, including feature engineering, model tuning, model assembling, and model deployment.

H2O model interpretation interface encompasses several explainable methods and visualizations in H2O and can be used to easily derive global and local explanations for H2O models. Additionally, you can embed an MLOps layer to this which lets us know when to export our experiments into a shared MLOps project for collaboration and management. MLOps lets you monitor models with a variety of checks like drift detection and anomaly detection. Here, you can choose the model best suited for your needs and compare that to a Challenger model. Model Endpoint links also let you retrieve the deployed model endpoint with a cURL request.
We’ve seen the key aspects of H2O along with a few technologies that it features. Now, let’s go through an example to see how H2O performs. Here, I am using a real-world dataset based on online fraudulent transactions, as seen in a competition held in Kaggle organized by the IEEE Computational Intelligence Society.
1. Start H2O
First, you need to import the H2O Python module and H2OAutoML class and initialize a local H2O cluster. The H2O library can be installed by running pip. Next, you need to import the libraries in your jupyter notebook. By default, H2O instance uses all the cores along with about 25% of the system’s memory. However, in case we choose to allocate a fixed chunk of memory for it, we can specify it in the init function. Let us say we want to give the H2O instance 4GB of memory and permission to use 2 cores. Note that these parameters are optional.
h2o.init(nthreads=2,max_mem_size=4)

2. Importing Data with H2O in Python
Importing data in H2O is very similar to pandas.read_csv where data is stored in memory as an H2O Frame.

3. Modeling with H2O
You now have the dataset cleaned and ready for modelling. Now, you can identify the predictors as well as the response variables. Then, you can split it into training and testing part that can evaluate the model’s performance for which we can use the split_frame() function.

Here, we use AutoML functionality of H2O to build our models which are sorted based on their performance. Since this is a classification model, it is sorted based on AUC score by default. Here, AutoML will run for 30 base models for 7200 seconds. The default runtime is 1 hour.

4. Prediction and Evaluation
To generate predictions on a test set, we can make predictions directly on the ”H2OAutoML” object or on the leader model object directly.

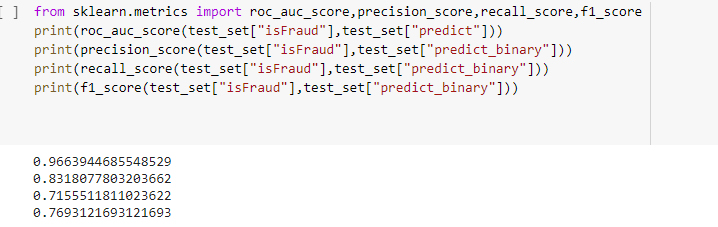
After this, we can evaluate the model and see the how it performs on the test set using metrics like precision score, recall score, f1 score, and AUC-ROC curve. For this competition, AUC-ROC was the performance metric. You can see that it is possible to have a great score by using just a few lines of code.
In addition to this, we will also plot a confusion matrix to to keep an eye on false positives and false negatives.


The same model was scored in Kaggle and it was a top 40 solution.
The “Auto” in AutoML suggests that the normal stages of the machine learning process are fully programmed to perform a sequence of tasks so that a layman can do it with ease.
At this juncture, we’re well acquainted with the basics of H2O and we can take a look at some positives and negatives of Automated Machine Learning which come along with it.
Benefits
AutoML actively integrates people to work with ML-based systems. This has several advantages – since ML is a more advanced form of Statistics, it allows for greater integrations into the overall infrastructure of the application. In some cases, the amount of data required is enormous, so integrating the world into the fold allows for better harvesting of data, subsequently yielding more optimized algorithms.
AutoML provides a great control over the solution. It brings down the chances of rework and repetitive tasks exponentially. Automated ML helps process the datasets by selecting, extracting, and engineering the features of the dataset, along with hyperparameter optimization. The accuracy it brings to the table is on the next level since it finetunes the model effectively, drastically reducing the error rate.
Challenges
One of the primary challenges with AutoML is that it ever so often overuses algorithms and low-level dynamics, without fully comprehending the full rendition of the problems at hand. Furthermore, the optimization of the modeling process becomes a Blackbox, which suffers from the problem of being treated as “a silver bullet”-something that will just magically work.
Most AutoML tools focus on performance, however, that’s just one aspect that gets covered in machine learning projects.
Additionally, we also can’t ignore the aspect of human intelligence required to build these machine learning models. On Kaggle, there are several developers who beat the programming of the latest AutoML tools with their stellar awareness.
So, after having read these challenges, why do I recommend the use of H2O? Let me sum it up for you. With H2O, you can
- Enhance the machine learnedness of your organization
- Integrate an existing workflow into the tool
- Effectively manage large volumes of data
- Receive adequate ML options for both supervised and unsupervised tasks
- Improve time-to-market by developing faster model iterations
- Collaborate with clients in a closed-loop system
- Avail strong machine learning community support
H2O has a very active and engaged user base in the open-source machine learning community. It has a lot of key aspects that enable it to handle missing or categorical data natively, a comprehensive modeling strategy, including powerful stacked ensembles, and the ease in which H2O models can be deployed and used in production environments.
H2O’s goal to make ML easy for everyone and to democratize AI, owing to which it is really growing at a rapid pace. With tools like these, it is possible to try and bridge the gap between the supply and demand of machine learning engineers.
At Nitor Infotech, we use the H2O framework for fast prototyping as well as for testing different ML ideas. The The platform handles feature engineering, validation, and hyper-parameters tuning which lets our team focus on the bigger picture, and high-level ML strategy. Also, the platform offers relevant model diagnosis and interpretations which help our data scientists gain insights and work accordingly with our partners.

Learn how we reduced order fulfillment time with NLP & AI integration for a retail distribution firm.
Reach out to us at to learn more about our cognitive engineering services and you can leverage them to transform your business processes.



