Highlights
DataOps extends DevOps principles to data management, automating the entire data lifecycle from ingestion through analytics delivery. Unlike DevOps’s focus on software, DataOps emphasizes data quality, validation, and collaboration between data engineers, scientists, and analysts. Key components include automated pipelines, continuous integration/deployment, data observability, and version control.
Implementation challenges include cultural shifts, complex tooling, skills gaps, and maintaining data quality at scale. By 2026, the landscape evolved dramatically: AI-native integration became standard, real-time replaced batch processing, and DataOps converged with MLOps. Real-world implementations at Netflix, Airbnb, and LinkedIn demonstrate measurable ROI through faster insights and improved data trust.
In today’s data-driven world, organizations are grappling with an ever-increasing volume and complexity of data. Vast amounts of raw and unprocessed data from various sources are stored in a central repository known as data lake. Extracting meaningful insights from this data lake requires a systematic and efficient approach that goes beyond traditional data management methods. This is where DataOps steps in.
What is DataOps?
DataOps short for Data Operations, was brought into attention by Lenny Liebmannin in 2014. It is an approach that focuses on the integration and collaboration between data engineers, data scientists, and other data focused professionals within an organization.
DataOps essentially is a mixture of lean manufacturing, agile development, and DevOps. It is an organization-wide data management method that controls the flow of data from source to value. It combines data engineering and data science teams to support an organization’s data needs.
In essence, it is a practice that helps organizations manage and govern data effectively.
In this blog, we will delve into the fundamentals of DataOps, its key principles, benefits, challenges and much more!
Before we get into the core concepts of DataOps, it is necessary to understand the difference between DataOps and DevOps, two terms often used interchangeably.
What is the difference between DataOps and DevOps?
Both, DataOps and DevOps share common principles and practices, as the former draws inspiration from the latter and applies it specifically to data management and analytics. However, here are some differentiating points between the two:
- Focus: DevOps primarily focuses on the collaboration and integration between software development (Dev) and IT operations (Ops) teams to streamline software delivery and infrastructure management. DataOps, on the other hand, extends these principles to data-related processes, emphasizing the collaboration between data engineers, data scientists, and other data-focused roles to optimize data workflows and analytics.
- Data Lifecycle: DevOps mainly deals with the software development lifecycle, including code development, testing, deployment, and maintenance. DataOps encompasses the entire data lifecycle, including data ingestion, processing, transformation, analytics, and delivery of insights. It addresses the challenges specific to managing and analyzing large volumes of data effectively.
- Automation: Both DevOps and DataOps rely on automation to increase efficiency and reduce manual effort. DevOps automates software build, testing, deployment, and infrastructure provisioning. DataOps automates data workflows, data pipelines, data integration, and data quality processes. Automation in both domains leads to repeatability, consistency, and faster time-to-market.
- Collaboration and Communication: Both methodologies emphasize cross-functional collaboration and effective communication. DevOps encourages close collaboration between development and operations teams to ensure smoother releases and better alignment with business objectives. DataOps promotes collaboration between data engineers, data scientists, and business stakeholders to align data initiatives with business needs, enable seamless knowledge sharing, and ensure the delivery of high-quality insights.
- Continuous Integration and Deployment: DevOps promotes continuous integration and continuous deployment (CI/CD), enabling frequent and incremental updates to software systems. DataOps similarly embraces continuous integration and deployment practices to allow for faster data pipeline updates, analytics model iterations, and data-driven insights. It focuses on delivering value to stakeholders through shorter feedback cycles.
- Monitoring and Feedback: Both methodologies emphasize the importance of monitoring and feedback loops. DevOps emphasizes the monitoring of application performance, infrastructure health, and user feedback to drive continuous improvement. DataOps emphasizes monitoring data pipelines, data quality, and analytics performance to ensure reliable and high-quality insights. Feedback loops in DataOps help iterate on data processes and models for better accuracy and relevance.
However, the DataOps lifecycle takes inspiration from the DevOps lifecycle, but incorporates different technologies and processes. Data observability runs across the DataOps framework to facilitate faster and more reliable insights from data.
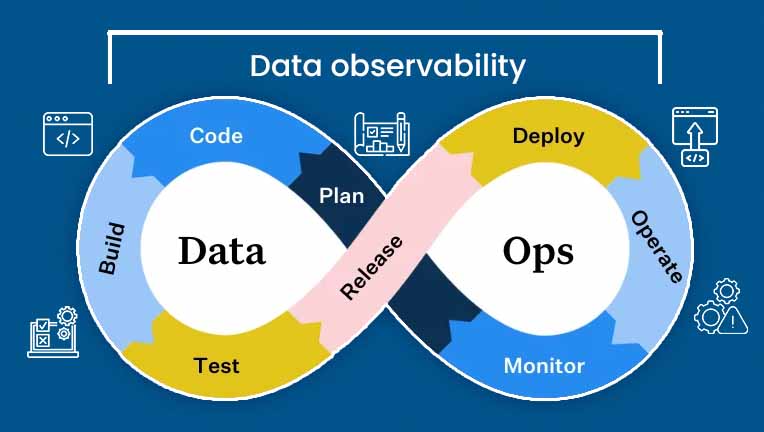
As we navigate 2026, the lines between DataOps and DevOps continue to blur, but in productive ways. The emergence of AI-native applications has created a new hybrid discipline where data pipelines directly feed machine learning models in production. Organizations are no longer choosing between DataOps and DevOps; they’re integrating both into unified MLOps and AIOps frameworks.
What changed in 2026?
- AI-Native Integration: Modern DataOps platforms now seamlessly integrate with LLM training pipelines and Gen AI applications. Data engineers work alongside AI engineers to ensure training data quality, manage prompt engineering workflows, and monitor model drift, all within the same DataOps framework.
- Real-Time as Standard: While batch processing dominated traditional DataOps, 2026 has shifted baseline expectations to real-time data streaming. Organizations now expect sub-second data freshness for operational analytics and AI/ML applications. The question isn’t “Should we implement real-time?” but “How fast can our DataOps support it?”
- DataOps + MLOps Convergence: The artificial separation between data pipeline management and ML model deployment has collapsed. In 2026, mature organizations treat data transformation, feature engineering, model training, and deployment as a single continuous workflow. Tools that only handle DataOps or only handle MLOps are being phased out in favor of integrated platforms.
- Cloud-Native Evolution: Multi-cloud and hybrid DataOps architectures have become the norm, not the exception. Organizations in 2026 are running DataOps workflows across AWS, Azure, and Google Cloud simultaneously, with data mesh architectures enabling decentralized data ownership while maintaining centralized governance.
I hope I have made the two concepts clear. Let’s move further into the core of DataOps.
Let’s see what role does DataOps play in the modern, data-driven world.

From ideation to deployment, AI can redefine your development journey. Start building smarter solutions today and position your organization for scalable, sustainable growth.
What is the Role of DataOps?
Here’s how transitioning to a DataOps strategy can be pivotal to organizational growth-
- Make Data Operations Efficient: DataOps brings efficiency to data operations by promoting collaboration, automation, and streamlined workflows. By implementing DataOps practices, organizations can reduce manual effort, minimize errors, and achieve faster data processing and analytics.
- Improve Time-to-Insights: DataOps facilitates faster time-to-insights by enabling rapid prototyping, continuous integration, and deployment of data pipelines and analytics models. It allows organizations to deliver insights to stakeholders more quickly, ensuring they have the most up-to-date information for decision-making.
- Enhance Data Quality: DataOps emphasizes data quality and governance throughout the data lifecycle. It promotes data profiling, validation, and cleansing techniques, ensuring that data is accurate, consistent, and reliable. By focusing on data quality, DataOps helps organizations make better decisions based on trustworthy and high-quality data.
- Bring in Agility and Adaptability: DataOps adopts an agile and iterative approach, enabling organizations to respond quickly to changing business needs and market dynamics. It fosters a culture of experimentation and continuous improvement, allowing teams to iterate on data pipelines, models, and analytical processes.
- Promote Collaboration and Cross-Functional Teams: DataOps promotes collaboration between different teams involved in data operations. It breaks down silos and fosters cross-functional teams that work together throughout the data lifecycle. Collaboration and knowledge sharing among teams lead to better insights, improved decision-making, and a shared understanding of data-related challenges and opportunities.
- Improve Scalability and Resilience: DataOps leverages automation, infrastructure as code, and cloud technologies to scale data processing and analytics capabilities. It ensures that data pipelines can handle growing workloads and provides resilience through monitoring, error handling, and automated recovery mechanisms.
- Enforce Compliance and Data Governance: DataOps helps organizations implement data governance policies, security measures, and regulatory compliance. It enables organizations to ensure that data is handled responsibly, protecting sensitive information and mitigating risks associated with data breaches or non-compliance.
What are the Key Principles and Components of DataOps?
The key components of DataOps include-

1. Continuous Integration and Continuous Deployment (CI/CD) pipelines : CI/CD pipelines are integral components of DevOps and DataOps practices. They enable organizations to automate and streamline the process of building, testing, and deploying software applications or data pipelines. They facilitate faster delivery, improved code quality, and streamlined collaboration, supporting the goal of efficient and reliable data operations.
2. Automated data pipelines and workflows : Automated data pipelines play a critical role in efficiently managing and processing large volumes of data, ensuring data quality, and enabling timely insights. Automated data pipelines can automatically fetch data from various sources, such as databases, APIs, file systems, or streaming platforms. Ingestion processes may include data extraction, data loading, and data synchronization to capture the latest data changes.
3. Agile and iterative approach: DataOps adopts an agile and iterative approach to data operations, breaking down tasks into smaller, manageable units and delivering value incrementally. It encourages rapid prototyping, continuous integration, and continuous delivery to enable faster and more frequent deployments of data pipelines, analytical models, and insights.
4. Monitoring and Alerting: DataOps emphasizes the monitoring of data pipelines, analytics processes, and data quality. Monitoring tools and techniques are employed to track data ingestion, processing, and transformation, ensuring the timely detection of issues or anomalies. Alerting mechanisms are set up to notify stakeholders about any failures or performance degradation, enabling proactive response and reducing downtime.
Now that we have an idea of the role and principles of DataOps, let’s take a look at some of the challenges that might come with it.
What are the Challenges in DataOps Implementation?
DataOps Implementation comes along with certain challenges, which include-
- Significant Cultural Shift: Adopting DataOps requires a cultural shift within an organization. It involves breaking down silos and fostering collaboration between different teams, such as data engineers, data scientists, analysts, and business stakeholders. Overcoming resistance to change and encouraging a culture of shared responsibility, transparency, and continuous learning is crucial for successful DataOps implementation.
- Tedious Upskilling and Training: DataOps requires a diverse skillset that combines knowledge of data engineering, data science, DevOps practices, and domain expertise. Organizations may need to invest in training and upskilling their teams to ensure they have the necessary skills and expertise to implement and operate in a DataOps environment effectively.
- Complex Tooling and Infrastructure: Implementing DataOps often involves adopting and integrating various tools and technologies for data management, automation, monitoring, and collaboration. Selecting the right tools that align with the organization’s requirements, infrastructure, and future scalability is essential. Considerations should also be given to the integration of existing systems and legacy technologies with new DataOps tools.
- Data Quality and Validation: Maintaining data quality is vital in DataOps. Implementing data validation, profiling, and cleansing techniques is essential to ensure accurate and reliable data for analytics and decision-making. Organizations need to define data quality metrics, establish data validation rules, and implement mechanisms to track and monitor data quality throughout the data lifecycle.
- Assured Scalability and Performance: As data volumes and processing requirements grow, scalability and performance become critical considerations. Organizations need to design data pipelines and infrastructure to handle increasing workloads efficiently. This may involve implementing distributed processing frameworks, leveraging cloud-based services, or optimizing data storage and retrieval mechanisms.
- AI Data Governance Crisis: The explosion of Gen AI and LLM applications has created unprecedented data governance challenges. Organizations now struggle with questions previous frameworks never addressed: How do we govern synthetic data generated by AI? What’s our liability when LLMs are trained on customer data? How do we maintain data lineage when AI models transform data in non-deterministic ways? In 2026, DataOps teams spend significant time implementing AI-specific governance frameworks that didn’t exist two years ago.
- Real-Time Data Quality at Scale: Moving from batch to real-time processing has exposed a truth: data quality issues that were manageable in daily batch runs become catastrophic when they propagate in milliseconds. Organizations in 2026 are discovering that their data validation rules, built for batch processing, completely fail in streaming environments. The challenge isn’t just detecting bad data, it’s detecting it fast enough to prevent downstream AI/ML models from making decisions based on garbage inputs.
- Multi-Cloud Data Orchestration Complexity: While cloud adoption solved some problems, multi-cloud DataOps has introduced new ones. Organizations in 2026 are managing data pipelines that span AWS, Azure, Google Cloud, and on-premises infrastructure simultaneously. Data gravity, egress costs, latency requirements, and regulatory constraints create a three-dimensional chess game where moving data between clouds can cost more than processing it.
- The Skills Gap Widened: The DataOps skills gap hasn’t closed; it’s expanded. In 2026, teams need expertise in traditional data engineering, cloud-native architectures, streaming frameworks, ML operations, data mesh principles, and now AI governance. Finding engineers with this combination is nearly impossible, forcing organizations to either invest heavily in upskilling or accept that their DataOps implementation will have capability gaps.
- Regulatory Compliance Acceleration: Data privacy regulations haven’t slowed down. GDPR evolved, CCPA strengthened, and new AI-specific regulations (like the EU AI Act) now govern how training data must be managed. In 2026, DataOps teams spend substantial effort implementing automated compliance workflows; data lineage tracking, automated PII detection, consent management, and audit trails that can withstand regulatory scrutiny.
- Cost Optimization Pressure: Cloud costs for data operations have become unsustainable for many organizations. What seemed efficient at pilot scale became expensive at production scale. In 2026, DataOps teams face intense pressure to optimize cloud spending while maintaining performance. This means implementing intelligent data tiering, rightsizing compute resources, optimizing storage classes, and sometimes making difficult trade-offs between speed and cost.
- Legacy System Integration Hell: Most organizations don’t have the luxury of greenfield DataOps implementations. They’re integrating modern DataOps practices with mainframes, on-premises databases, legacy ETL tools, and custom-built systems that predate cloud computing. In 2026, this integration challenge hasn’t disappeared; it’s just become more complex as the technology stack grows.
Now, let’s look at some popular examples of DataOps!
Real-world Examples and Case Studies of DataOps Implementation
Allow me to present some examples that will help you understand DataOps better.
- Netflix: Netflix, a leading global entertainment company, has embraced DataOps to streamline their data operations and analytics. They adopted a self-serve DataOps model, enabling data scientists and engineers to access and analyze data more efficiently. Netflix built a data platform called “Metacat” that facilitates data discovery, lineage tracking, and metadata management. This DataOps approach has allowed Netflix to accelerate data insights, improve collaboration, and drive data-driven decision-making.
- Airbnb: Airbnb, a popular online marketplace for accommodations, implemented DataOps to optimize their data infrastructure and analytics workflows. They developed an internal platform called “Airflow” that enables teams to define, schedule, and monitor data pipelines. By automating their data workflows, Airbnb reduced manual effort, improved data reliability, and enabled faster data-driven insights. DataOps practices have empowered their teams to iterate quickly, experiment with data models, and deliver high-quality insights to drive business growth.
- LinkedIn: LinkedIn, the professional networking platform, implemented DataOps to enhance their data operations and analytics capabilities. They developed an internal platform called “Databus” that enables real-time data streaming, processing, and analytics. LinkedIn’s DataOps approach emphasizes automation, scalability, and data quality, allowing them to handle large volumes of data and deliver timely insights to their users. DataOps has helped LinkedIn streamline their data workflows, improve data reliability, and enable faster data-driven decision-making.
- Salesforce: Salesforce, a leading customer relationship management (CRM) platform, has implemented DataOps to enhance their data management and analytics capabilities. They leverage a DataOps approach to automate data integration, data quality checks, and data governance processes. By implementing DataOps, Salesforce has improved data accessibility, accelerated data delivery, and enabled more effective data-driven decision-making for their customers.
Each example here demonstrates how DataOps practices have transformed data operations, enabling faster insights, improved collaboration, and enhanced data-driven decision-making. These real-world examples highlight the benefits and impact that DataOps can have on organizations across various industries.
Well, let me quickly wrap up my ideas!
DataOps represents a transformative shift in how organizations approach data management and analytics. By embracing the principles of collaboration, automation, and continuous improvement, DataOps empowers businesses to unlock the true value of their data assets. It enables faster, more reliable data operations, empowers cross-functional teams, and drives data-driven decision-making.
Reach out to us to share your feedback about this blog and visit us at Nitor Infotech.



