
Highlights
Choosing the right LLM strategy depends on your data, accuracy needs, and operational constraints—not hype. This blog compares Build, Fine-Tune, and RAG, explaining when each approach works in practice. It shows why building from scratch is rarely justified, how fine-tuning delivers consistent style and domain reasoning, and why RAG is often the fastest, most practical choice for current, auditable, and secure knowledge. With real metrics, cost and latency trade-offs, and guidance on hybrid models, the blog helps teams select an LLM strategy that delivers reliable business outcomes.
Let’s be honest: deciding how to deploy an LLM in your organization isn’t exactly a walk in the park. You can build a model from scratch, fine-tune an existing one, or implement Retrieval-Augmented Generation (RAG). Each path promises different rewards and presents unique challenges.
So which strategy actually wins?
The truth is: there is no universal winner. The right choice depends on your accuracy needs, data freshness, latency SLAs, security constraints, and budget.
This blog breaks down Build vs Fine-Tune vs RAG not just conceptually, but operationally-with concrete metrics, benchmarks, and engineering guidance you can actually use.
The Three Paths to LLM Success
Path 1: Building From Scratch (Spoiler: You Probably Shouldn’t)
Building an LLM from the ground up sounds impressive at cocktail parties, but let’s talk reality. Training a foundation model requires computational resources that would make most CFOs weep. We’re talking millions of dollars in GPU costs, specialized expertise, and months of development time.
Unless you’re a hyperscaler or have truly unique, proprietary language patterns, this route is almost always overkill. Modern pre-trained models- such as GPT-style models, Claude-class models, or open-source alternatives- already understand language remarkably well.
When building makes sense:
- You operate in a completely unique domain with proprietary language
- You have massive compute resources and deep ML research talent
- Your data sensitivity rules out third-party or hosted models entirely
- You need full control over model architecture and training
For most organizations, the real decision comes down to the next two strategies.
Path 2: Fine-Tuning – Teaching Old Models New Tricks
Fine-tuning is like sending your LLM to specialized graduate school. You take a pre-trained model and continue its training on a carefully curated, domain-specific dataset so it learns your terminology, reasoning patterns, and output formats.
Modern approaches such as Low-Rank Adaptation (LoRA) make fine-tuning more accessible by updating only a small subset of parameters rather than retraining the entire model. This dramatically reduces cost while still delivering strong performance gains.
Why Teams Choose Fine-Tuning:
- Domain mastery: Medical, legal, or financial terminology becomes second nature
- Style consistency: Outputs align closely with brand voice and tone
- Format reliability: Structured outputs (JSON, contracts, reports) follow rules consistently
- Efficiency: Smaller fine-tuned models can outperform larger generic models for specific tasks
The Trade-Offs of Fine-Tuning
Fine-tuning is powerful-but it’s not magic:
- Requires thousands of high-quality labeled examples
- Risk of overfitting and loss of general capabilities
- Knowledge becomes frozen in time until retraining
- Maintenance overhead increases as regulations, policies, or products evolve
Here’s a real-world example:
Imagine a legal firm fine-tuning an LLM on thousands of contract templates and case documents. The resulting model doesn’t just know legal terminology; it generates contracts with proper clause structure, appropriate citations, and the exact formal tone expected in legal documents. Ask it to draft a non-disclosure agreement, and it produces something that looks like it came from a senior associate’s desk.
Path 3: RAG – The Dynamic Knowledge Approach
RAG represents a fundamentally different philosophy. Instead of embedding knowledge into model weights, RAG systems connect LLMs to external data sources-company documents, databases, manuals, or research papers-that can be searched at query time.
When a user asks a question, the system retrieves the most relevant information and feeds it to the model as context. The response is grounded in real data rather than memory alone.
Think of it as open-book vs closed-book intelligence.
Why RAG Is So Powerful
- Always current: Update documents and the system immediately reflects changes
- Source transparency: Clear audit trails and explainability
- Reduced hallucinations: Answers are anchored in retrieved evidence
- Cost-effective scaling: Add knowledge without retraining models
- Enhanced security: Sensitive data stays in controlled databases, not model weights
Why RAG Is Harder Than It Looks
- RAG is not trivial to implement. You need:
- Reliable data ingestion pipelines
- High-quality embeddings
- Fast, accurate retrieval infrastructure
- Continuous monitoring of retrieval quality and freshness
- Poorly organized documents or weak retrieval logic will result in disappointing answers—regardless of how strong your LLM is.
Customer support example:
A SaaS company deploys a RAG-powered chatbot connected to product documentation and FAQs. When reset-password instructions change, the bot provides the updated answer immediately—without any retraining—avoiding a constant fine-tuning maintenance cycle.
Making RAG Work in Practice: Retrieval Engineering Essentials
1. Chunking Strategy (Critical)
- Chunk size: 300–800 tokens
- Overlap: 10–20% to preserve continuity
- Avoid overly large chunks—they dilute relevance and waste context window space
2. Embeddings & Similarity
- Start with strong general-purpose embedding models
- Use cosine similarity as a reliable baseline
- Re-rank top-k results with cross-encoders or LLMs when precision matters
3. Vector Database Considerations
- Approximate Nearest Neighbor (ANN): High speed, scalable, minor recall trade-offs
- Exact search: Higher accuracy, limited scalability
4. Common Pitfalls & Quick Fixes
| Common Issue | Practical Fix |
|---|---|
| Semantic-only search | Hybrid search (BM25 + vector search) |
| No metadata filtering | Filter by document type, date, or department |
| Outdated content | Automated ingestion and freshness checks |
Embedding Versioning & Vector Store Operations
Embedding models evolve. When you change the embedding model, all vectors must be regenerated.
1. Operational best practices:
- Explicitly version embeddings (e.g., emb_v3_2025_01)
- Reindex in parallel before switching production traffic
- Always retain raw documents for re-embedding
2. Vector store deployment options:
- Self-hosted: Greater control, data residency, lower long-term cost
- Managed services: Faster setup, built-in scaling, higher ongoing cost
Evaluating LLM Strategies With Concrete Metrics
1. Core Metrics (All Strategies)
- Task accuracy / F1 on domain-specific test sets
- Latency: P50 and P95 response times
- Cost per query or cost per 1M tokens
- Failure rate: Timeouts, empty or invalid responses
2. RAG-Specific Metrics
- Recall@k: Was the correct document retrieved?
- MRR: How highly was it ranked?
- Grounded answer rate: Is the response supported by retrieved evidence?
3. Sample Target Benchmarks (Illustrative)
- FAQ or policy retrieval: Recall@10 ≥ 0.80
- Grounded responses: ≥ 90%
- Interactive apps: P95 latency < 2 seconds
- High-volume support: <$0.05 per query
Hallucination Detection, Attribution & Trust Signals
Reducing hallucinations requires more than better prompts.
Practical safeguards:
- Display source documents or snippets used
- Provide confidence scores for answers
- Post-hoc verification against retrieved content
- Surface citations and links to users
These practices are essential in healthcare, legal, and financial systems.
Cost & Latency Trade-Offs: A Practical Comparison
1. Fine-Tuned Small Model (Edge or On-Prem):
- Latency: ~50–150 ms
- Higher upfront training cost
- Lower per-query cost at scale
- Requires ML ops and retraining pipelines
2. RAG + Hosted Large Model + Vector DB:
- Latency: ~800–2000 ms
- Pay-per-use pricing
- Faster initial deployment
- Higher retrieval and infra complexity
The trade-off is often speed vs freshness.

Get the scoop on building a robust analytics solution for the healthcare industry, in a cheatsheet curated by our domain experts.
The Hybrid Approach: Having Your Cake and Eating It Too
How the hybrid model works:
Fine-tune a model on your domain to teach it specialized reasoning and style, then add RAG capabilities so it can access current information. The result? A model that thinks like a domain expert and knows the latest facts.
Example scenario:
A financial advisory platform might fine-tune a model on historical financial analysis and investment strategies to teach it proper financial reasoning. Simultaneously, it uses RAG to pull current market data, recent earnings reports, and breaking financial news. When a client asks about portfolio rebalancing, the model applies sophisticated financial logic (from fine-tuning) to current market conditions (from RAG).
The trade-offs:
The hybrid approach inherits complexity from both methods. You need ML expertise for fine-tuning AND data engineering skills for RAG infrastructure. The computational and maintenance costs multiply too.
However, for high-stakes applications where both expertise and currency matter think healthcare diagnostics, legal analysis, or financial services the hybrid approach can deliver results neither method achieves alone.
Here’s how to choose the right strategy for your GenAI initiative:
RAG vs Fine-Tuning: A Practical Decision Framework
Ask these questions:
How often does your knowledge change?
- Daily/Weekly → RAG
- Monthly/Rarely → Fine-tuning possible
- Stable reasoning + fresh facts → Hybrid
What resources do you have?
- Strong data engineers → RAG
- ML expertise and compute → Fine-tuning
- Both → Hybrid
What matters more—style or facts?
- Perfect formatting and tone → Fine-tuning
- Accurate, current information → RAG
- Both → Hybrid
Deployment environment?
- Cloud-connected → RAG
- Offline or edge → Fine-tuning
- Mixed → Hybrid
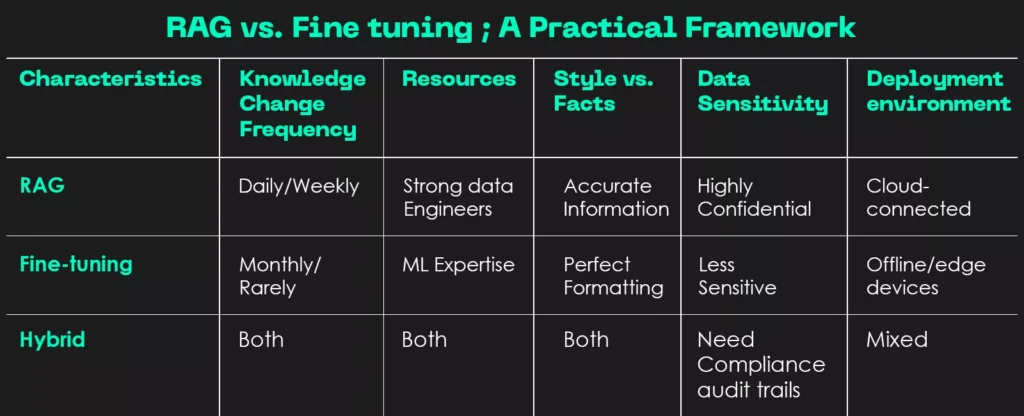
Fig: RAG vs. Fine-tuning: A Practical Framework
Recommended Evaluation Methodology
- Create a golden dataset (100–500 representative queries)
- Evaluate retrieval quality independently
- Compare generation with and without retrieved context
- Run controlled A/B tests in production
- Monitor accuracy, latency, cost, and drift continuously
Evaluation is a continuous loop—not a one-time step.
Security, Privacy & Compliance Considerations
- RAG: Easier audits, access control, and data deletion
- Fine-tuning: Data embedded in weights—harder to audit or remove
- Encrypt embeddings at rest
- Enforce role-based retrieval filters
- Log all interactions for compliance and review
For regulated industries, RAG or hybrid architectures are usually safer.
Context Window Limits & Prompt Engineering Reality
Even the largest context windows are finite.
1. For RAG:
- Answer-focused retrieval
- Context summarization before generation
- Dynamic prompt templates
2. For Fine-Tuning:
- Internalized knowledge does not bypass token limits
- Long structured outputs still require careful prompting
Context management often matters more than model size.
The Hybrid Approach: Having Your Cake and Eating It Too
Hybrid systems combine the strengths of both approaches.
Fine-tune a model for domain reasoning and style, then layer RAG on top for current information.
Example:
A financial advisory platform fine-tunes a model on historical investment reasoning while using RAG to pull real-time market data and earnings reports—combining expertise with freshness.
The trade-off is increased complexity, but the payoff is reliability in high-stakes domains.
Real-World LLM Strategy Success Stories
- Healthcare diagnostics (Hybrid):
A healthcare organization fine-tunes a model on clinical reasoning patterns and uses RAG to access the latest treatment guidelines and research—reasoning like an experienced clinician while staying current. - Customer support (RAG-first):
A SaaS company deploys a RAG chatbot connected to documentation and FAQs, avoiding constant retraining as products evolve. - Legal drafting (Fine-tuning):
A law firm fine-tunes a model for contract generation, achieving consistent structure and tone with infrequent retraining needs.
The Data Quality Imperative
Regardless of strategy, garbage in means garbage out.
- RAG systems depend on clean, current, well-structured documents
- Fine-tuning requires unbiased, representative, and accurately labeled training data
Monitoring data quality, drift, and performance is critical for long-term success.
The Future of LLM Strategies
- Smarter hybrid architectures that route queries dynamically
- More efficient fine-tuning techniques with lower data requirements
- Advanced RAG patterns: multi-hop reasoning and agentic retrieval
- Stronger base models reducing the need for heavy customization

Fig: LLM Deployment Strategies: Future Trends
Final Verdict: Which Strategy Wins?
- Choose RAG for dynamic knowledge and faster deployment
- Choose Fine-Tuning for consistent style, format, and offline use
- Choose Hybrid when both expertise and freshness matter
- Build from scratch only with exceptional resources
The goal isn’t to deploy the most impressive AI-it’s to deliver reliable, compliant, and valuable outcomes.
Ready to Build?
Get in touch with Nitor Infotech to architect the right LLM strategy-RAG, Fine-Tuning, or Hybrid for your business and turn GenAI potential into production reality.



