
Machine learning has revolutionized the way we analyze data and make predictions across various industries since the past few years. However, what if you could harness the power of machine learning directly within your SQL queries? Enter BigQuery ML, a significant innovation that seamlessly integrates machine learning capabilities into Google BigQuery.
In this blog, I’ll help you learn about BigQuery ML, its architecture, and key features. Additionally, you’ll delve into the details of how it works with a real-life example.
So, let’s get started with the basics!
What is BigQuery ML?
BigQuery ML is an innovative fusion that allows data analysts and data scientists to harness the power of machine learning without the need for extensive ability in traditional ML frameworks.
The beauty of BigQuery ML lies in its simplicity. It allows users to build and deploy machine learning models using SQL queries, eliminating the need to transfer data between different platforms or learn complex programming languages.
By using familiar SQL syntax, data analysts can seamlessly transition into the world of machine learning, making predictive analytics more accessible to a broader audience within an organization.
Now let’s get to know about its key features and explore how it is revolutionizing the landscape of data analysis and predictive modeling.
Key Features of BigQuery ML
1. Familiar SQL Interface: BigQuery ML integrates smoothly with SQL, enabling data analysts and engineers to leverage their existing SQL skills for machine learning tasks. With this integration, you can effortlessly develop, train, and evaluate ML models right within BigQuery.
2. Wide Range of Algorithms: It supports several types of machine learning models, including regression, classification, clustering, collaborative filtering, and time-series forecasting. Each model serves a unique purpose depending on your data and the problem you’re trying to solve.
3. Scalability and Performance: Built on Google’s infrastructure, it can handle massive datasets with ease. It automatically scales to accommodate growing data volumes, ensuring fast and efficient model training even with petabytes of data.
4. Automatic Feature Engineering: It simplifies the feature engineering processes by automatically generating features from raw data. It includes tasks like normalizing numerical features and encoding categorical variables. This helps to speed up model development and streamline the data preparation process.
5. Easy Model Evaluation and Deployment: From AI (Artificial Intelligence) model training to evaluation and deployment, it provides a seamless end-to-end workflow within the BigQuery environment. Users can easily evaluate model performance and deploy trained models for inference, integrating predictive analytics seamlessly into their existing workflows.

Learn how we helped a retail company with a GenAI-powered solution for swift data analysis and deep customer insights.
Now that you’re familiar with the basics, let me walk you through BigQuery’s architecture before jumping into the example.
Architecture of BigQuery
BigQuery’s architecture efficiently handles large-scale data processing to meet diverse analytical needs.
- At its core is Colossus, Google’s distributed file system, which provides robust storage infrastructure capable of managing petabytes of data across thousands of machines, ensuring high availability and fault tolerance.
- Another key component is Dremel. This is a powerful query engine optimized for interactive ad-hoc queries. Using a columnar storage format and a distributed execution model, Dremel allows for efficient execution of complex SQL-like queries, delivering rapid insights even on vast datasets.
BigQuery integrates with Jupyter notebooks, offering a familiar environment for data exploration and analysis. This promotes collaboration and experimentation.
With its serverless model and automatic scaling capabilities, it abstracts the complexities of infrastructure management, allowing users to focus on extracting valuable insights from their data.
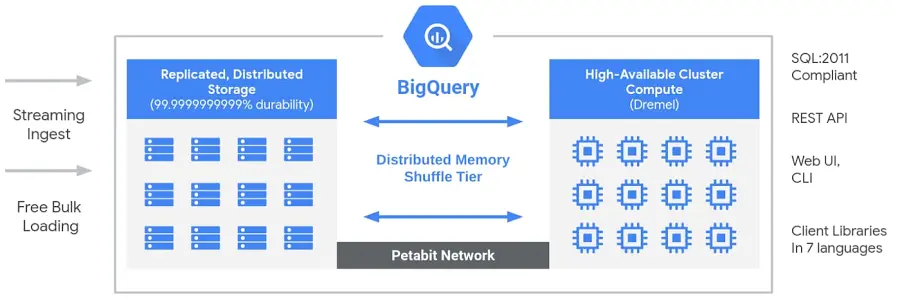
Fig: Architecture of BigQuery
Now, let’s get into the nitty-gritties with an example.
To embark on your machine learning journey with BigQuery ML, all you need is a Google Cloud Platform account and access to BigQuery.
Enabling BigQuery ML in your Google Cloud project is a straightforward process. You can do it through the Google Cloud Console or use the bq command-line tool.
Building a Classification Model for predicting the Survivors in the Titanic Disaster

This approach doesn’t aim to retell the events of the sinking. Instead, it focuses on analyzing historical data about the passengers. By considering factors like age, class, and other relevant information, we can attempt to estimate the likelihood of survival for each passenger based on these factors.
First, we need to create a dataset in BigQuery named Titanic and import the downloaded Titanic CSV file as a table in the Titanic dataset.
To know more about the dataset, you can visit Kaggle’s website.
Note: We have created a new project named ‘titanic-421418’ for this exercise. So, don’t get confused when you see the name of the project for referencing the tables and models. Also, for the exploratory data analysis, we have used the training dataset only. The code for splitting the dataset into train and test set is included in the later part of this blog.
Step 1: Understanding the Variables
We will start by understanding the variables in our dataset. The Titanic dataset includes both numerical and categorical variables. Here are the datasets for both:
- Numerical Variables: PassengerId, Survived, Pclass, Age, SibSp, Parch, and Fare
- Categorical Variables: Name, Sex, Ticket, Cabin, and Embarked
Step 2: Data Analysis
Next, we’ll analyze the data based on three parameters.
a. Follow this code to get insights about the data according to gender:
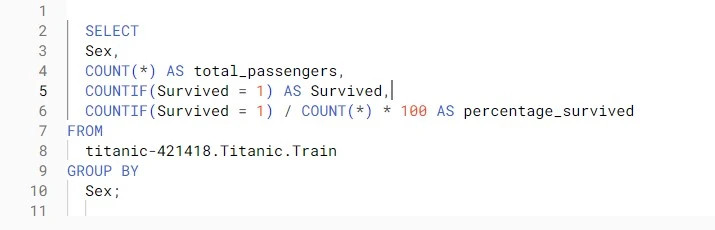

Conclusion from the analysis – Female passengers have a higher likelihood of survival compared to males.
b. Follow this code to get insights about the data according to class:
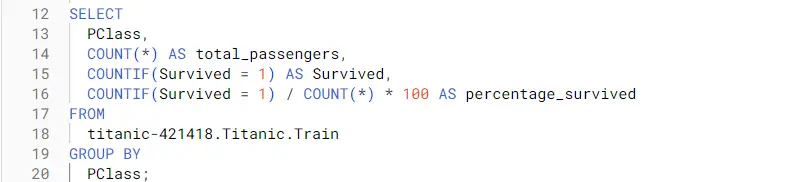

Conclusion from the analysis – Passengers of higher class (PClass 1) are more likely to survive.
c. Follow this code to get insights about the data according to age:


Conclusion from the analysis – Elderly individuals are more likely to travel in higher classes.
Step 3: Data Cleaning
It’s time to clean the data to ensure we have the most relevant and accurate information. We need to follow these steps to clean the data:
- Dropping Irrelevant Columns: We’ll drop high cardinality columns like PassengerId and irrelevant columns like Name and Ticket as they add no value to our prediction efforts.
- Combining Related Features: SibSp (number of siblings/spouses aboard) and Parch (number of parents/children aboard) will be combined into one column named Total_number_of_relatives, that will provide a more meaningful representation.
- Dropping Fare and Cabin Columns: Since Fare information is already contained in the Pclass column and the Cabin column has a lot of null values with no logical way of handling them, we’ll drop these columns.
Step 4: Encoding Categorical Variables
Now, we’ll encode the remaining categorical variables, like “Sex” and “Embarked”, to numerical values to make them suitable for modeling.
Step 5: Handling Missing Values
In this step, we’ll replace null values in the Age column with the average age of the Pclass that the passenger belongs to. This will ensure that we keep the integrity of the data while handling missing values effectively.
Step 6: Model Training and Evaluation
Here’s the breakdown of the coded parts starting from table creation to evaluation for training and test data:
Creating Temporary Table
First, we will create a temporary table with a random “is_training” flag to split data into train and test set. We will follow this code:
DECLARE split_ratio FLOAT64 DEFAULT 0.8; CREATE OR REPLACE TABLE titanic-421418.Titanic.training_or_holdout AS ( SELECT *, RAND() < split_ratio AS is_training FROM titanic-421418.Titanic.data); CREATE OR REPLACE TABLE titanic-421418.Titanic.train AS SELECT * FROM Titanic.training_or_holdout WHERE is_training; CREATE OR REPLACE TABLE titanic-421418.Titanic.test AS SELECT * FROM Titanic.training_or_holdout WHERE NOT is_training;
Note: The Titanic dataset initially contained 891 records, split into training and testing datasets in an 80:20 ratio.
a. Cleaning the Training Data
Now, we need to clean the training data. To do so, we will use this code:
CREATE OR REPLACE TABLE titanic-421418.Titanic.train_clean AS SELECT PassengerId, ROUND(IFNULL(Age, AVG(Age) OVER (PARTITION BY Pclass)), 2) AS Age, CASE WHEN Sex = 'male' THEN 0 WHEN Sex = 'female' THEN 1 ELSE NULL END AS Sex, CASE WHEN Embarked = 'C' THEN 0 WHEN Embarked = 'Q' THEN 1 WHEN Embarked = 'S' THEN 2 ELSE NULL END AS Embarked, Pclass, (SibSp + Parch) AS Number_of_Relatives, Survived FROM titanic-421418.Titanic.train;
b. Creating the Model
To create the model, we will follow this code:
CREATE OR REPLACE MODEL `titanic-421418.Titanic.log_reg` OPTIONS(model_type='logistic_reg') AS SELECT Age, Sex, Embarked, Pclass, Number_of_Relatives, Survived AS label FROM `titanic-421418.Titanic.train_clean`;
c. Evaluation Stage
After creating the model, we will evaluate it using this code:
SELECT * FROM ML.EVALUATE(MODEL `titanic-421418.Titanic.log_reg`);
In the preceding steps, we successfully trained the model. Following the training, BigQuery automatically computes the evaluation metrics for the model.
Here are the results:
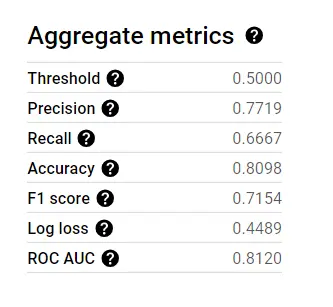
a. Cleaning the test data
We first need to clean the test data. To do so, we will use this code:
CREATE OR REPLACE TABLE titanic-421418.Titanic.test_clean AS SELECT PassengerId, ROUND(IFNULL(Age, AVG(Age) OVER (PARTITION BY Pclass)), 2) AS Age, CASE WHEN Sex = 'male' THEN 0 WHEN Sex = 'female' THEN 1 ELSE NULL END AS Sex, CASE WHEN Embarked = 'C' THEN 0 WHEN Embarked = 'Q' THEN 1 WHEN Embarked = 'S' THEN 2 ELSE NULL END AS Embarked, Pclass, (SibSp + Parch) AS Number_of_Relatives FROM titanic-421418.Titanic.test;
b. Prediction
Next, we’ll use this code for the model to predict the results:
SELECT * FROM ML.PREDICT(MODEL `titanic-421418.Titanic.log_reg`, ( SELECT PassengerId, Age, Sex, Embarked, Pclass, Number_of_Relatives FROM `titanic-421418.Titanic.test_clean`));
c. Confusion Matrix
To sort out the data and avoid any overlapping, use this code:
CREATE OR REPLACE TABLE Titanic.test_predicted AS SELECT A.PassengerId, B.Survived AS actual, A.predicted_label AS predicted FROM ( SELECT * FROM ML.PREDICT(MODEL `titanic-421418.Titanic.log_reg`, ( SELECT PassengerId, Age, Sex, Embarked, Pclass, Number_of_Relatives FROM `titanic-421418.Titanic.test_clean`)))A INNER JOIN `titanic-421418.Titanic.test` B ON A.PassengerId = B.PassengerId ; SELECT actual, predicted, COUNT(*) AS count FROM Titanic.test_predicted GROUP BY actual, predicted ORDER BY actual, predicted;
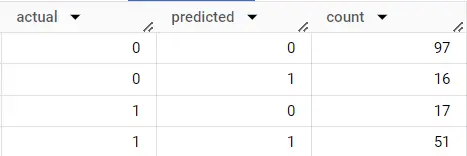
This is how we can calculate the accuracy of the trained model using predictions on the test dataset.
Accuracy = (True Positives + True Negatives) / (True Positives + False Positives + True Negatives + False Negatives) = (51 + 97) / (51 + 16 + 97 + 17) = 148 / 181 = 0.81
So, it can be concluded that the model’s accuracy is very close to the accuracy calculated during the training phase on the holdout dataset.
In a nutshell, whether it’s predicting survival rates or tackling complex business problems, BigQuery ML makes machine learning accessible and intuitive. So, dive in and unlock the potential of BigQuery ML for your data analysis needs.
Feel free to reach us at Nitor Infotech for your diverse analytical requirements and scale your business faster.



