
AWS Glue is a powerful tool that is managed, relieving you of the hassle associated with maintaining the infrastructure. It is hosted by AWS and offers Glue as Serverless ETL, which converts the code into Python/Scala and execute it in Spark environment.
AWS Glue provisions all the required resources (Spark cluster) at runtime to execute the Spark Job which it takes ~7-10 mins and then starts executing your actual ETL code. To reduce this time AWS Glues provides Development endpoint, which can be configured in Apache Zeppelin (provisioned with the spark environment) to interactively, run, debug and test ETL code before deploying as Glue job or scheduling the ETL process.
In order to successfully set up the Dev Endpoint on AWS Glue, first let us understand some of its prerequisites:
- An IAM Role for the Glue Dev Endpoint with the necessary policies. E.g.: AWSGlueServiceRole
- Table in Glue Data Catalog and the necessary connection
- I am assuming that you know your way around VPC networking, security groups, etc., E.g.: The Dev Endpoint requires a security group that allows the port 22, since we need that for the SSH tunneling.
Further, we can move on to the process involved in setting up the Dev Endpoint on AWS Glue. Here’s how it goes:
- Create an SSL Key Pair
- You can create it using PuTTyGen tool or you can create it under AWS EC2 -> Network & Security -> Key Pairs
- You need the Public Key which should look like:

- You will need the Private Key in .ppk format. If you’re using PuTTYgen, you will get it in the .ppk format whereas in case of EC2 you will get the file in .pem format and you will have to convert it into .ppk using the PuTTygen conversion tool.
- Make sure that the file has permissions of 400 or 600 – in case of Linux whereas in case of windows follow the below steps:
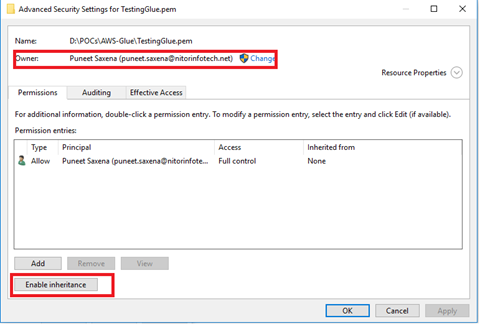
- Right click on PEM file > Properties > Security > Advanced.
- Make sure that you are the owner of the file and have disabled the inheritance (once you have disabled it, it will look like below screenshot)
- Spin up the AWS Glue Dev Endpoints:
- Create it by going to AWS Glue -> Dev endpoints -> Add endpoint and you should see this:
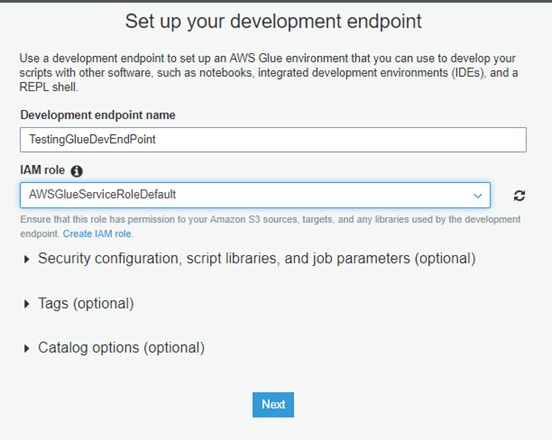
- In Development endpoint name: Give it any name; IAM Role: Select the role which you’ve created; and Click Next.
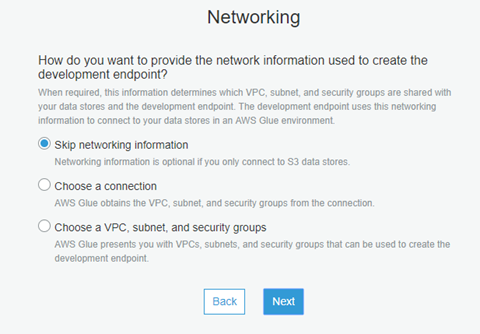
- Choose “Skip Networking Information” if you have S3 data stores, otherwise you can select the rest two as per your instances or security groups. Click Next.
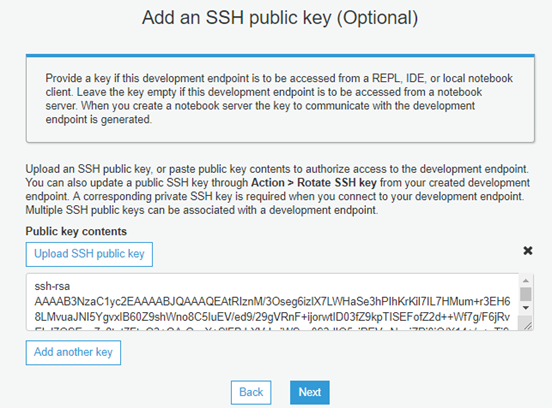
- Now from your key pair values, paste the Public Key here as shown below and click Next:
- Review the details and click on Finish:
- Now let the process run and wait until the Provisioning status shows a “READY” State.

- SSH tunnel for Glue Dev Endpoint: When your dev endpoint is provisioned, check that its network interface has a public address attached to it and make note of it (e.g., ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com).
a. Create SSH tunnel using PuTTY:

b. Using SSH:

- Zeppelin Notebook:
- Download the Zeppelin Notebook 0.7.3 version.
- Unzip the file and copy the folder under C: Drive.
- Go to localhost:8080
- On the top-right corner, click anonymous > interpreter > Search for spark > edit
- Have Connect to existing process checked
- Set host to localhost and port to 9007
- Under properties, set master to yarn-client
- Remove executor.memory and spark.driver.memory properties if they exist.
- Save, Ok.
- Write your first Glue program:
- Under Notebook, create Notebook > select Spark Interpreter
- Try your program and execute it.
And with that, your AWS Glue is up and running. Obviously this was just scratching the surface. There is a lot more to learn but I’ll cover those in another blog.
Reach out to us at Nitor Infotech to learn more about how you can deploy AWS Glue to simplify your ETL work, and if you’re in the mood for some light reading, you can take a look at a blog that I had penned down about AWS Redshift PartiQL.



