
SQL is the lingua franca in the data warehousing world. The developers do not write in SQL nor does SQL handle data programmability problems. Additionally, the data warehousing systems limit the kinds of operations that an individual can perform. This leads users to pull their data into other systems such as transformation tasks, adding cost, time, and complexity, while hurting security and governance.
Taking this scenario into consideration, one of the leading providers in ‘Data Warehouse as a Service’ Snowflake has added a new feature in its quiver – Snowpark. By using it, developers can work on or play with ‘dataframe-style’ programming with the languages of their choice!
So, in my blog today, let’s get on a ride in this ‘Snowpark’ filled with excitement!
Why do you need Snowpark?
Snowflake has indeed done a fantastic job in the data warehouse domain. But the question arises when it comes to the data processing part using programming APIs. The traditional way is to stage the data in system where you used to work on the data and again move it to warehouse environment. But this involved a lot of data overhead and a significant amount of cost too.
By leveraging Snowpark, you can build applications that process the data in Snowflake without moving data into the system where our code resides. The idea is to make the best use of Snowflake’s resources (Compute + Storage) and make it possible for the end user to write custom code to perform data processing and other complex operations.
The DataFrame is the core abstraction in Snowpark. It constitutes a set of data and provides different methods to operate on that data. You can construct a DataFrame object in your client code and set it up to retrieve the data that you want to use.
Take a look at the image below that shows the fundamental architecture of Snowpark:

Getting Started:
Currently Snowpark DataFrame programming APIs are available in Scala and are in public preview. Hoping more to come in future releases.
Requirements and Setup:
In this blog, let’s focus on a widely used notebook platform – Jupyter and an IDE setup of Visual Studio Code.
Scala Setup:
The Snowpark API is supported with Scala 2.12(specifically, version 2.12.9 and later 2.12.x versions). (Scala 2.13.x (a more recent version of Scala) is not supported.)
JVM for Scala:
For the JVM used with Scala, the Snowpark API supports Java versions 8.x, 9.x, 10.x, and 11.x.
Snowflake account users have sufficient privileges to work on various objects.
Jupyter notebook env. (Feel free to go with either conda installations or with pip packages).
To use Snowpark with Scala plug-ins, let’s set up an environment to start with.
A] Setting up a Jupyter Notebook for Snowpark using Scala:
Installing Almond Kernel:
Firstly, you need to install an Almond Kernel which is explicit Kernel for Scala development. Before installing it, you need to install dependencies through coursier that will be used to install Almond Kernel. You can find details about it in https://get-coursier.io/docs/cli-installation.
Once done with the dependency setup, go for Almond installation. (Reference: https://almond.sh/docs/quick-start-install). On Windows OS it looks like as below:
Once done with the above installation, initiate Jupyter notebook instance. Now you can see a Scala Kernel added to the Jupyter platform. Create a notebook with the name you like with Scala as interpreter.
Create a directory named ‘replClasses’ in any location you feel right. It is for storing the temporary files created by Scala REPL environment.
Open the notebook created recently and write the following code in a cell:

This is basically for configuring compiler for Scala REPL and generating classes for the REPL in the directory that you created earlier. This directory now serves as a dependency of the REPL interpreter.
In the next part, you will import Snowpark library from maven. Start a new session and configure the sessions parameters for your Snowflake account.

For this I have already created a table in Snowflake and populate it using AWS S3 as external stage. How to create the stage and tables in Snowflake is out of the scope of this blog. You can easily check it with official documentation.
I have named the table as ‘POWERPLANT_TBL’ in Snowflake DW. Now with using our newly created session I can easily query it out with simple syntax of ‘show tables’.

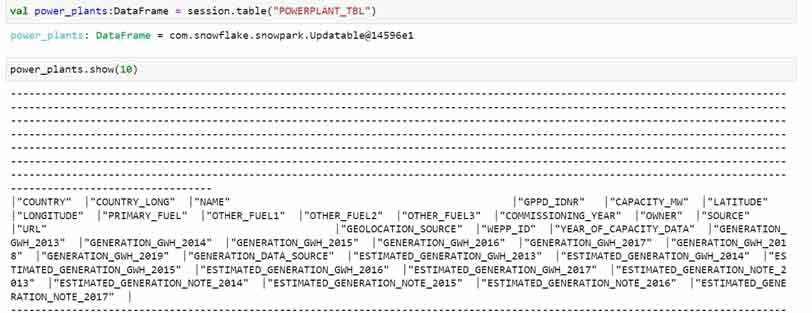
Also, you can create the DataFrame by creating ‘custom user schema’ while referring the external stage object in Snowflake.
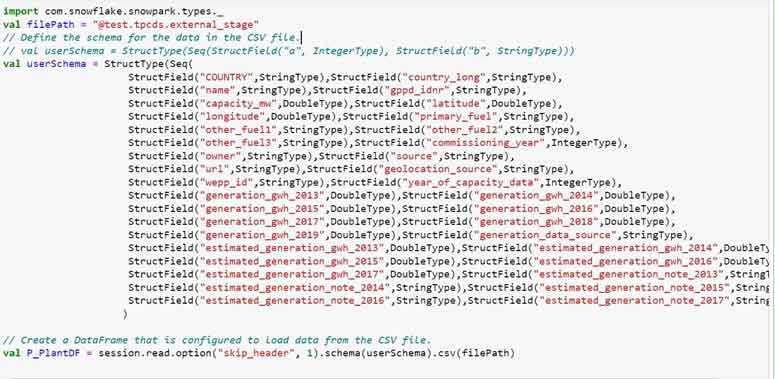
Let’s create a DataFrame using Snowpark Scala API and perform some basic operations on it.
In the given operation you are going to exclude DEU and Germany using filter functionality and validate the count prior and after the operation.
On a newly filtered DataFrame, you can perform basic aggregation like sum of MW Electric capacity group by country.
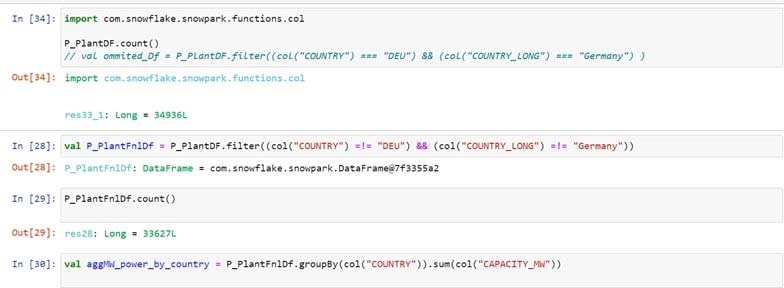

B] Setting up a Visual Studio Code for Snowpark Scala development
For this tutorial of VS Code, you need to download a Snowpark/Java bundle. Here, you are going to use a Snowpark-0.12.0-bundle (Here is the link: https://sfc-repo.snowflakecomputing.com/snowpark/java/).
Open the VS Code IDE, click on the ‘Extensions’ tab and in search bar type ‘metals’. The result will be shown as ‘Scala(Metals)’ as mentioned in the image given below.

Now, let’s create a directory for your Scala project to start. Choose a location of your choice.
Open it in VS code and click on the Metals icon shown.

Under ‘Packages’, select ‘New Scala Project’. It will ask for a template for new project select a scala/hello-world.g8. Select the workspace directory that you created earlier (in my case it is Snowpark) and click OK. Give a name to your new project.
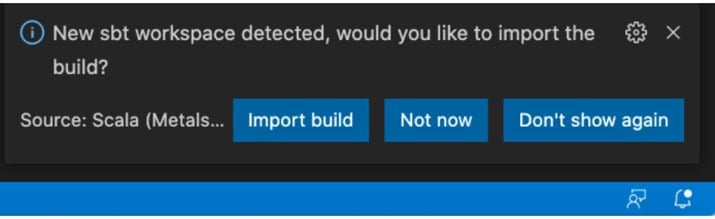
Once all this is done, you are prompted with a window asking to open a new window for your project. Just click ‘Yes’ and a new window will open. On this newly created window you will see one pop-up in the lower right corner for ‘Import build’. Click on ‘Import build’ to build your project dependencies.
After these initial setups, you are good to head to the next section of actually configuring your project to use for Snowpark development.
As you have untarred the Snowpark java jar earlier of this section, now just copy ‘lib’ from this Snowpark-0.12.0 directory into your project folder. At the same time also copy the ‘snowpark-0.12.0 jar’ to this lib path into the project.

Expand the directory of your project and select ‘build.sbt’ from the dropdown. It will open in a side bar.
For Snowpark to support, you need to make changes in this file this way:
Mention the scalaversion as a supported version for Snowpark library. Here, you will use ‘version 2.12.13’
Next, add the dependencies as ‘libraryDependencies’ in the form of shorthand concatenated string form.
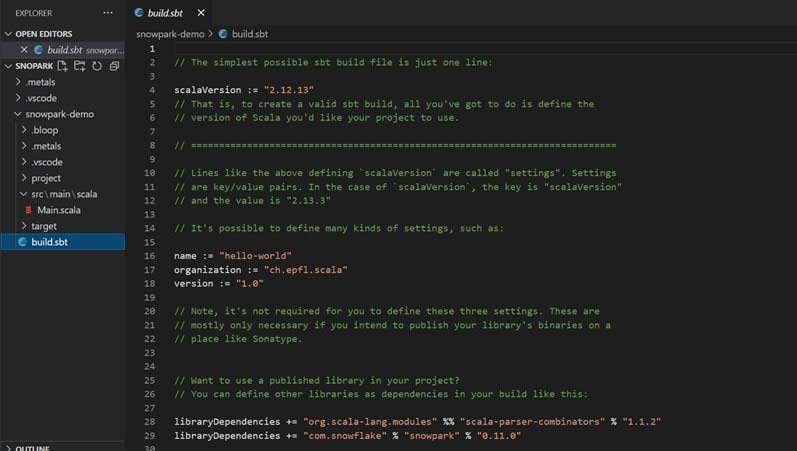
Also add a path to ‘lib’ in your project for other required dependencies.

Once you are done with the changes, save the file. When prompted by a dialog box, click on ‘Import Changes’ to import saved changes to a file.
On the expanded menu of your project directory, further expand the ‘src/main.scala’. You will notice a Main.scala file. Open it and enter the credentials for your Snowflake account. For this demo I have mentioned the user and password in ‘Main object’ in scala. You can use other secure ways to achieve this in actual practice.

Click ‘Run’ above the object and whoa! The tables will now be visible in your database.

I hope with the help of my blog you will now be able to get started with Snowpark and make the best use of Snowflake’s resources. If you are interested in learning more about how big data technology can enhance your business, do explore Nitor Infotech’s big data services. Reach out to us at Nitor Infotech if you would like to share any suggestions and queries related to the topic.



