
In a data-driven landscape, harnessing big data isn’t a luxury but a necessity for informed decisions and a competitive edge. Delve into the world of managing Amazon EMR (Elastic MapReduce) with unparalleled ease and efficiency. Streamline your AWS EMR management, shifting from complexity to seamless automation.
What is AWS EMR?
Amazon EMR (Elastic MapReduce) is a cloud-based big data processing service provided by Amazon Web Services (AWS). It simplifies processing and analyzing large data volumes via popular open-source frameworks like Hadoop, Spark, and Hive.
For petabyte-scale data processing, interactive analytics, and machine learning using open-source frameworks like Apache Hadoop, Apache Spark, and Apache Hive, the market-leading cloud big data solution is Amazon EMR. We can process data from AWS databases and data stores like Amazon S3 and Amazon DynamoDB using the AWS EMR.
AWS EMR is the best choice in these situations if you want to run Hadoop, Spark, Hive, or other big data technologies on the cloud without downloading or manually configuring them.
Benefits of AWS EMR:
Amazon EMR offers compelling reasons for organizations dealing with big data processing and analysis:
- Scalability: EMR allows you to easily scale your clusters up or down based on your processing needs.
- Cost Efficiency: With EMR, use Amazon’s flexible pricing: choose on-demand or cost-effective spot instances, lowering infrastructure costs considerably.
- Ease of Use: EMR simplifies infrastructure management, streamlining big data cluster setup. Shift focus to data analysis, minimizing infrastructure concerns.
- Managed Frameworks: EMR takes care of managing and updating popular open-source frameworks like Apache Hadoop, Apache Spark, and others. This relieves you of the burden of manual maintenance and patching.
- Integration with AWS Services: EMR seamlessly integrates with various other AWS services, such as Amazon S3 for data storage, Amazon DynamoDB for NoSQL databases, and AWS Lambda for event-driven processing. This ecosystem makes it convenient to build end-to-end data pipelines.
How to Streamline AWS EMR Management with Automated Cluster Creation?
Managing EMR clusters can be a daunting task, involving intricate configurations, scalability considerations, and resource optimization. That’s why we introduce you to innovative approaches that will not only simplify your EMR management but also empower you to focus on deriving insights from your data rather than wrestling with infrastructure intricacies.
With our step-by-step insights, you’ll discover how to automate the creation of EMR clusters, eliminating the need for manual intervention and reducing the risk of human errors. Let’s dive in and revolutionize the way you manage AWS EMR clusters!
You can use AWS EMR by using manual as well as automated approach:
Manual Approach Using CLL:
- Upload your application and data to Amazon S3 – Create buckets and respective folders in S3 bucket then upload your application file and data to respective folders.

- Configure and launch your cluster. Using the AWS Management Console, the AWS CLI, SDKs, or APIs, specify the number of Amazon EC2 instances to provision in your cluster, the types of instances to use (standard, high memory, high CPU, high I/O, etc.), the applications to install (Apache Spark, Apache Hive, Apache HBase, Presto, etc.), and the location of your application and data.
Step 1: Go to AWS EMR console, click on create cluster option, below window will open.

Give the appropriate cluster name. Now while configuring the cluster there is one option named Launch Mode, it has two options Cluster and Step Execution.
If you select Launch Mode as-
1. Cluster: It means when your EMR cluster successfully executes your application, you need to manually terminate the cluster to ensure proper closure.
2. Step Execution: It means after the successful run of your application the cluster will get terminated automatically.
Step 2: Software configuration
Release – Release option contains a set of applications which can be installed on your cluster. Based on Release option, select your Hadoop, Hive, Spark versions. So, select the Release option as per your requirement. Now write Spark application; accordingly, I have selected Release type and Application.

Step 3: Hardware configuration.
- Instance Type – In Instance Type, there are multiple options like Compute Optimized, Storage Optimized, GPU Instances, General Purpose, and Memory Optimized. Based on your application type i.e., computation power required, storage required select Instance Type. Based on Instance Type selection AWS is going to charge you, for more information on charges see the Pricing section.
- Number of instances – If you select number of instances as 3, (1 master and 2 core nodes) will get configured. So, select it as you require for your application.
- Cluster Scaling – EMR will automatically increase and decrease the number of instances in core and task nodes based on workload. Set a minimum and maximum limit of the number of instances for the cluster nodes. Master nodes do not scale.
- Auto-termination – If you enable auto-termination option your cluster will get terminated after specific time that you had specified. It will only terminate cluster when it is idle.

Step 4: Security and access
- EC2 Key Pair – Create the key pair in EC2 Network & Security section. Select Private key file format as .pem as in our case we are going to launch the application through AWS Cloud Shell.
Now select the remaining options as Default.

Step 5: Cluster console overview
After the cluster configuration, the cluster console will look like this-

Wait for some time as your software and hardware for your cluster is getting configured.
Step 6: Rule Setup
You need to add one Inbound rule, to enable Master node through AWS Cloud Shell. Scroll down and select Security groups for Master.

Select security group id for master group and add the inbound rule for master node.


Step 7: .pem file
After adding Rule, open AWS Cloud Shell and copy .pem file which you had created in step 4.

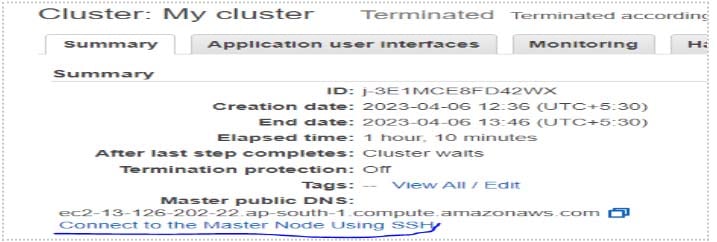
Step 8: Connect to Master Node
To establish a connection to the master node, type the following command shown in screenshot.

To get the above command click on – Connect to Master Node using SSH.

Step 9: Coding
Now your EMR cluster is configured, and you have established the connection with Master Node. Now you are going to write a simple application. Write simple PySpark code to read csv file from one of our S3 buckets and create Spark DataFrame from it. Then that dataframe will get saved in another S3 bucket.

Step 10: Run the application.
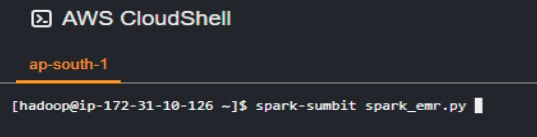
Step 11: After Successful run of your application, go to the S3 location where you had saved your dataframe. You will see multiple csv files spark is distributed computing.

Step 12:
Go to the EMR cluster console. You will see that the cluster you had created is terminated automatically because you had selected Launch Mode as Step Execution (step 1).

Automation Approach Using Python Script & Lambda:
With the help of lambda function, youcan create AWS EMR Cluster and the Cluster will be automatically created once a csv file gets uploaded in S3 bucket. The S3 bucket is going to be your trigger.
Step 1: Give the Function Name and in runtime Option, select the language in which you want to write your function.

Step 2: Once the Function is created, build a trigger. Select Trigger option as S3. In Bucket option select S3 path that serves as the event source.
Event types – Select the event type for which you want to have trigger the lambda function. In this case, you will select Event type as PUT. Once the file gets put in S3 Bucket it will trigger the lambda function.

Then select the IAM role which should have permission like, S3 Bucket Full Access, ĀmazonEMRFull Access. CloudWatch Full Access.

Step 3: After creating a trigger write your code for cluster creation. In the code you have to write cluster configurations like Instance type for Master & Core nodes, Number of Instances, applications which are required (Spark, Hive) and once the cluster is created, Master node is started. In the step execution option, you need to provide a python file which will read that csv file that you put in triggered bucket. The python code will create a PySpark DataFrame and after doing some transformations on that dataframe will save that dataframe in one of the S3 buckets.

Step 4: After writing the code go to the S3 bucket which you have selected in step 2 (s3/emr_input_transient). Put one csv file in it.

Step 5: As soon as you put a file in S3 trigger bucket, Lambda function will get triggered, and the configuration of AWS EMR Cluster will start. We have given cluster name as transient EMR.

Step 6: After your cluster starts, your application will start and be completed. You can see the status of application in the steps section.

Step 7: Once all the application gets completed, the cluster will get terminated automatically and you can see your output files in S3 bucket. Whenever you put a file in S3 triggered bucket the cluster will start and execute your application.
Automating the setup, initiation, and termination of AWS EMR clusters offers numerous benefits. With manual intervention eliminated, cluster provisioning becomes dependable and uniform. This approach enhances resource efficiency and cost reduction by initiating and halting clusters as required. The scalability and responsiveness of Lambda functions enable parallel processing, effectively managing diverse workloads. This automation enhances operational efficiency significantly. Employing Lambda for automating EMR cluster management results in more versatile, cost-effective, and productive workflows for processing substantial amounts of data.
Visit us at Nitor Infotech and share your thoughts with us!



