That nagging question, that doesn’t allow you to rest till you put pen to paper – or in this case – keys to MS Word. I have been asked this very question multiple number of times, and I thought it was best to put it out there for all to know.
Let me start by saying that to the first word in your GraphQL vocabulary notebook should be API. Application Programming Interface (API) is a software interface that exposes backend data and application functionality to various client applications and hence APIs are treated more like product than code. Modern APIs adhere to standards like HTTP and REST. When it comes to API development, we are more likely to implement REST APIs which is proven or in practice a very viable option. However, what I have seen and many will concur, GraphQL seems to be changing this very notion.
What is GraphQL?
Ask and you shall receive (data)
GraphQL, a query language for API and runtime uses existing data to fulfill queries. It provides a specific type system that can help you define data, make queries, change or subscribe to data updates by using a very specific query format. GraphQL enables declarative data fetching i.e. the shape of the received data exactly as requested. So yes, if you know how to ask, then you shall receive data which is tailored to match your exact requirements
GraphQL provides an understandable description of data and flexibility to clients to ask for what they want, which makes it easier for GraphQL APIs to evolve overtime and make efficient use of the network bandwidth. GraphQL supports multiple transport protocols like, HTTP, MQTT, and WebSockets.
What is the difference between GraphQL and REST?
REST (Representational State Transfer) is a software architectural style that defines a set of constraints (viz. stateless, cache-ability, layered system, and uniform interface). These make a web service – a true RESTful API. REST is not an optimal solution for low powered devices and networks that are slow or unreliable. Developing a single REST API that could fit the requirement of each and every client poses to be a huge challenge. Also, modern applications and mobile apps are shaped in the form of graphs and hence GraphQL is a better option to interact with servers, and is replacing REST API.
Let’s analyze why GraphQL is better than REST.
Server driven selection
In REST ful APIs, a representation of a resource is created by the server, which in turn responds to a client. If the client wants something specific with connected entities then representation becomes impossible. E.g. we have GET api/tweets API which returns “tweet_id” and “tweet_content”. If a client wants to fetch author of the tweet then it can be achieved by –
i. Fetching the author from other APIs – This will require an additional server request, which is not ideal for scalable systems.
It will cause ‘under fetching’ also known as the ‘n+1 problem’. What this essentially means is that there is not much information that a specific endpoint can provide and the client will thus have to keep making additional requests till everything needed is fetched. This may snowball into something more cumbersome where the client may have to first download a list of elements and then make additional requests one per element to fetch the data they require.
ii. Modifying existing APIs to send author – In contrast with point 1, this will cause an ‘over fetching’ issue, as not all clients want that additional attribute.
Over fetching is if more information is downloaded than is actually required in the app. The same amount of information will be returned for each API request. This is not an entertaining proposition for most clients because some may require only to display a subset of attributes of an entity.
iii. Creating a new API which will return tweets along with author – It will affect the entire development timeline as a developer has to develop a custom API endpoint for each view of the frontend.
iv. Allowing the client to request only necessary data to fetch the author – A nested query is perhaps the cleanest possible way to go around this problem. And GraphQL does just that. GraphQL solves over-fetching and under-fetching issues, because the clients fetch what they need. This gives more freedom in the fetched data to the client and increase the pace of development.
Hence proved GraphQL helps in faster development than REST.
Analysis of APIs
GraphQL API complaint tools can provide better and more insights into queries than RESTful APIs. Tools like, Moesif API Analytics and aws-amplify will help analyze GraphQL APIs.
Let’s analyze the Pros and Cons of REST and GraphQL :
| REST | GRAPHQL | |
|---|---|---|
| Pros | Proven for decades High performance (specifically over HTTP2)Scale indefinitelyData format agnosticIndependent evolution due to full decoupling of client and server | Easy to start withEasy to produce and consumeContract-driven by nature of relation of data entitiesEasy to keep consistent and to governHas built-in introspection · Closer to SOAPEasy workflow (design, create, evaluate, and optimize queries)One API for all (including specific) client needs No reference documentation needed |
| Cons | Multiple APIs (or dedicated resources) for specific client needsThe big change in the paradigm shift from SOAP, challenging for enterprises to change the mindsetPoor or no tooling for clientsNo framework or tooling guidanceRequires discipline on server and client sides Challenging to keep consistency and governance | Server and clients coupled at the client programming time, application state is not driven by the serverNo support for content negotiation, network errors, caching JSON representation onlyNeglects the problems of the distributed systemToo few vendors in the ecosystem |
When to use GraphQL?
You use GraphQL when you want to:

GraphQL Ecosystem
The GraphQL ecosystem is expanding at lightning speed that is because many tools can be developed easily with GraphQL. So here is a list of clients, servers, services, details, schema, queries, and resolvers that make up the GraphQL ecosystem.
Clients
- Relay : A GraphQL client developed by Facebook, optimized for performance and available only on the web.
- Apollo Client : A community-driven, production ready, GraphQL client for all major development platforms. It supports frontend frameworks like React, Angular, and Vue as also iOS and Android platforms
Server
GraphQL.js : This is the reference implementation of a GraphQL specification, designed for running GraphQL in a Node.js environment.
GraphQL-tools : This is a package to build production-ready GraphQL.js schema directly using the GraphQL schema language, rather than the GraphQL.js type constructors. These tools allow added support for modularizing your schema, unions, interfaces, resolvers, custom scalars etc.
Apollo-server : This is a production-ready Node.js GraphQL server library that supports Express, Connect, Hapi, Koa, and other popular Node HTTP servers. It has built-in features like persisted queries, batching etc. Apollo Server is compatible with all GraphQL clients like Apollo or Relay to name a couple.
Services
- Apollo Optics: This is a service to visualize, monitor and scale your GraphQL operations.
- Graphcool: This is a GraphQL backend for your mobile and web applications with a powerful web UI for managing both your database and your stored data. Graphcool cuts down on both the time and infrastructure required to set up a server. It supports technologies like React, React Native, Vue, and Angular, platforms like iOS, Android, GraphQL clients like Apollo and Relay and integrates well with various third party services/APIs.
- GraphCMS: This is a GraphQL based headless content management system. You can use their tools to manage your content and build a hosted GraphQL backend for all your apps.
GraphQL details
Schema, queries, and resolvers, are what you can call the three building blocks of GraphQL.
Schema
To define API capabilities, GraphQL uses a very strong type system. The types exposed in the API are in a schema and use the GraphQL Schema Definition Language (SDL). The schema lets the client access the server by playing the role of a contract between the client and the server.
With the schema defined, the teams can get working without communicating with each other. This is because both the frontend and backend teams know the data structure sent over the network.
Even testing applications becomes easy for frontend teams, as all they have to do is mock the required data structure. When all the tasks are done and the server ready, the client apps can load the data from the actual API- a simple flip of the switch should do.
GraphQL’s has a typed schema system.
Each GraphQL service defines a set of types that describe the data you can query in that particular service. The schema validates and executes all queries that come in.
The types of schema include: input types, queries, and mutations which the GraphQL server will be able to interpret.
Queries
Queries are used to fetch certain values. Graph QL queries reduce over fetching in data. Here is a list of GraphQL queries and what they look like.
– Request for any item to the GraphQL server in the query
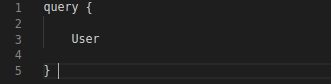
– Ask for specific field of items
Note: GraphQL queries support nested fields
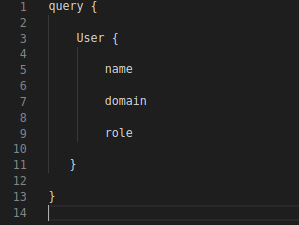
– View arrays using the query fields
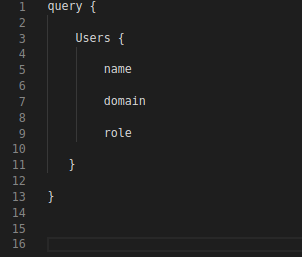
– Ask for a specific user by adding an id_argument to the user field, since query fields support arguments. This id
can be a dynamic parameter:

Resolvers
In GraphQL, the API schema and database schemas are decoupled. The resolver is used to process an incoming query on the GraphQL server. It indicates the method and the source to fetch data corresponding to a given field. Even subfields can have resolvers. For example, the user field resolver looks like this:

When you update the contents of the database, they transform the resolver into mutation resolvers.
Best practices
Input object type for mutations
Create or Update are considered to be mutations in the GraphQL domain. Input types (see Schema) act as a query parameter or a payload to create and update an object. To simplify the structure of a GraphQL document, you can use an input object type, this makes updating mutations in the future easier.
Note: A non-null modifier should be applied to an input object to ensure that the input payload is not null.
Schema design with interfaces
Interfaces and unions are two must have tools, if you aim to standardize the schema and reduce the complexity. Their purpose is abstraction of complex concepts and implementations.
Interfaces come into the picture, when access to a certain group of objects is needed to make them compliant. The group types are abstracted which helps reason with one single entity instead of a host of them.
Let’s take an example of entities we use most often.
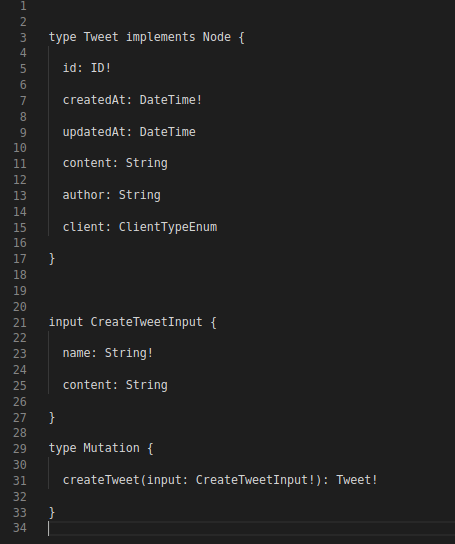
Entities like User, Tweet, Comment, become a “type”.
Here id, createdAt and updatedAt are repeated in each entity.
To make the implementation of these attributes unique and standard we must use interface.
The Schema can be modified as under :

Complex queries are simplified using interfaces. So, you can fetch or query items specifically.

These multiple queries can be replaced by a single query using the item function.
Any type that implements the Node interface can be queried. In most schemas, the Item interface must necessarily be implemented in every object type having an id, as id is a global identifier.
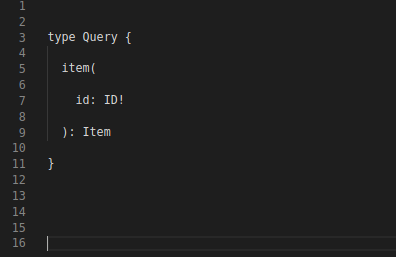
A client can get any item by calling same query.
For example, to get tweet, it can call for:
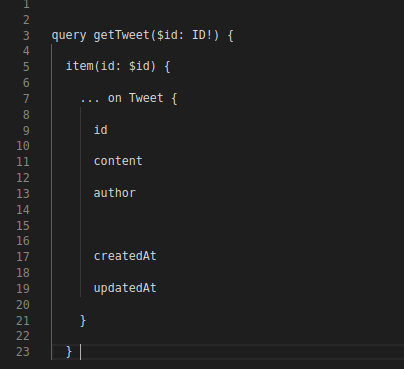
To get a user, you could ask for:

Returning affected objects as a result of mutations
A design is considered good if it can return mutated records as a result of the mutation. It then becomes possible to update the frontend and be consistent.
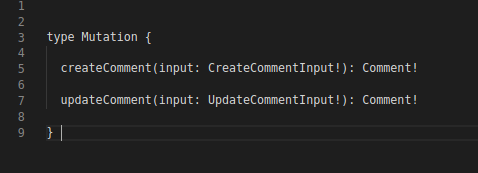
Create, update, and comment mutations return Comment! as a result. These can be used by the cache and in turn update the store. Speaking in code, after calling createComment mutation, the object will be appended to the list of tweets and after calling for updateComment, the code will update UI to show updated comment.
Nesting objects in queries
To design types in GraphQL, standard patterns need to be followed, since doing what is labelled as anti-pattern will affect the caching process as also the efficiency of GraphQL queries on slow networks.
If we design type Tweet as below, it will have the author as ID field. When the tweet as well as the author information is required, the client will send an additional query to get the author.
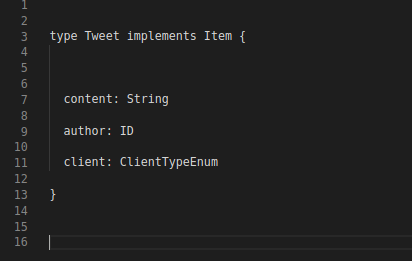
These types can be reused and ID can be substituted with type. It is preferable to nest the output type in GraphQL, since one can call everything in a single query helping to cache and in batch data loading.

Versioning
In REST, the client has limited control over the data returned from the API. Hence updates to the API can cause errors on the client side. Versioning APIs can help avoid these problems. While the client continues to work with the older version, the developers will have to manage the tradeoff and choose between releasing incremental versions as opposed to maintaining the API.
Asking for the required data becomes easier for clients with GraphQL. New capabilities can be added by creating new types or fields that will not affect existing clients. This means updates do not need to be broken and serverless API becomes a norm.
Null type mapping
In the GraphQL type system, every field can be made into a null by default.
A database could fail, an exception could be thrown, and the authorization could be granular, where individual fields within a request can have different authorization rules.
So in the likelihood of the above scenarios, with null as default in every field the field returned is “null”, rather than a complete request fail.
GraphQL goes a step further and provides non-null variants of types, where if a request fails, the null is never returned but instead the parent field turns null.
For GraphQL schema designs, it is necessary to list out all the areas that could fail and to check if null is an appropriate value if they fail. Using the non-null variant in such cases is a better option.
Schema design – consistent naming convention
To declare variables or functions in code and define GraphQL schema design, naming conventions play an important part. It is a good practice to use camelCase for fields and PascalCase for names of types. And use all capital letters for ENUM values since they are constants.
Input types can be defined as:
(action) (type) Input
a. (action) Create, Update or Delete
b. (type) the name of the type or entity being updated.
Ensure that some common patterns like pagination are named in the same way.
Paginated lists
GraphQL queries return list of entities or values, some of these may have many results which will need to be paginated so the application can perform better. It is necessary that resources be protected against exhaustion attacks, where someone queries an overwhelming number of records from your database at once.
The other reason why pagination is paramount, is due to security concerns and possessing the ability to limit the records retrieved from the server. The API designer must take full responsibility in implementing paginated results.
Pagination can be designed in APIs in a variety of ways, each with equally appealing pros and off-putting cons.
As a rule, fields that have the possibility of returning long lists, accept arguments like “limit” and “next” to narrow down the search. The best practice convention of Connections, came about while designing APIs that had feature-rich pagination. Client tools for GraphQL like Relay provide automatic support for client-side pagination when a GraphQL API employs this pattern. AWS app sync also supports connection pattern.
Batching & Caching
GraphQL enables developers to write clean code on the server, where every function is focused on a single purpose – resolving fields in type. However, without additional design considerations, service may repeatedly load data from databases.
This can be solved by a batching technique, where multiple requests for data from the backend are collected over a short period of time and then dispatched into a single request to an underlying database or a microservice by using data loader tools.
Data loader caches the results forever, unless told.
Note: Create a new instance for every request sent to the server, to de-duplicate fetches in one query but not across multiple requests or multiple users.
Enable GZIP – Accept-Encoding: gzip
API developers are very familiar with JSON, and it is easy to read and debug.
The GraphQL syntax is partly inspired by the JSON syntax. But as a best practice, any production with GraphQL services must enable GZIP and the clients must send the header: Accept-Encoding: gzip
GraphQL services respond through JSON, but a GraphQL spec does not require it. For an API layer promising better network performance JSON may not be the first choice, but because it is mostly text, it compresses well with GZIP.
Future schema updates
Future upgrades must also be taken into consideration while implementing the initial schema.
As a best practice, it is recommended to add output object types and input object types wherever required so as to accommodate future requirements.
This means one can avoid breaking changes later. While prototyping and for instant high-performance APIs, GraphQL schema generators prove to be useful aides.
Caution: Do not use GraphQL schema generators generously when designing complex application schema.
In conclusion I think that, as an exciting new technology, GraphQL is a very powerful tool and will perhaps prove extremely handy in your upcoming project.
It is an important architectural decision to take, so make sure you assess if your API is best suited for GraphQL. If you have fewer entities and relationships across the entities, then maybe not. But if there are scores and scores of entities you have to deal with in your application- users, items, payments, orders, and so on and so forth, then look no further than GraphQL.
The right choice may not always be the best choice, but if you ask the right questions, the answers may lie with GraphQL, because the core belief of Graph QL is ‘ask and it shall answer’. Write to us if you would like to know more about our services, or know how we can help you implement modern APIs the GraphQL way.



