
Today, data engineering and integration projects demand adept data transformation to reconcile diverse data formats and structures. This intricate process involves tasks like mapping specific fields, reshaping JSON payloads, and managing complex nested data. Here, DataWeave acts as the Swiss Army knife in the MuleSoft world. It is a powerful and flexible transformation language that allows you to manipulate data within your MuleSoft integrations.
This blog compares DataWeave with Python, exploring how DataWeave serves as the key to solving data transformation intricacies. It aims to provide MuleSoft developers with the tools to simplify complex data manipulation and elevate integration workflows.
Additionally, you will explore three common DataWeave expressions and their real-world applications, providing step-by-step explanations and examples.
So, let’s get started!
Simplifying Data Transformation Challenges: Python vs. DataWeave
Here’s a comparison table to help you decide between Python and DataWeave:
| Aspect | Python | DataWeave |
|---|---|---|
| Complexity | More complex and requires deeper understanding | Simple and designed for integration tasks |
| Syntax | More verbose | Concise and expressive |
| Learning Curve | Steeper, especially for new users | Easier to learn and integrate |
| Lines of Code | More lines required compared to DataWeave | Fewer lines needed for complex transformations |
| Maintenance | Time-consuming | Easier maintenance due to simpler syntax |
So, i hope it is clear that when looking for a user-friendly and efficient solution for data transformation within your integrations, DataWeave should be your answer.
Let’s further analyze the performance of DataWeave and Python to provide you with a comprehensive comparison. This will help you understand why choosing DataWeave may be the better option.
Performance Analysis: MuleSoft DataWeave Vs. Python Data transformation
Here are the five pointers that will help you make the right choice for your data transformation journey:
1. Based on Execution Speed:
DataWeave is optimized for data transformation within the MuleSoft Anypoint Platform. It leverages the underlying MuleSoft engine to execute transformations efficiently.
Python, on the other hand, is a general-purpose programming language and may not be as optimized for data transformation as DataWeave. However, the execution speed can vary depending on the complexity of the transformation logic and the specific implementation in both languages.
2. Based on Memory Usage:
DataWeave is designed to handle large datasets efficiently within the MuleSoft runtime environment. It uses a streaming approach to process data, which minimizes memory usage.
Python, on the other hand, may require more memory depending on the specific libraries and frameworks used for data transformation.
3. Based on Parallel Processing:
DataWeave supports parallel processing, allowing for faster execution of data transformation tasks. It can take advantage of multi-core processors to process data concurrently.
Python also offers parallel processing capabilities through libraries like ‘multiprocessing’ or ‘concurrent.futures’, but utilizing them requires explicit implementation.
4. Based on Integration with External Systems:
DataWeave is tightly integrated with the MuleSoft Anypoint Platform, enabling seamless integration with other MuleSoft components and connectors.
On the other hand, Python can be integrated with various systems and tools using libraries and APIs, providing flexibility in terms of data source and destination.
5. Based on Ecosystem and Community Support:
Python has a vast ecosystem of libraries and frameworks specifically designed for data transformation, such as Pandas, NumPy, and PySpark. These libraries offer optimized algorithms and data structures for efficient data manipulation.
DataWeave, on the other hand, is a specialized language within the MuleSoft ecosystem and has limited community support compared to Python.
Hope you got the idea of what you want to go for! 😊
Onwards we move to the three typical DataWeave expressions as mentioned earlier.
3 Key DataWeave Expressions for Efficient JSON Field Mapping
Here are the three key DataWeave expressions for efficient JSON field mapping, simplifying your data transformation process:
Section 1: Mapping Fields in JSON Payload
i. Consider the following JSON data:
{
"values": [
{
"id": 1,
"self": "https://example.com/1",
"name": "John Doe",
"type": "User"
},
{
"id": 2,
"self": "https://example.com/2",
"name": "Jane Smith",
"type": "User"
}
]
}
ii. You can use DataWeave to map specific fields in the JSON payload like this:
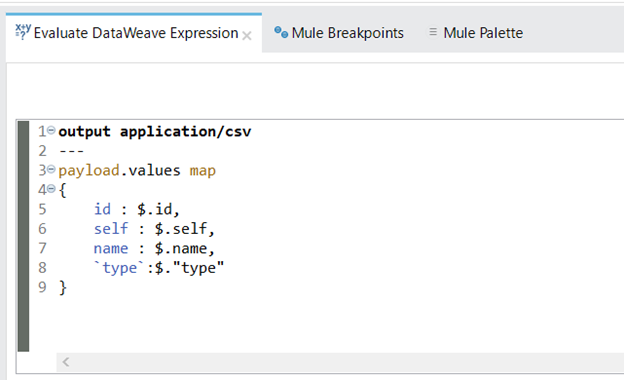
Fig: DataWeave Expression 1
iii. The following output will be generated:

- The ‘map’ function iterates over each object in the ’values’ array.
- The ‘$’ symbol refers to the current object being processed.
- The expression ‘{id $.id, self: $.self, name: $.name, ‘type’: $.type}’ creates a new object with the desired fields and their respective values.
Section 2: Transforming JSON Payload
i. Let’s consider the following JSON data:
[
{
"id": 1,
"key": "ISSUE-001",
"fields": {
"issuetype": {
"name": "Bug"
},
"resolution": {
"name": "Fixed"
},
"priority": {
"name": "High"
},
"project": {
"key": "PROJ-001"
}
}
},
{
"id": 2,
"key": "ISSUE-002",
"fields": {
"issuetype": {
"name": "Task"
},
"resolution": {
"name": "Unresolved"
},
"priority": {
"name": "Medium"
},
"project": {
"key": "PROJ-002"
}
}
}
]
ii.You can use the following DataWeave expression to transform the JSON payload:

Fig: DataWeave Expression 2
iii. This output will be generated:

- The ‘map’ function iterates over each object in the payload.
- The ‘(issue, index01)’ parameters represent the current object and its index.
- The expression creates a new object with the desired fields and their values from the nested structure.
Section 3: Filtering and Flattening Nested Data
i. Let’s start with the following sample JSON payload:
{
"id": "ISSUE-001",
"changelog": {
"histories": [
{
"id": "1",
"created": "2022-12-15T10:30:00",
"author": {
"displayName": "John Smith"
},
"items": [
{
"field": "status",
"fromstring": "Open",
"toString": "In Progress"
},
{
"field": "assignee",
"fromstring": "Jane Doe",
"tostring": "John Doe"
}
]
},
{
"id": "2",
"created": "2022-12-16T15:45:00",
"author": {
"displayName": "Jane Doe"
},
"items": [
{
"field": "status",
"fromstring": "In Progress",
"tostring": "Done"
}
]
}
]
}
}
ii. You can use the following DataWeave expression to filter and flatten nested data:

Fig: DataWeave Expression 3
iii. Here’s the generated output:

- The ‘flatMap’ functions are used to iterate over objects in the payload hierarchy.
- The ‘filter’ function ensures that only objects with a valid ‘issue.id’ is are processed.
- The ‘map’ function creates a new object for each filtered item, extracting specific fields and formatting the created field.
So, in a nutshell, whether you are restructuring JSON payloads or managing complex nested structures, DataWeave simplifies these tasks.
This proficiency proves invaluable in real-time scenarios, particularly within financial or e-commerce domains, where data from various sources can be swiftly converted to standardized formats for seamless processing.
Through our exploration of three common DataWeave expressions, each tailored to address specific data transformation scenarios, you are now equipped to confidently tackle a wide array of challenges in your MuleSoft projects.
For hands-on practice, you can utilize the DataWeave playground available at https://dataweave.mulesoft.com/learn/dataweave.
If you wish to learn more about the DataWeave in MuleSoft and its best practices, feel free to reach out to us at Nitor Infotech.




