If you’re wondering what makes some businesses scale faster and better, well the answer is obtaining accurate insights and maintaining data integrity. For those looking to play the long game, my recommendation is to switch to SQL warehouses for SQL-specific workloads. SQL warehouses offer a centralized, efficient, and reliable way to manage your data, ensuring consistency and performance.
Although Snowflake and Databricks stands tall amongst the rest of warehouses, this blog will help you choose the right SQL warehouse for your data-driven projects. I’ll delve into the functionalities, warehouse types, performance benchmarks, and cost structures of Snowflake and Databricks SQL warehouses, helping you make an informed decision in 2024.
So, let’s get started with the basics!
Difference between Snowflake and Databricks
With the basics covered, let’s explore some of the advanced aspects of Snowflake and Databricks.
Comparing Advanced Features: Snowflake vs. Databricks
Onwards to the variants of Databricks and Snowflake!
Types of Warehouses: Databricks vs. Snowflake
When it comes to Databricks warehouses, there are four variants of warehouses. They are:
- All-Purpose Compute: This is best suited for batch processing using SQL queries. It offers greater control over cluster configurations but comes at a higher cost than job compute.
- Job Compute: This is ideal for running specific jobs. It allows fine-grained control over cluster resources and automatically terminates after job completion, minimizing idle resource costs.
- Compute with Photon: This high-performance offering leverages the Photon vectorized query engine to accelerate SQL workloads and DF API calls, leading to faster execution and potentially lower overall costs.
- Interactive Clusters: This is optimized for interactive queries and reading data.
Each of the above variants provides varying levels of performance and scalability based on your requirements.
In contrast, Snowflake offers two types of warehouses:
- Standard warehouses: are suitable for general data warehousing tasks.
- Snowpark optimized warehouses: cater specifically to workloads leveraging Apache Spark software and Snowpark for enhanced performance.
Both provide compute resources (CPU, memory, temporary storage) and can be scaled up or down on demand to match your workload needs.
Did you know?
Snowflake and Databricks offer warehouses in various sizes. Here’s a breakdown:
Refer to the hourly costs of the enterprise edition for both platforms:
(I’ll talk about the cost structure in detail in the latter half of the blog. Keep reading!)

Learn how our data warehouse and dashboards helped a leading retail chain transform its strategies by understanding customer behavior with easy visualizations.
Moving ahead, I’ll provide a performance comparison of both platforms based on a recent assessment.
Performance Benchmarking: Unveiling the Powerhouse
To objectively assess performance, my team and I conducted a benchmarking exercise using the TPC-H dataset, a widely recognized decision support benchmark. This dataset includes a suite of business-oriented ad-hoc queries with varying complexity levels.
We utilized a 100GB dataset size for the comparison. You can find more details about the TPC-H benchmark on the TPC website.
A. Here is an overview of the query complexities:
The chosen queries ranged from low to high complexity, encompassing tasks like:
- Pricing Summary Reports (Low)
- Identifying Minimum Cost Suppliers (Medium)
- Analysing Shipping Priorities (Medium)
- Order Priority Checks (Medium)
- Local Supplier Volume Analysis (High)
- Volume Shipping Queries (Medium)
- National Market Share Exploration (Low)
- Product Type Profit Measurement (High)
- Returned Item Reporting (High)
B. Performance optimization techniques:
We explored the following techniques for both:
| Snowflake | Databricks |
|---|---|
| i. Micro-Partitioning:Data is partitioned along small files ranging 50-500 mb.Metadata is maintained for each partition for faster data retrieval. | i. Delta Tables:Leverages delta lake and u ses Parquet format. Thus, enabling optimization techniques. |
ii. Data ClusteringIt manages clustering metadata for the micro-partitions within a table, including:
|
ii. Optimize, Z-order:
|
| iii. Auto-ClusteringSnowflake offers a service that automatically and continuously manages the reclustering of clustered tables as needed. It only performs reclustering when it will provide a benefit to the table. | iii. Partitioning: It stores similar data within the same set of files, facilitating faster data retrieval, and is used for low-cardinality fields. |
Note: Apart from the above techniques for Databricks, you can follow these Spark configurations too:
- ·Spark.executor.cores
- ·Spark.executor.instances
- ·Spark.executor.memory
- ·Spark.sql.adaptive.enabled
- ·Spark.sql.maxPartitionBytes – Default (128 mb)
- ·Sc.default.parallelism
C. Results and observations:
Before optimizations, Databricks execution times for TPC-H queries varied from 30 to 40 seconds, with some complex queries taking even longer.
After implementing the optimization techniques mentioned above, we observed a significant improvement in query execution times. The average execution time dropped to around 20 seconds, with a maximum reduction of 64% achieved for a specific query.
However, it’s important to note that Snowflake, even without extensive optimization, generally delivered faster execution times compared to unoptimized Databricks configurations. This could be attributed to Snowflake’s inherent architecture and query processing engine.
Test results: We compared warehouses ranging from “XS to 4XL” for both platforms. Refer to the images below for clarity:
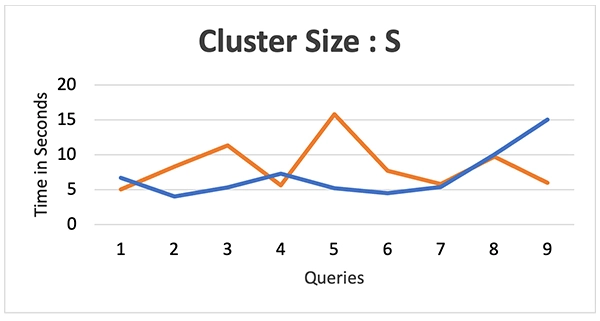
Cluster Size – S
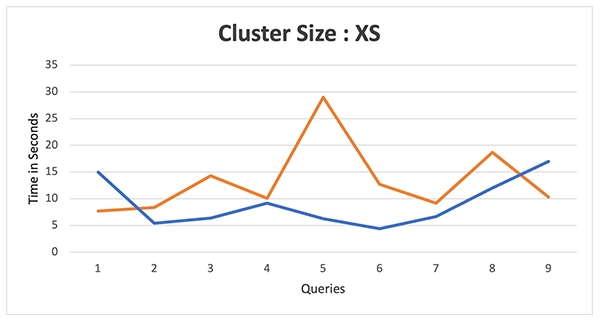
Cluster Size – XS
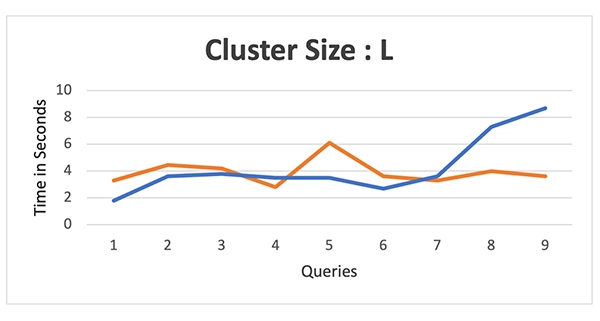
Cluster Size – L

Cluster Size – M

Cluster Size – XL
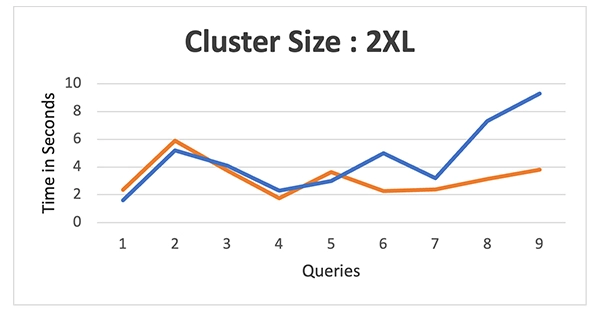
Cluster Size – 2XL

Cluster Size – 3XL
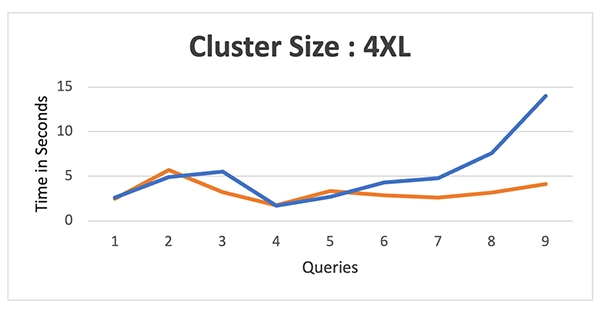
Cluster Size – 4XL
The data above shows that Databricks initially lagged behind Snowflake’s performance up to the medium warehouse size. However, as the warehouse size grew, Databricks started to perform better and eventually surpassed Snowflake in some cases.
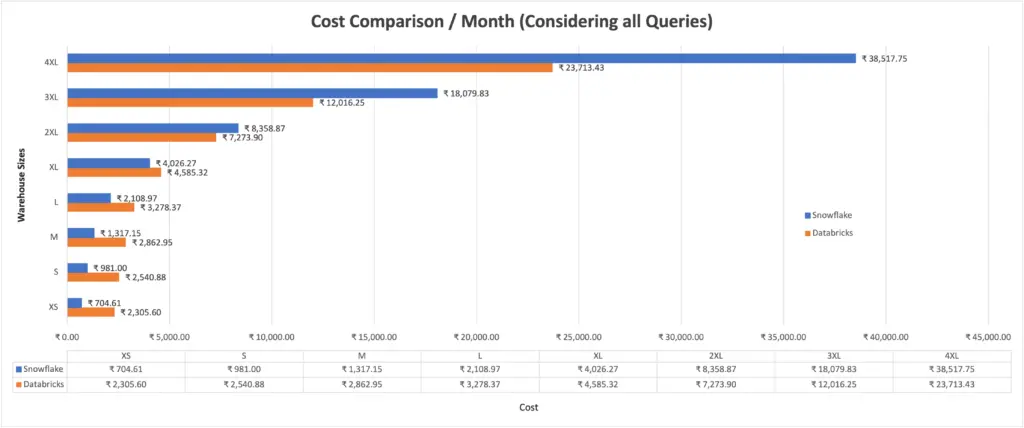
Fig: Snowflake vs. Databricks – Cost Comparison per month
Let’s now compare the cost structures across different editions and sizes of warehouses!
Cost Comparison: Finding the Right Balance
Evaluating cost is another crucial factor when choosing an SQL warehouse. Here’s a breakdown of the pricing structures for both platforms:
Databricks Pricing:
Due to the absence of publicly available pricing information for Databricks editions (Standard, Premium, Enterprise), a direct cost comparison with Snowflake is challenging. However, Databricks utilizes a tiered structure based on:
- Warehouse Size: Warehouses are sized based on Data Processing Units (DPUs), which represent compute resources. The cost varies depending on the chosen DPU tier (e.g., X-Small, Large, etc.). Pricing per DPU/hour can vary based on factors like cloud platform, instance type, and commitment terms. You can find more information on Databricks pricing on their website.
- Spot Instances: Databricks allows utilizing spot instances for cost optimization. These offer lower costs but come with the potential for resource interruption.
Snowflake Pricing:
Snowflake offers a clearer pricing structure based on:
- Edition: Standard, Enterprise, and Business Critical editions are available, each with varying features and support levels. The cost per credit/hour increases with higher editions.
- Warehouse Size: Like Databricks, Snowflake charges based on credit per hour for warehouse sizing, with costs scaling according to the size of the deployed virtual warehouse.
Choosing the Right SQL Warehouse
To be honest, the choice between Snowflake and Databricks SQL Warehouse hinges on your specific data processing and analytics needs.
a. Choose Databricks if:
- Spark-based analytics and Machine Learning are your core activities: Databricks’ heritage in machine learning development offers a mature environment for these tasks.
- You have a skilled team for optimization: Databricks requires more configuration for optimal performance, but skilled users can unlock its significant potential.
- Handling large and complex workloads is crucial: While our testing showed Snowflake’s advantage for smaller workloads, some resources suggest Databricks might excel with massive datasets.
b. Choose Snowflake if:
- Ease of management and pre-optimized performance are priorities: Snowflake’s simpler setup and out-of-the-box performance are ideal for business intelligence (BI) tools and basic analytics.
- Cost-effectiveness is a major concern: Snowflake’s predictable pricing structure can be advantageous, especially for workloads requiring minimal configuration.
This above analysis is based on a free-tier evaluation, and your results might differ based on workload specifics and data size. However, you can consider these factors and use the free trials to make a well-informed decision for your business.
So, start to leverage big data and boost your analytical capabilities with Nitor Infotech. We’d also love to hear your thoughts on this blog—feel free to reach out and share your feedback.



