Many times, while dealing with enterprise systems and modernizing them, there are decisions to be taken on data sources with the objective of making data normalized or making data available real time or storing at different locations, etc. While there can be many activities, in this blog, we will specifically delve into one of the strategies to make data available in real time in SQL Server. The strategy is transactional replication. Transactional replication has a guide on the Microsoft website but doing it real time according to specific needs can entail a lot of challenges. I have presented two such use cases below. Let’s start with a brief understanding of replication and its requirements.
Replication
Replication is a process by which we can have an exact copy of our source database into our target database. If we perform DDL and DML commands on source database, then the changes will automatically reflect on the target database. The changes could be of any form – data, schema, store procedure, views.
In SQL Server, we have 6 types of replications for distributing data from source to target.
- Transactional Replication
- Merge Replication
- Snapshot Replication
- Peer-To-Peer
- Bidirectional
- Updatable Subscription
For our use case, we considered transactional replication as the best option for us.
There are two different setups in which transactional replication can be configured based on the use case. Following are the setups:
- Out of box Replication Setup
- Replication with Service Broker
Out of Box Replication Setup
This is mostly used in case we want to analyze live data or get the live data without affecting the write performance of the primary server. Replica of the server is a setup where all the read operations are done, and all the write operations go to the primary server.
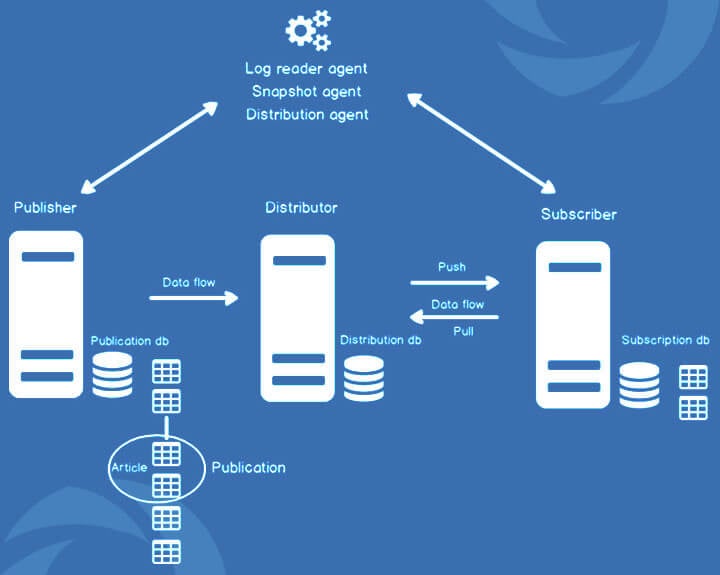
There are certain requirements that need to be set up before the replication is planned to be configured. Those are as follows:
- Publication tables should have primary key columns.
- User should have db_owner permissions for source and destination DB.
Other requirements have been explained very well on Microsoft articles for transactional replication.
Replication With Service Broker
We faced a unique challenge while setting up replication in an ERP environment. The requirement was to convert real-time and calculated data into reports. For this, we implemented a background window service which tracks the DML changes of tables and unique ID of records that are changed. After that we performed calculation on unique ID and put data into respective tables from where the application can access real time calculation of items.
But there was a challenge, we cannot implement any type of service broker on a production database. Therefore, we implement replication and perform operations on a target database.
We chose SQLTableDependency for tracking DML changes of tables using SQL service brokers.
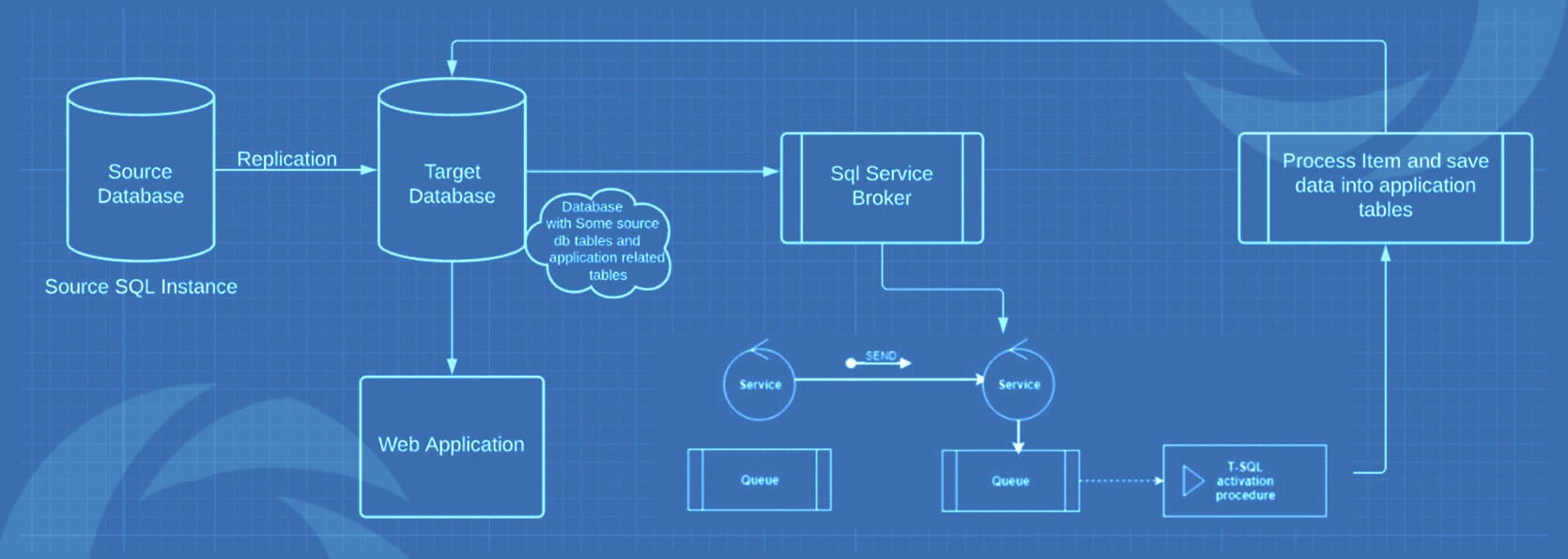
During our course of operations, we encountered a varied number of challenges. Out of all those challenges, I am outlining the 3 top ones that made us scratch our heads quite a lot:
Challenges and Solutions
1. ‘Object ID not Found’ error
Problem
While we were using SqlTableDependency or any SQL Service Broker Configuration on Replicated/Source database for tracking the changes, then we can face the error: “Object ID not found” if we are not dropping objects properly while stopping the service. We should also monitor duplication of service broker conversation and triggers.
Below are commands for conversation and triggers.
USE [<database where we configure SQLTableDependency>] select * from sys.conversation_endpoints select * from sys.triggers
Solution
Whenever we get this type of error in replication monitor, we should find a particular object by its ID and drop it immediately. (In my case there were duplicate triggers for on a table which was not dropping properly).
Below is a query to find a particular object of database by its ID.
SELECT name, object_id, type_desc FROM sys.objects WHERE name = OBJECT_NAME (<object id>);
2. Rapid Database size increase
Problem
While we were configuring replication with SqlTableDependency Or any SQL Service Broker, in some cases, we could see a rapid size increase of database Master file(.mdf).
The following query can help you to find objects of their size.
SELECT sch.[name],obj.create_date ,obj.[name], ISNULL(obj.[type_desc], N'TOTAL:') AS [type_desc], COUNT(*) AS [ReservedPages], (COUNT(*) * 8) AS [ReservedKB], (COUNT(*) * 8) / 1024.0 AS [ReservedMB], (COUNT(*) * 8) / 1024.0 / 1024.0 AS [ReservedGB] FROM sys.dm_db_database_page_allocations(DB_ID(), NULL, NULL, NULL, DEFAULT) pa INNER JOIN sys.all_objects obj ON obj.[object_id] = pa.[object_id] INNER JOIN sys.schemas sch ON sch.[schema_id] = obj.[schema_id] GROUP BY GROUPING SETS ((sch.[name], obj.create_date,obj.[name], obj.[type_desc]), ()) ORDER BY [ReservedPages] DESC;
Solution
If we have multiple queuemessages_* tables with huge size, we can remove conversation; it can affect your process and will not pass previous messages to the service. So, we need to restart our service.
declare @conversation_handle uniqueidentifier select top 1 @conversation_handle = conversation_handle from sys.conversation_endpoints while @@rowcount = 1 begin end conversation @conversation_handle with cleanup select top 1 @conversation_handle = conversation_handle from sys.conversation_endpoints end
3. Source DB Schema Alteration Error
Problem
Replication does not restrict you from altering database objects. But it has certain conditions:
- ALTER TABLE does not permit you to ALTER primary key columns.
- SYS.REMANE cannot be used to alter schema because it is a system procedure which does not allow any schema changes if publication is enabled for an object.
Here is a query for finding whether publication is enabled or disabled for an object.
select is_published,* from sys.objects where name ='<object name>’
Solution
We can replace sys.rename with proper alter commands. But if we are not allowed to do that and these are not frequent operations, then we can have T-SQL scripts in SQL jobs for dropping and re-creating SQL replication in a few clicks.
Note: You can find a sample T-SQL script in the link below.
https://github.com/nitor-infotech-oss/sql-server-replication-scripts
Open-Source Replication Tools:
There are open-source replication tools available in the market which can be utilized to reap alternate benefits and with different objectives. Those are ReplicaDB, SymmetricDS, Tungsten Replicator, Talend, and RubyRep.
And there you have it! I hope my blog has helped you to understand the context of what lies ahead when you plan for replication, especially transactional ones.
Feel free to write to us with your feedback and visit us at Nitor Infotech to learn about our services. Click here to discover more about how our big data technology offerings can help to transform your business with fruitful insights.



