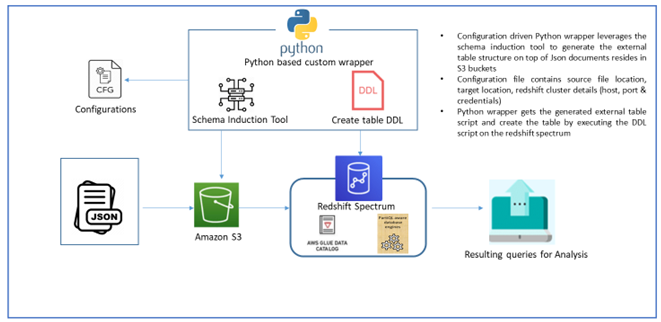
In this blog, we will focus on understanding the process of using AWS Redshift PartiQL and how it can be used to analyze data in its native format. But before we move on to that, let us first define the problem statement. Data is typically spread across a combination of relational databases, non-relational data stores, and data lakes. Some data may be highly structured and stored in SQL databases or data warehouses, other data may be stored in NoSQL engines, including key-value stores, graph databases, ledger databases, or time-series databases. Data may also reside in the data lake, stored in formats that may lack schema, or may involve nesting or multiple values (e.g., Parquet, JSON). Every different type and flavor of data store may suit a particular use case, but each also comes with its own query language. The result is tight coupling between the query language and the format in which data is stored. Hence, if we want to change your data to another format or change the database engine we use to access/process that data (which is not uncommon in a data lake world), or change the location of the data, we may also need to change the application and queries. This is a very large obstacle to the agility and flexibility needed to effectively use data lakes. In this demo we will walk through the process of using Amazon Redshift PartiQL and the role it plays in simplifying the analysis of data in its native JSON format. We focus on an approach that can help data analysts reduce the manual work and long cycles of nested json data processing by querying and running analysis that is required day to day. AWS announced PartiQL, an open-source SQL-compatible query language, that makes it easy to efficiently query data, regardless of where or in what format it is stored. The majority of existing analytics infrastructure relies on the “flat” storage and presentation of data assets; this can be challenging given the schema-less JSON structure. Now, let’s take a look at our solution approach for analyzing heavily nested json documents. These documents could be from any of the industry domains. The diagram illustrates high level flow and components of the solution approach. This approach demonstrates how to use schema induction tool, an open-source library with conjunction of Amazon Redshift PartiQL queries and Amazon Redshift Spectrum, which enables us to directly query and join data across the data warehouse and data lake. It allows us to design a semi-relational schema, where data analysts can quickly combine relational and non-relational data from multiple resource tables. We use PartiQL in Amazon Redshift Spectrum to query over data stored in Amazon Simple Storage Service (Amazon S3).
- Amazon Redshift Spectrum runs complex SQL queries directly over Amazon S3 storage without loading or other data preparation, and AWS Glue serves as the meta-store catalog for the Amazon S3 data.
- It facilitates the running PartiQL queries on Amazon S3 prefixes containing documents stored as JSON files.
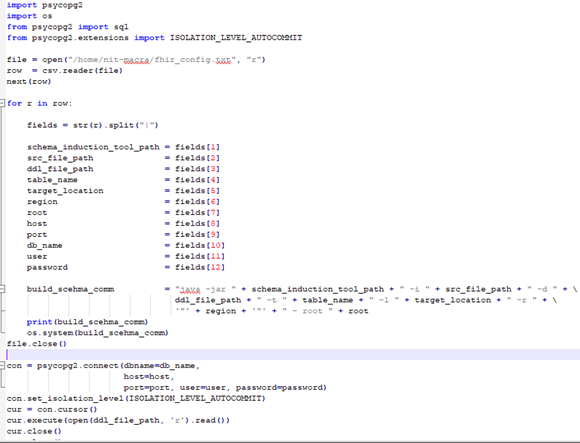
- Configuration driven Python wrapper leverages the schema induction tool to generate the external table structure on top of Json documents reside in S3 buckets
- Configuration file contains source file location, target location, redshift cluster details (host, port & credentials)
- Python wrapper gets the generated external table script and create the table by executing the DDL script on the redshift spectrum.
- Once the external table gets created, we can query on the data from any of the application using PartiQL.

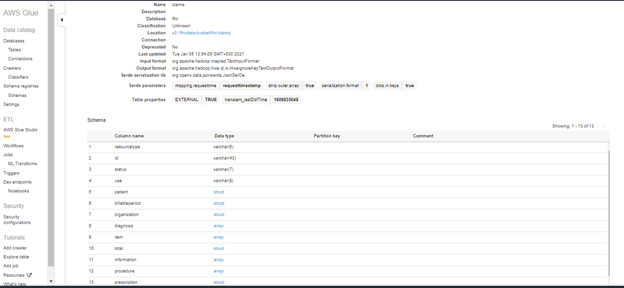
- Creating External Table
We developed custom python-based wrapper, which reads the configuration file get the details of input file location, target DDL file location, table name and redshift cluster details. Fig. Configuration file

- Querying External Table
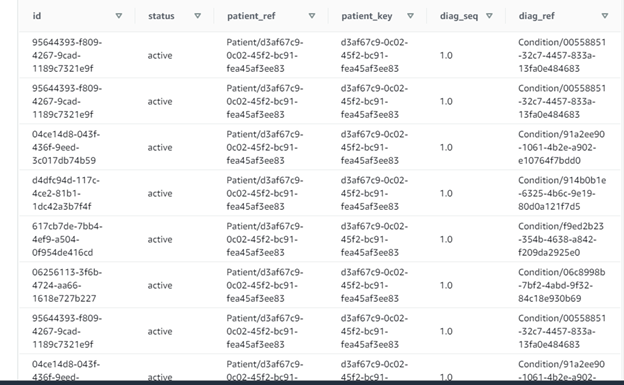
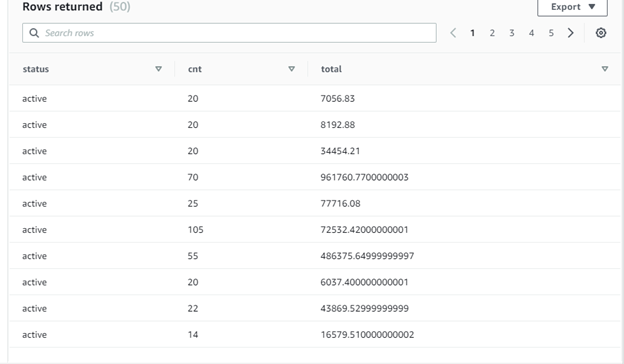
Now you can query the claims data stored in fhir format using PartiQL Queries and this native SQL approach to unnest the array is one of the corner stones of the PartiQL. The query also uses the dot notation to access attributes in nested structures, such as c.patient.reference, which accesses the reference attribute inside the patient structure that is in the claim document. The following query scans all documents in the users. Claims table and retrieves information from each claim. SELECT c.id,c.status, c.patient.reference as patient_ref, SPLIT_PART(c.patient.reference,’/’,2) as patient_key, d.sequence as diag_seq, d.diagnosisReference.reference as diag_ref FROM fhir.Claims as c, c.diagnosis as d WHERE c.status = ‘active’ The claim.diagnosis is an array that might contain multiple objects; it is therefore referenced in the SQL from clause and joined with the parent document implicitly, then attributes from the diagnosis element can be retrieved in the SELECT clause.