
A Breakthrough in Accessing Knowledge
In today’s digital age, text serves as a vast repository of knowledge. However, extracting relevant information from unstructured text can be a complex and time-consuming process.
This stands in stark contrast to structured knowledge bases like Freebase and Wikipedia Data. These offer easier access to information but require meticulous organization.
The quest for a seamless way to ask questions and receive accurate answers has been a long-standing endeavor.
Enter generative artificial intelligence! This has given rise to sophisticated Question Answering (QA) systems and have revolutionized the way we interact with information.
Challenges in Extracting Answers from Unstructured Knowledge
Traditional Information Retrieval (IR) systems focused on selecting relevant documents from storage systems. This was based on search queries.
However, QA systems take this a step further by not only retrieving documents but also extracting specific answers from them.
This has given birth to new breeds of QA systems such as:
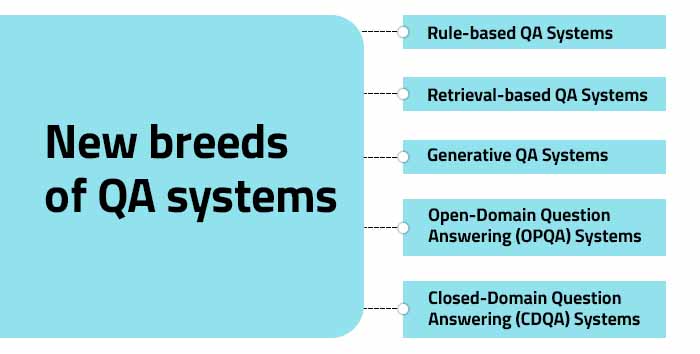
Fig 1: New breeds of QA systems
Rule-based QA Systems: Rule-based systems rely on predefined rules and patterns human experts create. This is to extract answers from text. They match specific keywords or phrases and are effective for simple and straightforward questions. But they struggle with complex queries or ambiguous information.
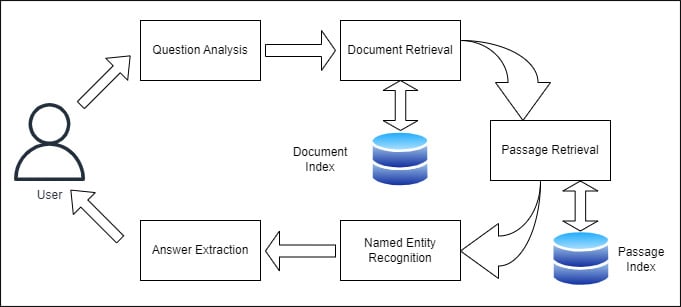
Fig 2: Rule-based QA System
Retrieval-based QA Systems: Retrieval-based systems retrieve answers from a predefined set of documents or knowledge sources. They use information retrieval techniques to identify relevant passages or documents containing the answer. These systems can handle a wide range of questions. But they are limited to the information available in the predefined knowledge base.
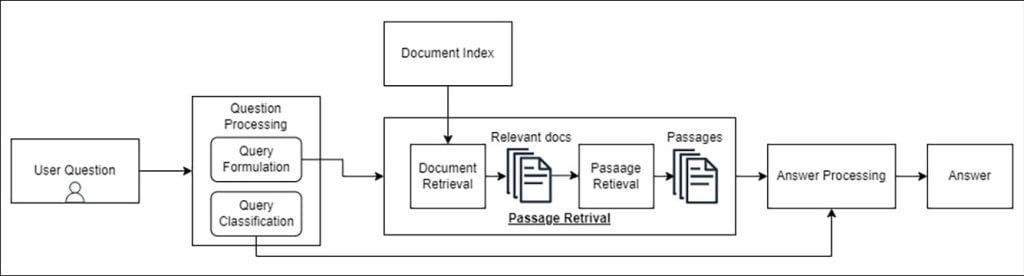
Fig 3: Retrieval-based QA System
Generative QA Systems: Generative systems generate answers by synthesizing information from various sources. They can go beyond explicit information in documents and produce human-like responses. Generative systems leverage techniques such as natural language generation and language models. This is to provide coherent and contextually appropriate answers. They are capable of handling complex and open-ended questions.
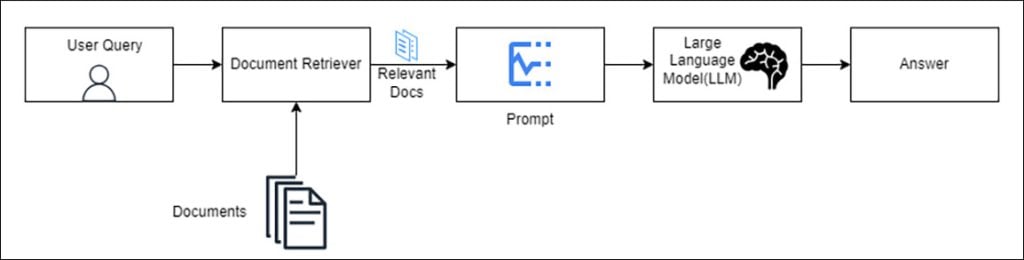
Fig 4: Generative QA System
Open-Domain Question Answering (OPQA) Systems: OPQA systems are designed to answer questions across various domains. They can:
- Recall answers seen during training
- Handle novel questions based on training data
- Tackle questions with answers beyond their training scope
OPQA systems leverage pre-trained models as their knowledge base. This allows them to provide context-based answers to a wide range of questions.
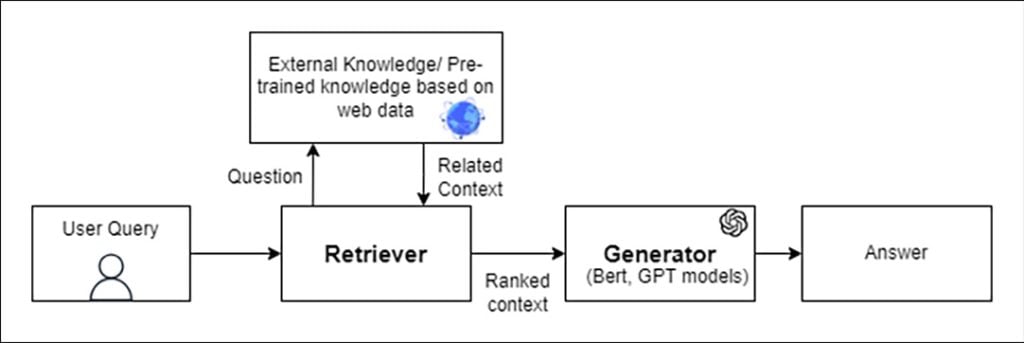
Fig 5: Open-Domain Question Answering (OPQA) System
Closed-Domain Question Answering (CDQA) Systems: CDQA systems focus on answering questions within specific domain documents. Examples are tech-support, healthcare, and engineering. They provide a focused approach to question answering. They do this by leveraging specialized knowledge within a specific domain. CDQA systems are trained on a specific domain’s dataset to learn the intricacies and nuances of the domain. This enables them to provide precise answers within that domain.

Fig 6: Closed-Domain Question Answering (CDQA) System
Answer Extraction
A QA system retrieves relevant documents. Now the next challenge lies in extracting answers from them. Several approaches have been developed for answer extraction. Two common approaches are:
1. Rule-based methods: These methods rely on predefined rules and patterns. This is to extract answers from the retrieved documents. They often involve matching specific keywords or phrases.
2. Named Entity Recognition (NER): NER techniques identify and classify named entities in the text. Examples are names of people, organizations, and locations. By recognizing these entities, you can extract answers based on their relevance to the question.
3. Cosine Similarity: Cosine similarity measures the angle between two vectors to determine their similarity. Higher cosine similarity indicates greater relevance in answer extraction for ranking and retrieving suitable answers.
4. Dot-Product: Dot-product calculates the element-wise product of vectors. Higher dot-product values suggest higher similarity in answer extraction. This aids in ranking and selecting relevant answers in Q&A systems.
QA systems can be categorized into two main variants: extractive and abstractive.
- Extractive QA: Extractive QA systems retrieve answers from the given documents. They do this without modifying the original text. These systems identify and extract the most relevant sentences or phrases from the documents that directly answer the question.
- Abstractive QA: Abstractive QA systems generate answers by synthesizing information from multiple sources. They create new sentences that convey the required information. These systems go beyond extracting existing text and generating human-like responses.
Traditional QA Systems vs. OpenAI-Powered QA Systems
Traditional QA systems relied on predefined rules and patterns. This limits their ability to handle complex and diverse questions.
In contrast, OpenAI-powered QA systems, such as those based on the GPT-3.5 architecture, leverage deep learning techniques. They do this to provide more accurate and contextually rich answers. It all boils down to how AI answers questions!
LLM-Based QA (Large Language Model-Based QA):
LLM-Based QA refers to Question Answering systems that utilize large language models, such as OpenAI’s GPT-3.5, text-davinci,etc, to generate answers. These models are trained on massive amounts of text data and possess a deep understanding of language and context. LLM-Based QA systems can handle a wide range of questions and provide coherent and contextually appropriate answers.
Flow Diagram of LLM-Based QA
Here is a simplified flow diagram of how LLM-Based QA systems work:
1. Input Question: The user provides a question or query to the system.
2. Context Retriever: The system retrieves relevant documents or passages from its knowledge base that are likely to contain the answer.
3. Passage Encoding: The retrieved passages are encoded into a numerical representation that captures their meaning and context. This encoding is often done using techniques like word embeddings or transformer models.
4. Question Encoding: The question is also encoded into a numerical representation that captures its meaning and context.
5. Similarity Calculation: The system calculates the similarity between the encoded question and each encoded passage to determine their relevance to the question.
6. Answer Extraction: The system selects the passage with the highest similarity score as the most likely source of the answer. It then extracts the answer based on the identified passage.
7. Answer Generation: In some cases, the answer may require further processing or transformation. LLM-Based QA systems can generate a human-like answer by synthesizing information from the retrieved passage or by generating new text based on the context.
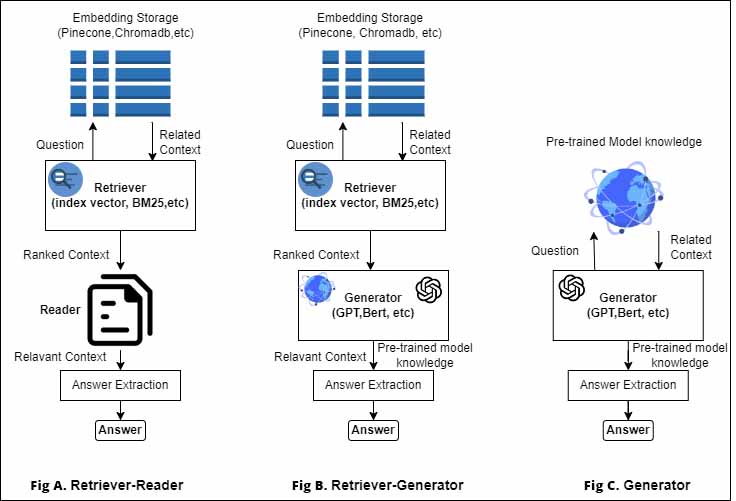
Fig 7: Flow diagram of how LLM-Based QA systems work
Fig.1A: The most fundamental behavior is the ability to consistently recall the answer to a question based on the document embeddings kept in a vector database. (CDQA)
Fig.2B: A model should be able to answer innovative questions based on the document embeddings and the model’s knowledge-based data; in this case, the model uses its own knowledge to add-on the context to generate an answer.
Fig.3C: A strong system should be capable of answering unique queries based purely on the web or pre-trained model data. (OPQA)
Example Code for LLM-Based QA:
Here is an example code snippet using OpenAI’s GPT-3.5 model for Question Answering:
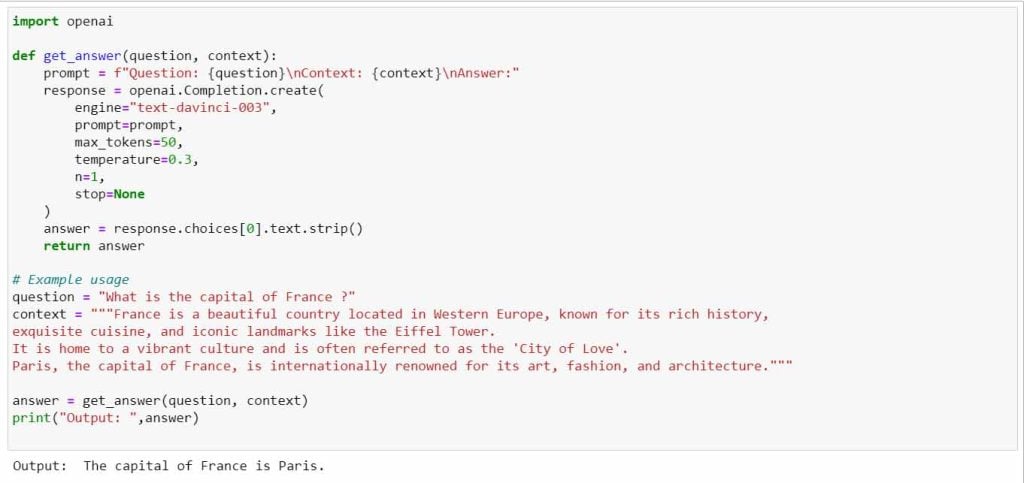
Fig 8: Example Code for LLM-Based QA
Evaluation of LLM-Based QA Systems:
Various evaluation metrics are used to measure the performance of LLM-Based QA systems. Some common metrics include:
- ROUGE Score: It measures summary quality using precision, recall, and F1 score. Precision is correct n-grams in the generated summary, recall is correct n-grams in the reference summary, and F1 is their harmonic mean.
- BERT Score: It calculates text similarity with precision, recall, and F1 score. Precision is agreement between word embeddings, recall captures important semantics, and F1 is their harmonic mean.
- BLEU Score: It evaluates translation quality using precision, recall, and F1 score. Precision is correct n-grams in the generated translation, recall is correct n-grams in the reference translation, and F1 is their harmonic mean.
Benefits and Applications of QA Systems
CDQA systems, including LLM-Based QA systems, have a wide range of benefits and applications. They can:
1. Assist in legal research:
This is by providing quick access to relevant tech-support queries, healthcare plans, and legal precedents.
2. Aid in medical diagnosis:
This is by offering insights into medical conditions and treatment options. It also entails providing detailed information to healthcare professionals.
3. Support engineering and technical domains:
This is by assisting with troubleshooting, providing information on technical solutions, maintenance procedures, and more.
4. Streamline information retrieval within specific domains:
This saves valuable time and effort for professionals in their respective fields.
5. Enhance decision-making processes:
This is by providing accurate and targeted answers. These are based on domain-specific knowledge.
The Future of QA Systems
Open-domain and closed-domain Question Answering systems, including LLM-Based QA systems, have made significant advancements in the field of Natural Language Processing (NLP). With ongoing research and advancements, we can expect further breakthroughs that will enhance the efficiency and accuracy of QA systems. These systems will continue to reshape the way we engage with knowledge in the digital age.
Well, I must wrap up my thoughts…
Question Answering systems, powered by large language models, have revolutionized the way we access knowledge. These systems handle unstructured text and provide accurate answers across diverse domains. They have unlocked the power of human-like interaction with information!
QA systems have become indispensable tools in various fields, with:
- Variants like extractive and abstractive QA
- Advancements in LLM-Based QA
- The integration of efficient evaluation metrics
CDQA systems provide a focused approach to answering questions within specific domains. They offer precise and domain-specific information.
As research progresses, we can expect further improvements and applications for QA systems. Those will propel us into a new era of information retrieval and knowledge access!

Explore how we cater to our customers through GenAI technology.
Well, we’re witnessing the future of AI turning into the present! Mail us with your thoughts about the blog you just read. Also visit us at Nitor Infotech to learn about our penchant for AI technology!



