Computer vision is a field of Artificial Intelligence (AI) that allows computers and other systems to obtain meaningful insights from images, videos, and so on. Then, based on that information, some actions can be taken, or recommendations can be made. Google Cloud Platform is one of the many cloud computing platforms offering computer vision services.
The one that I am going to focus upon in my blog today is Google Cloud Vision, also known as Vision API. Vision detection can easily be integrated with many applications, like face detection, landmark detection, image labelling, OCR, etc. Powerful pre-trained machine learning models are offered by Vision AI through REST & RPC APIs. Labels can be assigned to images and rapidly classified into millions of predefined categories. Objects and faces can be detected, printed and handwritten text can be read, and valuable metadata can be built into your image catalog.
So, for starters, let’s dive into the features of Google Cloud Vision!
Features of Google Cloud Vision
Several types of detection are possible using Google Cloud Vision. A few of them are as follows:
| CROP_HINTS | Suggested vertices for a crop region on an image are determined. |
| FACE_DETECTION | Faces within the image are detected. |
| IMAGE_PROPERTIES | Sets of image properties are computed, like dominant colors in an image. |
| LABEL_DETECTION | Adding labels based on image content. |
| LANDMARK_DETECTION | Geographic landmarks within the image are detected. |
| LOGO_DETECTION | Company logos within the image are detected. |
| OBJECT_LOCALIZATION | Extract after detecting multiple objects in an image. |
| SAFE_SEARCH_DETECTION | Safe Search detects likely unsafe or undesirable content. |
| TEXT_DETECTION & DOCUMENT_TEXT_DETECTION | Optical Character Recognition (OCR) on text within the image is performed. For sparse text within large image, we can use TEXT_DETECTION. Use DOCUMENT_TEXT_DETECTION, if the image is a document, has dense text, or contains handwriting. |
| WEB_DETECTION | Entities such as events, news or celebrities in the image are detected, and similar images on the web are found using the power of Google Image Search. |
Use Cases of Google Cloud Vision
Take a look at the several use cases of Google Cloud Vision that simplify work for organizations:

License Plate Detection – Some countries have parking lots that are led by the License Plate Recognition Model to punch in the entry and exit time of the vehicle. Detection of vehicles violating the traffic rules can also be adopted as a feature of License Plate Recognition.
Resume Parser – It is a tedious task for institutions or large companies to scan each resume and get useful information from it. So, OCR can be useful in this case along with some NLP (Natural Language Processing) as it reduces time and increases accuracy.
Contract Parser – Text within legal contracts can be hindered if written by humans. The solution for this is using Cloud Vision, as it extracts text and values from legal contracts such as agreement date, effective date, parties, expiration date, governing law, and notice to terminate renewal.
Receipt and Invoice Scanning – Financial balancing is one of the important activities for any organization. Large companies that purchase frequently need to gather and process all invoices and receipts. Automated pipelines can be made to recognize invoices.
Now that you are acquainted with the use cases, allow me to explain how Vision API actually works.
How Vision API Works
1. Set up the client library for Cloud Vision API.
2. Installing and importing the libraries

3. Importing Google Cloud credentials
You need to place your own JSON file that you generated earlier using your Google Cloud account.
The source path needs to be your file path i.e., the location of the image path.
![]()
4. Importing an image and passing it to the Crop Hints function
![]()
5. Crop Hints function
Crop Hints uses the Vision API Crop Hints feature. You can provide the image to be processed either through a Cloud Storage URI or embedded within the Crop Hints request. A successful Crop Hints response returns the coordinates for a bounding box cropped around the dominant object in the image.
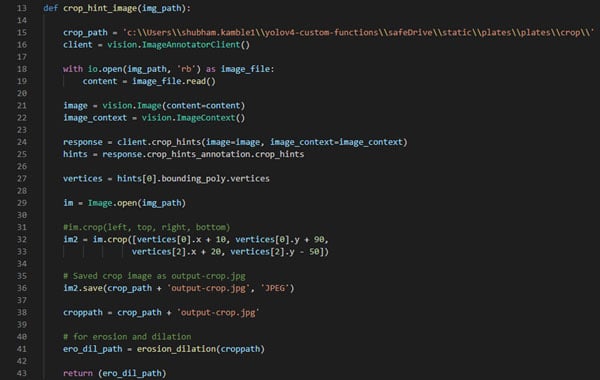
Firstly, create a client instance by using the ImageAnnotatorClient class for accessing the Vision API. The client library encapsulates the details for requests and responses to the API.
After image reading, we call the crop_hints method of the ImageAnnotatorClient instance to bounds for the first crop hint. We can crop the image as we want, only because we have the vertices from the first crop hint (I’ve cropped the image where the number normally occurs). Save that cropped image (number plate image) in a separate directory. This is the last step. Then the saved cropped image is passed on for erosion and dilation.
6. Erosion and Dilation
The cropped image is again pre-processed by erosion and dilation to remove the noise around the number plate image.
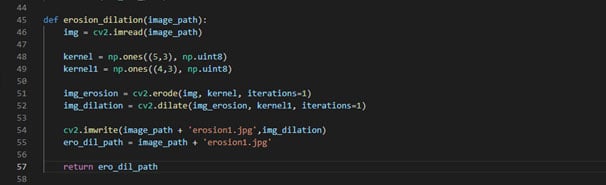
The iteration and kernel can be adjusted to remove the noise. Apply dilation after erosion. Save the processed image and return its path to crop hint function and in return, the crop hint will return that eroded image path to our primary function i.e., you’re returning the cropped eroded image to recognize_plate function.
7. Using Image Annotation and getting the actual content
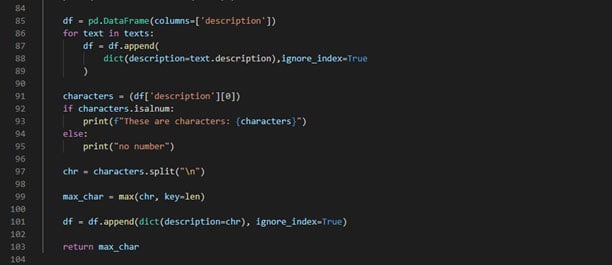
Create a client instance by using the ImageAnnotatorClient class for accessing the Vision API. It checks if you have permissions from cloud to use the API. Then we open the cropped eroded image for recognizing the content using Object Localization and Text Detection (Text Detection for OCR and Object Localization for detecting multiple plates) and then saving the annotated responses.

These responses are appended to a data frame for taking its first response that consists of the license plate number and then splitting it for getting the license plate number.
8. Output

The above output is achieved by passing the number from recognize_license_plate() to a flask API and display it on a webpage.
This is one way of having a number of license plates. More image pre-processing might lead to more accurate results.
As my blog has taken you through every aspect of Cloud Vision, I can vouch for the fact that Cloud Vision is the best when running as an OCR. Its Object Detection labels are more relevant, and Object Localization can be filtered using inbuilt labels. What’s more, it comes with more flexible API conventions. I must tell you that I am incredibly delighted with the utilization and flexibility of the Cloud Vision API!
Do reach out to us at Nitor Infotech if you’d like to share your experiences using Cloud Vision.




